 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFormer: Accelerating Large Language Models with Optimized Transformers on Gaudi Processors
Dec 19, 2024



Heterogeneous hardware like Gaudi processor has been developed to enhance computations, especially matrix operations for Transformer-based large language models (LLMs) for generative AI tasks. However, our analysis indicates that Transformers are not fully optimized on such emerging hardware, primarily due to inadequate optimizations in non-matrix computational kernels like Softmax and in heterogeneous resource utilization, particularly when processing long sequences. To address these issues, we propose an integrated approach (called GFormer) that merges sparse and linear attention mechanisms. GFormer aims to maximize the computational capabilities of the Gaudi processor's Matrix Multiplication Engine (MME) and Tensor Processing Cores (TPC) without compromising model quality. GFormer includes a windowed self-attention kernel and an efficient outer product kernel for causal linear attention, aiming to optimize LLM inference on Gaudi processors. Evaluation shows that GFormer significantly improves efficiency and model performance across various tasks on the Gaudi processor and outperforms state-of-the-art GPUs.
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training
Oct 20, 2024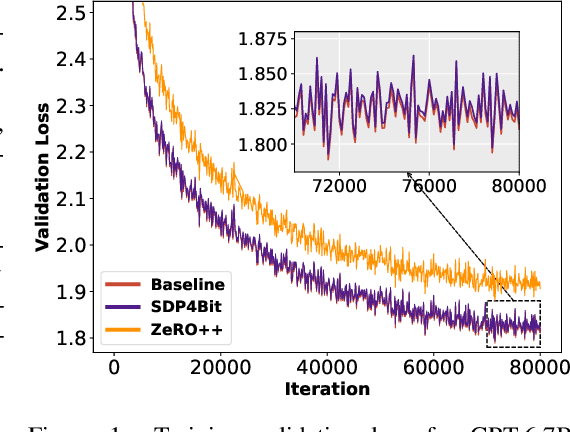
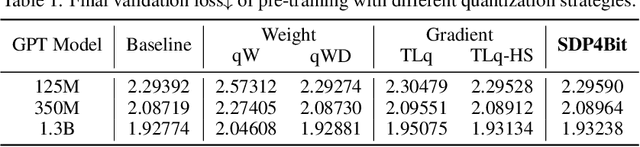
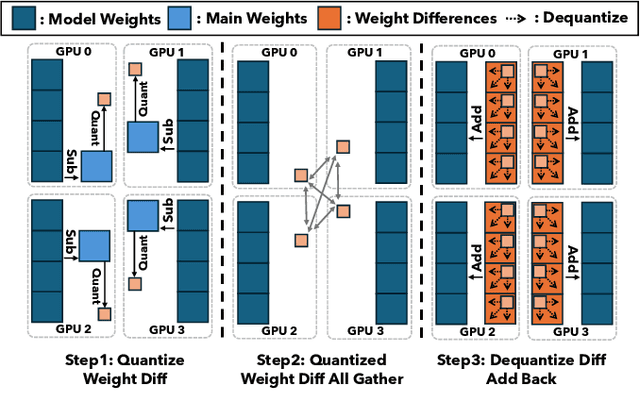
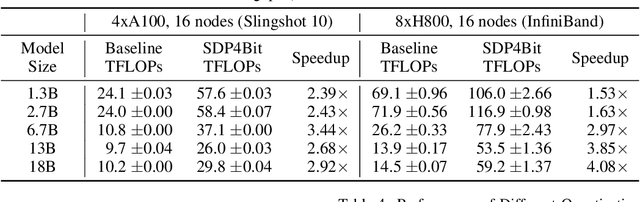
Recent years have witnessed a clear trend towards language models with an ever-increasing number of parameters, as well as the growing training overhead and memory usage. Distributed training, particularly through Sharded Data Parallelism (ShardedDP) which partitions optimizer states among workers, has emerged as a crucial technique to mitigate training time and memory usage. Yet, a major challenge in the scalability of ShardedDP is the intensive communication of weights and gradients. While compression techniques can alleviate this issue, they often result in worse accuracy. Driven by this limitation, we propose SDP4Bit (Toward 4Bit Communication Quantization in Sharded Data Parallelism for LLM Training), which effectively reduces the communication of weights and gradients to nearly 4 bits via two novel techniques: quantization on weight differences, and two-level gradient smooth quantization. Furthermore, SDP4Bit presents an algorithm-system co-design with runtime optimization to minimize the computation overhead of compression. In addition to the theoretical guarantees of convergence, we empirically evaluate the accuracy of SDP4Bit on the pre-training of GPT models with up to 6.7 billion parameters, and the results demonstrate a negligible impact on training loss. Furthermore, speed experiments show that SDP4Bit achieves up to 4.08$\times$ speedup in end-to-end throughput on a scale of 128 GPUs.
Accelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
Jul 05, 2024DLRM is a state-of-the-art recommendation system model that has gained widespread adoption across various industry applications. The large size of DLRM models, however, necessitates the use of multiple devices/GPUs for efficient training. A significant bottleneck in this process is the time-consuming all-to-all communication required to collect embedding data from all devices. To mitigate this, we introduce a method that employs error-bounded lossy compression to reduce the communication data size and accelerate DLRM training. We develop a novel error-bounded lossy compression algorithm, informed by an in-depth analysis of embedding data features, to achieve high compression ratios. Moreover, we introduce a dual-level adaptive strategy for error-bound adjustment, spanning both table-wise and iteration-wise aspects, to balance the compression benefits with the potential impacts on accuracy. We further optimize our compressor for PyTorch tensors on GPUs, minimizing compression overhead. Evaluation shows that our method achieves a 1.38$\times$ training speedup with a minimal accuracy impact.
FastCLIP: A Suite of Optimization Techniques to Accelerate CLIP Training with Limited Resources
Jul 01, 2024

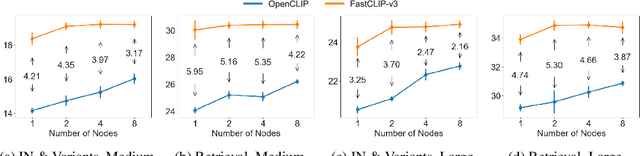
Existing studies of training state-of-the-art Contrastive Language-Image Pretraining (CLIP) models on large-scale data involve hundreds of or even thousands of GPUs due to the requirement of a large batch size. However, such a large amount of resources is not accessible to most people. While advanced compositional optimization techniques for optimizing global contrastive losses have been demonstrated effective for removing the requirement of large batch size, their performance on large-scale data remains underexplored and not optimized. To bridge the gap, this paper explores several aspects of CLIP training with limited resources (e.g., up to tens of GPUs). First, we introduce FastCLIP, a general CLIP training framework built on advanced compositional optimization techniques while designed and optimized for the distributed setting. Our framework is equipped with an efficient gradient reduction strategy to reduce communication overhead. Second, to further boost training efficiency, we investigate three components of the framework from an optimization perspective: the schedule of the inner learning rate, the update rules of the temperature parameter and the model parameters, respectively. Experiments on different strategies for each component shed light on how to conduct CLIP training more efficiently. Finally, we benchmark the performance of FastCLIP and the state-of-the-art training baseline (OpenCLIP) on different compute scales up to 32 GPUs on 8 nodes, and three data scales ranging from 2.7 million, 9.1 million to 315 million image-text pairs to demonstrate the significant improvement of FastCLIP in the resource-limited setting. We release the code of FastCLIP at https://github.com/Optimization-AI/fast_clip .
