 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLAR: A Highly Optimized Data Loading Framework for Distributed Training of CNN-based Scientific Surrogates
Paper and Code
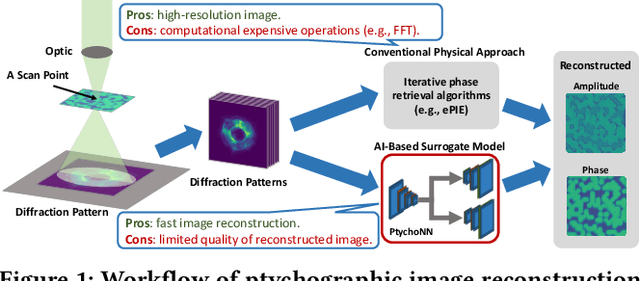
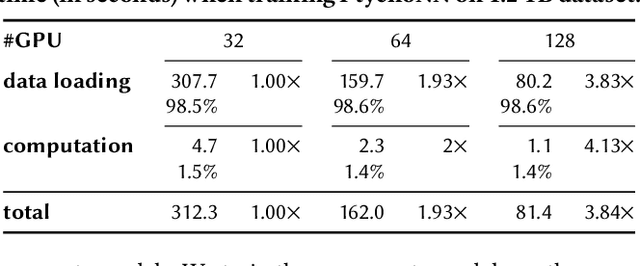
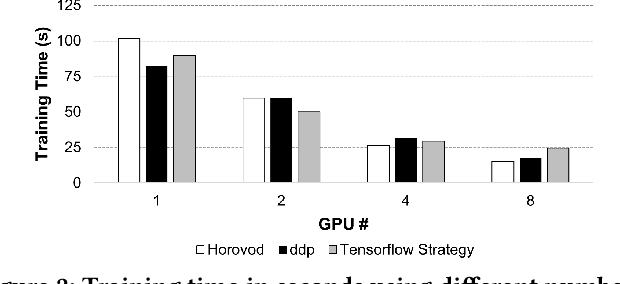

CNN-based surrogates have become prevalent in scientific applications to replace conventional time-consuming physical approaches. Although these surrogates can yield satisfactory results with significantly lower computation costs over small training datasets, our benchmarking results show that data-loading overhead becomes the major performance bottleneck when training surrogates with large datasets. In practice, surrogates are usually trained with high-resolution scientific data, which can easily reach the terabyte scale. Several state-of-the-art data loaders are proposed to improve the loading throughput in general CNN training; however, they are sub-optimal when applied to the surrogate training. In this work, we propose SOLAR, a surrogate data loader, that can ultimately increase loading throughput during the training. It leverages our three key observations during the benchmarking and contains three novel designs. Specifically, SOLAR first generates a pre-determined shuffled index list and accordingly optimizes the global access order and the buffer eviction scheme to maximize the data reuse and the buffer hit rate. It then proposes a tradeoff between lightweight computational imbalance and heavyweight loading workload imbalance to speed up the overall training. It finally optimizes its data access pattern with HDF5 to achieve a better parallel I/O throughput. Our evaluation with three scientific surrogates and 32 GPUs illustrates that SOLAR can achieve up to 24.4X speedup over PyTorch Data Loader and 3.52X speedup over state-of-the-art data loaders.