 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-GCN: A Graph Convolutional Network Accelerator on Versal ACAP Architecture
Jun 28, 2022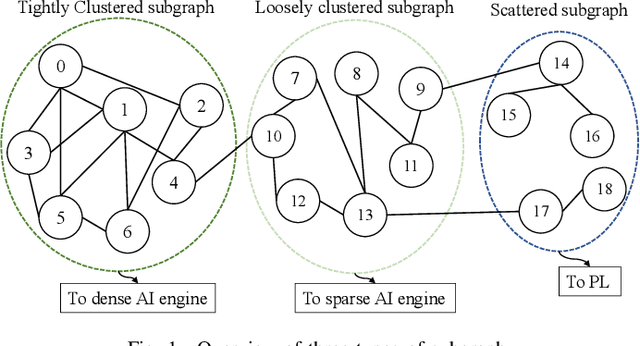
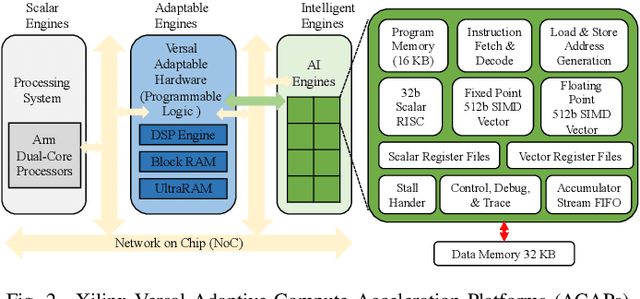
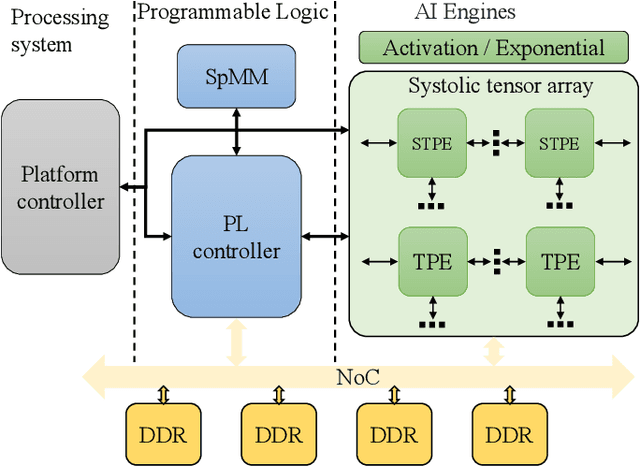
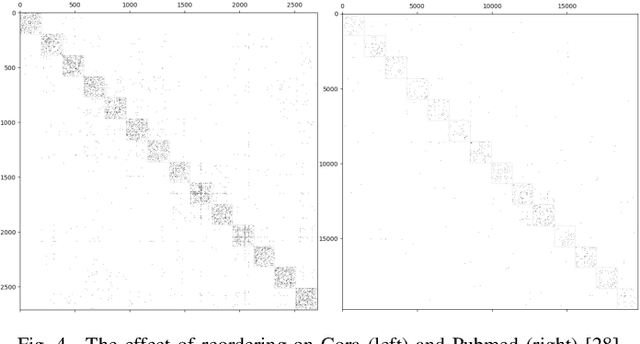
Graph Neural Networks (GNNs) have drawn tremendous attention due to their unique capability to extend Machine Learning (ML) approaches to applications broadly-defined as having unstructured data, especially graphs. Compared with other Machine Learning (ML) modalities, the acceleration of Graph Neural Networks (GNNs) is more challenging due to the irregularity and heterogeneity derived from graph typologies. Existing efforts, however, have focused mainly on handling graphs' irregularity and have not studied their heterogeneity. To this end we propose H-GCN, a PL (Programmable Logic) and AIE (AI Engine) based hybrid accelerator that leverages the emerging heterogeneity of Xilinx Versal Adaptive Compute Acceleration Platforms (ACAPs) to achieve high-performance GNN inference. In particular, H-GCN partitions each graph into three subgraphs based on its inherent heterogeneity, and processes them using PL and AIE, respectively. To further improve performance, we explore the sparsity support of AIE and develop an efficient density-aware method to automatically map tiles of sparse matrix-matrix multiplication (SpMM) onto the systolic tensor array. Compared with state-of-the-art GCN accelerators, H-GCN achieves, on average, speedups of 1.1~2.3X.