GWLZ: A Group-wise Learning-based Lossy Compression Framework for Scientific Data
Apr 20, 2024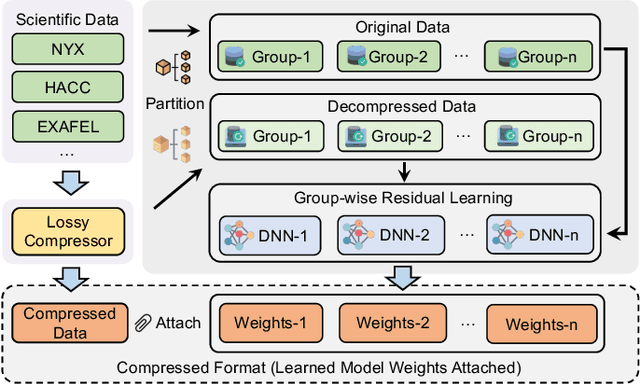

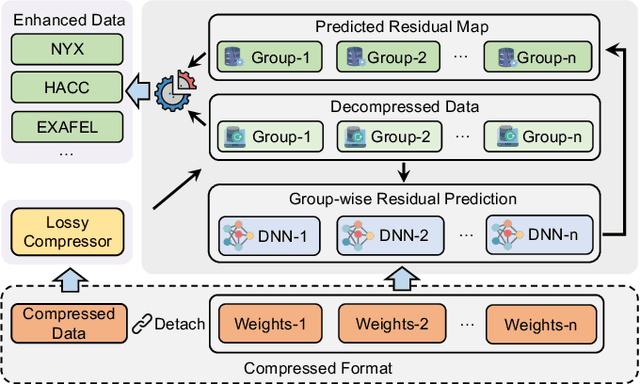
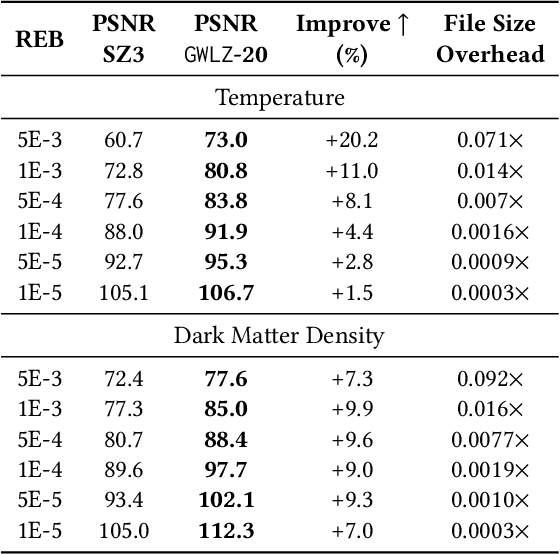
The rapid expansion of computational capabilities and the ever-growing scale of modern HPC systems present formidable challenges in managing exascale scientific data. Faced with such vast datasets, traditional lossless compression techniques prove insufficient in reducing data size to a manageable level while preserving all information intact. In response, researchers have turned to error-bounded lossy compression methods, which offer a balance between data size reduction and information retention. However, despite their utility, these compressors employing conventional techniques struggle with limited reconstruction quality. To address this issue, we draw inspiration from recent advancements in deep learning and propose GWLZ, a novel group-wise learning-based lossy compression framework with multiple lightweight learnable enhancer models. Leveraging a group of neural networks, GWLZ significantly enhances the decompressed data reconstruction quality with negligible impact on the compression efficiency. Experimental results on different fields from the Nyx dataset demonstrate remarkable improvements by GWLZ, achieving up to 20% quality enhancements with negligible overhead as low as 0.0003x.
