 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometry-Aware Efficient Algorithm for Compositional Entropic Risk Minimization
Feb 02, 2026This paper studies optimization for a family of problems termed $\textbf{compositional entropic risk minimization}$, in which each data's loss is formulated as a Log-Expectation-Exponential (Log-E-Exp) function. The Log-E-Exp formulation serves as an abstraction of the Log-Sum-Exponential (LogSumExp) function when the explicit summation inside the logarithm is taken over a gigantic number of items and is therefore expensive to evaluate. While entropic risk objectives of this form arise in many machine learning problems, existing optimization algorithms suffer from several fundamental limitations including non-convergence, numerical instability, and slow convergence rates. To address these limitations, we propose a geometry-aware stochastic algorithm, termed $\textbf{SCENT}$, for the dual formulation of entropic risk minimization cast as a min--min optimization problem. The key to our design is a $\textbf{stochastic proximal mirror descent (SPMD)}$ update for the dual variable, equipped with a Bregman divergence induced by a negative exponential function that faithfully captures the geometry of the objective. Our main contributions are threefold: (i) we establish an $O(1/\sqrt{T})$ convergence rate of the proposed SCENT algorithm for convex problems; (ii) we theoretically characterize the advantages of SPMD over standard SGD update for optimizing the dual variable; and (iii) we demonstrate the empirical effectiveness of SCENT on extreme classification, partial AUC maximization, contrastive learning and distributionally robust optimization, where it consistently outperforms existing baselines.
Breaking the Limits of Open-Weight CLIP: An Optimization Framework for Self-supervised Fine-tuning of CLIP
Jan 14, 2026CLIP has become a cornerstone of multimodal representation learning, yet improving its performance typically requires a prohibitively costly process of training from scratch on billions of samples. We ask a different question: Can we improve the performance of open-weight CLIP models across various downstream tasks using only existing self-supervised datasets? Unlike supervised fine-tuning, which adapts a pretrained model to a single downstream task, our setting seeks to improve general performance across various tasks. However, as both our experiments and prior studies reveal, simply applying standard training protocols starting from an open-weight CLIP model often fails, leading to performance degradation. In this paper, we introduce TuneCLIP, a self-supervised fine-tuning framework that overcomes the performance degradation. TuneCLIP has two key components: (1) a warm-up stage of recovering optimization statistics to reduce cold-start bias, inspired by theoretical analysis, and (2) a fine-tuning stage of optimizing a new contrastive loss to mitigate the penalization on false negative pairs. Our extensive experiments show that TuneCLIP consistently improves performance across model architectures and scales. Notably, it elevates leading open-weight models like SigLIP (ViT-B/16), achieving gains of up to +2.5% on ImageNet and related out-of-distribution benchmarks, and +1.2% on the highly competitive DataComp benchmark, setting a new strong baseline for efficient post-pretraining adaptation.
NeuCLIP: Efficient Large-Scale CLIP Training with Neural Normalizer Optimization
Nov 11, 2025Accurately estimating the normalization term (also known as the partition function) in the contrastive loss is a central challenge for training Contrastive Language-Image Pre-training (CLIP) models. Conventional methods rely on large batches for approximation, demanding substantial computational resources. To mitigate this issue, prior works introduced per-sample normalizer estimators, which are updated at each epoch in a blockwise coordinate manner to keep track of updated encoders. However, this scheme incurs optimization error that scales with the ratio of dataset size to batch size, limiting effectiveness for large datasets or small batches. To overcome this limitation, we propose NeuCLIP, a novel and elegant optimization framework based on two key ideas: (i) $\textbf{reformulating}$ the contrastive loss for each sample $\textbf{via convex analysis}$ into a minimization problem with an auxiliary variable representing its log-normalizer; and (ii) $\textbf{transforming}$ the resulting minimization over $n$ auxiliary variables (where $n$ is the dataset size) via $\textbf{variational analysis}$ into the minimization over a compact neural network that predicts the log-normalizers. We design an alternating optimization algorithm that jointly trains the CLIP model and the auxiliary network. By employing a tailored architecture and acceleration techniques for the auxiliary network, NeuCLIP achieves more accurate normalizer estimation, leading to improved performance compared with previous methods. Extensive experiments on large-scale CLIP training, spanning datasets from millions to billions of samples, demonstrate that NeuCLIP outperforms previous methods.
