 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training
Paper and Code
Oct 20, 2024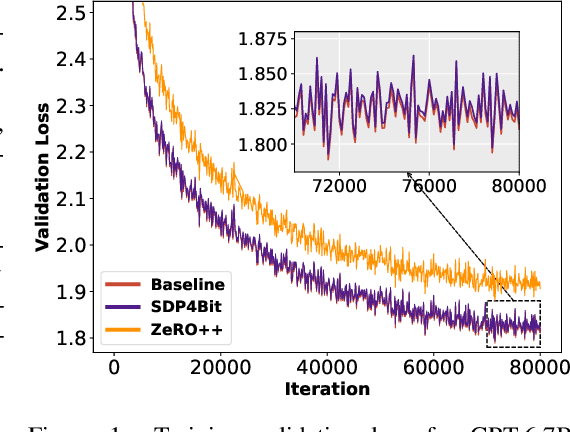
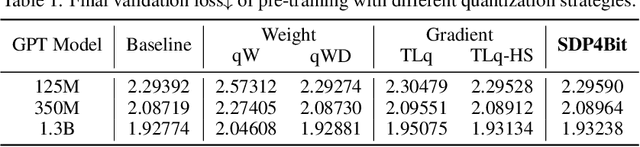
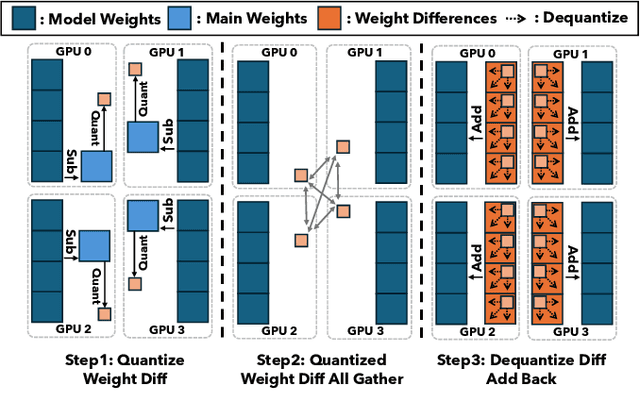
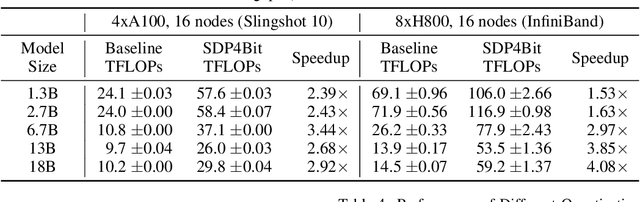
Recent years have witnessed a clear trend towards language models with an ever-increasing number of parameters, as well as the growing training overhead and memory usage. Distributed training, particularly through Sharded Data Parallelism (ShardedDP) which partitions optimizer states among workers, has emerged as a crucial technique to mitigate training time and memory usage. Yet, a major challenge in the scalability of ShardedDP is the intensive communication of weights and gradients. While compression techniques can alleviate this issue, they often result in worse accuracy. Driven by this limitation, we propose SDP4Bit (Toward 4Bit Communication Quantization in Sharded Data Parallelism for LLM Training), which effectively reduces the communication of weights and gradients to nearly 4 bits via two novel techniques: quantization on weight differences, and two-level gradient smooth quantization. Furthermore, SDP4Bit presents an algorithm-system co-design with runtime optimization to minimize the computation overhead of compression. In addition to the theoretical guarantees of convergence, we empirically evaluate the accuracy of SDP4Bit on the pre-training of GPT models with up to 6.7 billion parameters, and the results demonstrate a negligible impact on training loss. Furthermore, speed experiments show that SDP4Bit achieves up to 4.08$\times$ speedup in end-to-end throughput on a scale of 128 GPUs.