Benchmarking and In-depth Performance Study of Large Language Models on Habana Gaudi Processors
Sep 29, 2023

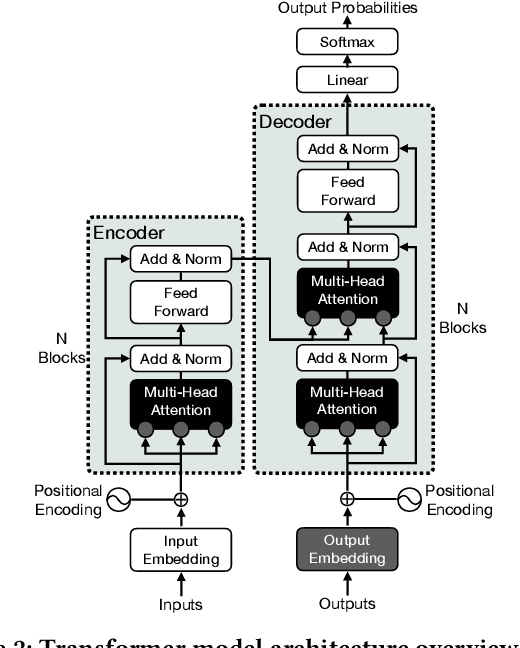

Transformer models have achieved remarkable success in various machine learning tasks but suffer from high computational complexity and resource requirements. The quadratic complexity of the self-attention mechanism further exacerbates these challenges when dealing with long sequences and large datasets. Specialized AI hardware accelerators, such as the Habana GAUDI architecture, offer a promising solution to tackle these issues. GAUDI features a Matrix Multiplication Engine (MME) and a cluster of fully programmable Tensor Processing Cores (TPC). This paper explores the untapped potential of using GAUDI processors to accelerate Transformer-based models, addressing key challenges in the process. Firstly, we provide a comprehensive performance comparison between the MME and TPC components, illuminating their relative strengths and weaknesses. Secondly, we explore strategies to optimize MME and TPC utilization, offering practical insights to enhance computational efficiency. Thirdly, we evaluate the performance of Transformers on GAUDI, particularly in handling long sequences and uncovering performance bottlenecks. Lastly, we evaluate the end-to-end performance of two Transformer-based large language models (LLM) on GAUDI. The contributions of this work encompass practical insights for practitioners and researchers alike. We delve into GAUDI's capabilities for Transformers through systematic profiling, analysis, and optimization exploration. Our study bridges a research gap and offers a roadmap for optimizing Transformer-based model training on the GAUDI architecture.
HEAT: A Highly Efficient and Affordable Training System for Collaborative Filtering Based Recommendation on CPUs
May 03, 2023



Collaborative filtering (CF) has been proven to be one of the most effective techniques for recommendation. Among all CF approaches, SimpleX is the state-of-the-art method that adopts a novel loss function and a proper number of negative samples. However, there is no work that optimizes SimpleX on multi-core CPUs, leading to limited performance. To this end, we perform an in-depth profiling and analysis of existing SimpleX implementations and identify their performance bottlenecks including (1) irregular memory accesses, (2) unnecessary memory copies, and (3) redundant computations. To address these issues, we propose an efficient CF training system (called HEAT) that fully enables the multi-level caching and multi-threading capabilities of modern CPUs. Specifically, the optimization of HEAT is threefold: (1) It tiles the embedding matrix to increase data locality and reduce cache misses (thus reduces read latency); (2) It optimizes stochastic gradient descent (SGD) with sampling by parallelizing vector products instead of matrix-matrix multiplications, in particular the similarity computation therein, to avoid memory copies for matrix data preparation; and (3) It aggressively reuses intermediate results from the forward phase in the backward phase to alleviate redundant computation. Evaluation on five widely used datasets with both x86- and ARM-architecture processors shows that HEAT achieves up to 45.2X speedup over existing CPU solution and 4.5X speedup and 7.9X cost reduction in Cloud over existing GPU solution with NVIDIA V100 GPU.