Model Steering: Learning with a Reference Model Improves Generalization Bounds and Scaling Laws
May 13, 2025This paper formalizes an emerging learning paradigm that uses a trained model as a reference to guide and enhance the training of a target model through strategic data selection or weighting, named $\textbf{model steering}$. While ad-hoc methods have been used in various contexts, including the training of large foundation models, its underlying principles remain insufficiently understood, leading to sub-optimal performance. In this work, we propose a theory-driven framework for model steering called $\textbf{DRRho risk minimization}$, which is rooted in Distributionally Robust Optimization (DRO). Through a generalization analysis, we provide theoretical insights into why this approach improves generalization and data efficiency compared to training without a reference model. To the best of our knowledge, this is the first time such theoretical insights are provided for the new learning paradigm, which significantly enhance our understanding and practice of model steering. Building on these insights and the connection between contrastive learning and DRO, we introduce a novel method for Contrastive Language-Image Pretraining (CLIP) with a reference model, termed DRRho-CLIP. Extensive experiments validate the theoretical insights, reveal a superior scaling law compared to CLIP without a reference model, and demonstrate its strength over existing heuristic approaches.
Obtaining Lower Query Complexities through Lightweight Zeroth-Order Proximal Gradient Algorithms
Oct 03, 2024Zeroth-order (ZO) optimization is one key technique for machine learning problems where gradient calculation is expensive or impossible. Several variance reduced ZO proximal algorithms have been proposed to speed up ZO optimization for non-smooth problems, and all of them opted for the coordinated ZO estimator against the random ZO estimator when approximating the true gradient, since the former is more accurate. While the random ZO estimator introduces bigger error and makes convergence analysis more challenging compared to coordinated ZO estimator, it requires only $\mathcal{O}(1)$ computation, which is significantly less than $\mathcal{O}(d)$ computation of the coordinated ZO estimator, with $d$ being dimension of the problem space. To take advantage of the computationally efficient nature of the random ZO estimator, we first propose a ZO objective decrease (ZOOD) property which can incorporate two different types of errors in the upper bound of convergence rate. Next, we propose two generic reduction frameworks for ZO optimization which can automatically derive the convergence results for convex and non-convex problems respectively, as long as the convergence rate for the inner solver satisfies the ZOOD property. With the application of two reduction frameworks on our proposed ZOR-ProxSVRG and ZOR-ProxSAGA, two variance reduced ZO proximal algorithms with fully random ZO estimators, we improve the state-of-the-art function query complexities from $\mathcal{O}\left(\min\{\frac{dn^{1/2}}{\epsilon^2}, \frac{d}{\epsilon^3}\}\right)$ to $\tilde{\mathcal{O}}\left(\frac{n+d}{\epsilon^2}\right)$ under $d > n^{\frac{1}{2}}$ for non-convex problems, and from $\mathcal{O}\left(\frac{d}{\epsilon^2}\right)$ to $\tilde{\mathcal{O}}\left(n\log\frac{1}{\epsilon}+\frac{d}{\epsilon}\right)$ for convex problems.