HALOC: Hardware-Aware Automatic Low-Rank Compression for Compact Neural Networks
Jan 20, 2023



Low-rank compression is an important model compression strategy for obtaining compact neural network models. In general, because the rank values directly determine the model complexity and model accuracy, proper selection of layer-wise rank is very critical and desired. To date, though many low-rank compression approaches, either selecting the ranks in a manual or automatic way, have been proposed, they suffer from costly manual trials or unsatisfied compression performance. In addition, all of the existing works are not designed in a hardware-aware way, limiting the practical performance of the compressed models on real-world hardware platforms. To address these challenges, in this paper we propose HALOC, a hardware-aware automatic low-rank compression framework. By interpreting automatic rank selection from an architecture search perspective, we develop an end-to-end solution to determine the suitable layer-wise ranks in a differentiable and hardware-aware way. We further propose design principles and mitigation strategy to efficiently explore the rank space and reduce the potential interference problem. Experimental results on different datasets and hardware platforms demonstrate the effectiveness of our proposed approach. On CIFAR-10 dataset, HALOC enables 0.07% and 0.38% accuracy increase over the uncompressed ResNet-20 and VGG-16 models with 72.20% and 86.44% fewer FLOPs, respectively. On ImageNet dataset, HALOC achieves 0.9% higher top-1 accuracy than the original ResNet-18 model with 66.16% fewer FLOPs. HALOC also shows 0.66% higher top-1 accuracy increase than the state-of-the-art automatic low-rank compression solution with fewer computational and memory costs. In addition, HALOC demonstrates the practical speedups on different hardware platforms, verified by the measurement results on desktop GPU, embedded GPU and ASIC accelerator.
SOLAR: A Highly Optimized Data Loading Framework for Distributed Training of CNN-based Scientific Surrogates
Nov 04, 2022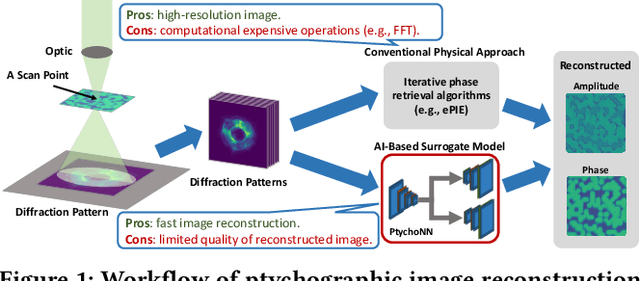
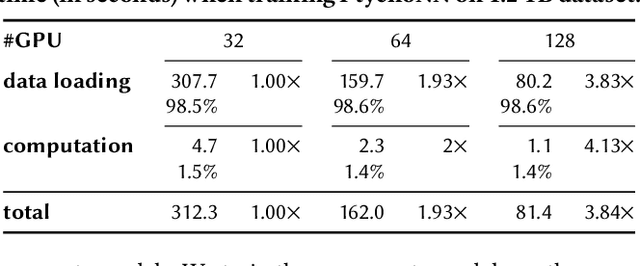
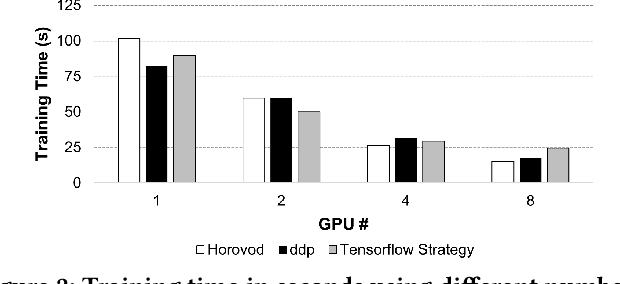

CNN-based surrogates have become prevalent in scientific applications to replace conventional time-consuming physical approaches. Although these surrogates can yield satisfactory results with significantly lower computation costs over small training datasets, our benchmarking results show that data-loading overhead becomes the major performance bottleneck when training surrogates with large datasets. In practice, surrogates are usually trained with high-resolution scientific data, which can easily reach the terabyte scale. Several state-of-the-art data loaders are proposed to improve the loading throughput in general CNN training; however, they are sub-optimal when applied to the surrogate training. In this work, we propose SOLAR, a surrogate data loader, that can ultimately increase loading throughput during the training. It leverages our three key observations during the benchmarking and contains three novel designs. Specifically, SOLAR first generates a pre-determined shuffled index list and accordingly optimizes the global access order and the buffer eviction scheme to maximize the data reuse and the buffer hit rate. It then proposes a tradeoff between lightweight computational imbalance and heavyweight loading workload imbalance to speed up the overall training. It finally optimizes its data access pattern with HDF5 to achieve a better parallel I/O throughput. Our evaluation with three scientific surrogates and 32 GPUs illustrates that SOLAR can achieve up to 24.4X speedup over PyTorch Data Loader and 3.52X speedup over state-of-the-art data loaders.
H-GCN: A Graph Convolutional Network Accelerator on Versal ACAP Architecture
Jun 28, 2022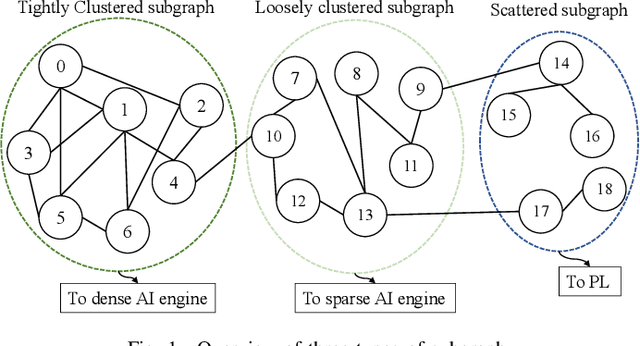
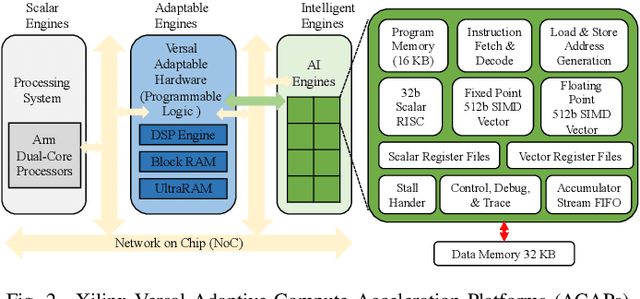
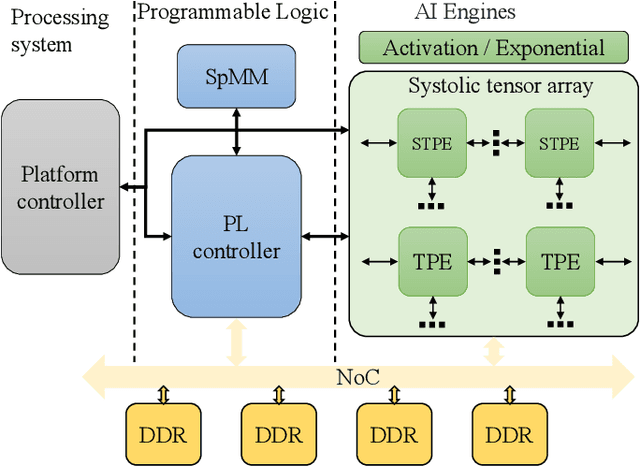
Graph Neural Networks (GNNs) have drawn tremendous attention due to their unique capability to extend Machine Learning (ML) approaches to applications broadly-defined as having unstructured data, especially graphs. Compared with other Machine Learning (ML) modalities, the acceleration of Graph Neural Networks (GNNs) is more challenging due to the irregularity and heterogeneity derived from graph typologies. Existing efforts, however, have focused mainly on handling graphs' irregularity and have not studied their heterogeneity. To this end we propose H-GCN, a PL (Programmable Logic) and AIE (AI Engine) based hybrid accelerator that leverages the emerging heterogeneity of Xilinx Versal Adaptive Compute Acceleration Platforms (ACAPs) to achieve high-performance GNN inference. In particular, H-GCN partitions each graph into three subgraphs based on its inherent heterogeneity, and processes them using PL and AIE, respectively. To further improve performance, we explore the sparsity support of AIE and develop an efficient density-aware method to automatically map tiles of sparse matrix-matrix multiplication (SpMM) onto the systolic tensor array. Compared with state-of-the-art GCN accelerators, H-GCN achieves, on average, speedups of 1.1~2.3X.