* Neural Computation 36 (5), 897-935
FastCLIP: A Suite of Optimization Techniques to Accelerate CLIP Training with Limited Resources
Jul 01, 2024
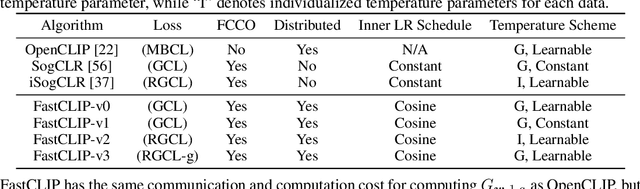

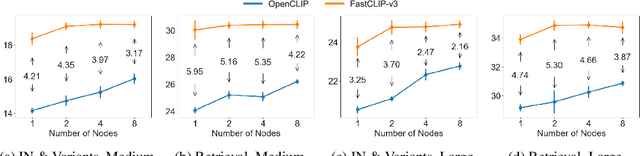
Existing studies of training state-of-the-art Contrastive Language-Image Pretraining (CLIP) models on large-scale data involve hundreds of or even thousands of GPUs due to the requirement of a large batch size. However, such a large amount of resources is not accessible to most people. While advanced compositional optimization techniques for optimizing global contrastive losses have been demonstrated effective for removing the requirement of large batch size, their performance on large-scale data remains underexplored and not optimized. To bridge the gap, this paper explores several aspects of CLIP training with limited resources (e.g., up to tens of GPUs). First, we introduce FastCLIP, a general CLIP training framework built on advanced compositional optimization techniques while designed and optimized for the distributed setting. Our framework is equipped with an efficient gradient reduction strategy to reduce communication overhead. Second, to further boost training efficiency, we investigate three components of the framework from an optimization perspective: the schedule of the inner learning rate, the update rules of the temperature parameter and the model parameters, respectively. Experiments on different strategies for each component shed light on how to conduct CLIP training more efficiently. Finally, we benchmark the performance of FastCLIP and the state-of-the-art training baseline (OpenCLIP) on different compute scales up to 32 GPUs on 8 nodes, and three data scales ranging from 2.7 million, 9.1 million to 315 million image-text pairs to demonstrate the significant improvement of FastCLIP in the resource-limited setting. We release the code of FastCLIP at https://github.com/Optimization-AI/fast_clip .
Stability and Generalization of Stochastic Compositional Gradient Descent Algorithms
Jul 07, 2023Many machine learning tasks can be formulated as a stochastic compositional optimization (SCO) problem such as reinforcement learning, AUC maximization, and meta-learning, where the objective function involves a nested composition associated with an expectation. While a significant amount of studies has been devoted to studying the convergence behavior of SCO algorithms, there is little work on understanding their generalization, i.e., how these learning algorithms built from training examples would behave on future test examples. In this paper, we provide the stability and generalization analysis of stochastic compositional gradient descent algorithms through the lens of algorithmic stability in the framework of statistical learning theory. Firstly, we introduce a stability concept called compositional uniform stability and establish its quantitative relation with generalization for SCO problems. Then, we establish the compositional uniform stability results for two popular stochastic compositional gradient descent algorithms, namely SCGD and SCSC. Finally, we derive dimension-independent excess risk bounds for SCGD and SCSC by trade-offing their stability results and optimization errors. To the best of our knowledge, these are the first-ever-known results on stability and generalization analysis of stochastic compositional gradient descent algorithms.
An Accelerated Variance-Reduced Conditional Gradient Sliding Algorithm for First-order and Zeroth-order Optimization
Sep 18, 2021



The conditional gradient algorithm (also known as the Frank-Wolfe algorithm) has recently regained popularity in the machine learning community due to its projection-free property to solve constrained problems. Although many variants of the conditional gradient algorithm have been proposed to improve performance, they depend on first-order information (gradient) to optimize. Naturally, these algorithms are unable to function properly in the field of increasingly popular zeroth-order optimization, where only zeroth-order information (function value) is available. To fill in this gap, we propose a novel Accelerated variance-Reduced Conditional gradient Sliding (ARCS) algorithm for finite-sum problems, which can use either first-order or zeroth-order information to optimize. To the best of our knowledge, ARCS is the first zeroth-order conditional gradient sliding type algorithms solving convex problems in zeroth-order optimization. In first-order optimization, the convergence results of ARCS substantially outperform previous algorithms in terms of the number of gradient query oracle. Finally we validated the superiority of ARCS by experiments on real-world datasets.