UWB-GCN: Hardware Acceleration of Graph-Convolution-Network through Runtime Workload Rebalancing
Aug 23, 2019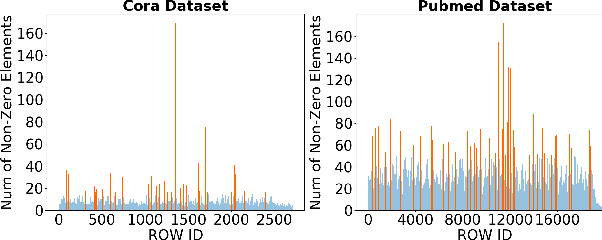
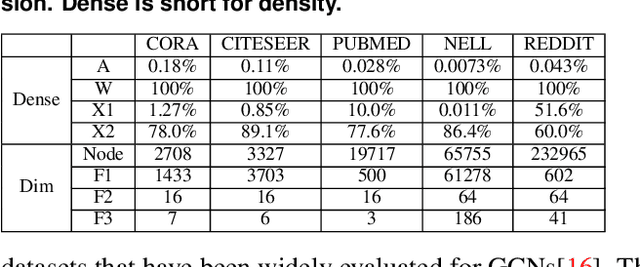
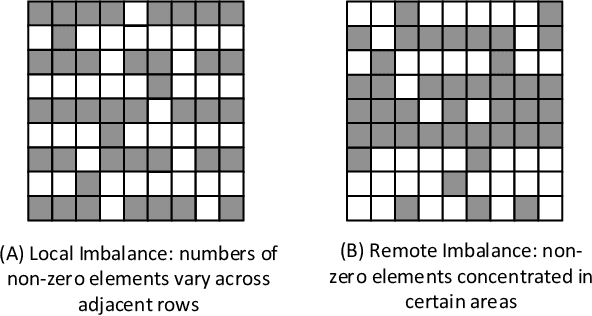
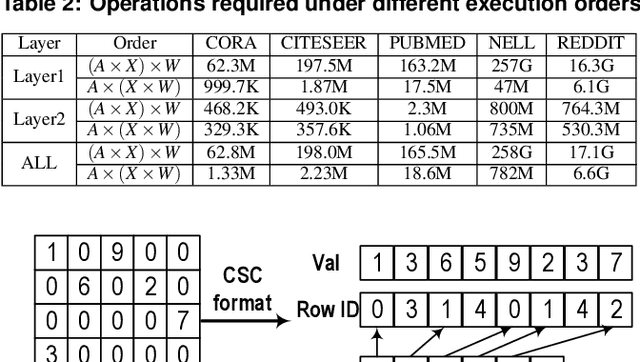
The recent development of deep learning has mostly been focusing on Euclidean data, such as images, videos, and audios. However, most real-world information and relationships are often expressed in graphs. Graph convolutional networks (GCNs) appear as a promising approach to efficiently learn from graph data structures, showing advantages in several practical applications such as social network analysis, knowledge discovery, 3D modeling, and motion capturing. However, practical graphs are often extremely large and unbalanced, posting significant performance demand and design challenges on the hardware dedicated to GCN inference. In this paper, we propose an architecture design called Ultra-Workload-Balanced-GCN (UWB-GCN) to accelerate graph convolutional network inference. To tackle the major performance bottleneck of workload imbalance, we propose two techniques: dynamic local sharing and dynamic remote switching, both of which rely on hardware flexibility to achieve performance auto-tuning with negligible area or delay overhead. Specifically, UWB-GCN is able to effectively profile the sparse graph pattern while continuously adjusting the workload distribution among parallel processing elements (PEs). After converging, the ideal configuration is reused for the remaining iterations. To the best of our knowledge, this is the first accelerator design targeted to GCNs and the first work that auto-tunes workload balance in accelerator at runtime through hardware, rather than software, approaches. Our methods can achieve near-ideal workload balance in processing sparse matrices. Experimental results show that UWB-GCN can finish the inference of the Nell graph (66K vertices, 266K edges) in 8.4ms, corresponding to 192x, 289x, and 7.3x respectively, compared to the CPU, GPU, and the baseline GCN design without workload rebalancing.
A Scalable Framework for Acceleration of CNN Training on Deeply-Pipelined FPGA Clusters with Weight and Workload Balancing
Jan 04, 2019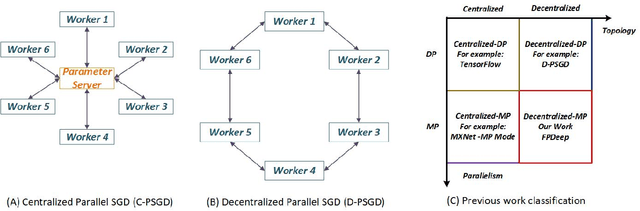
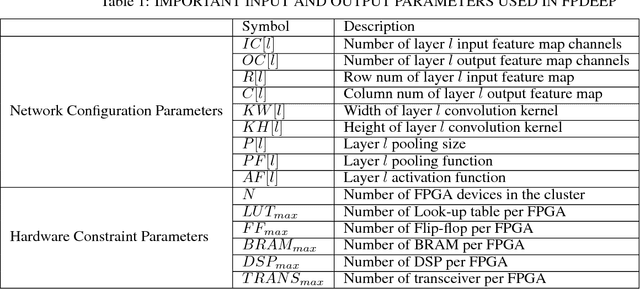
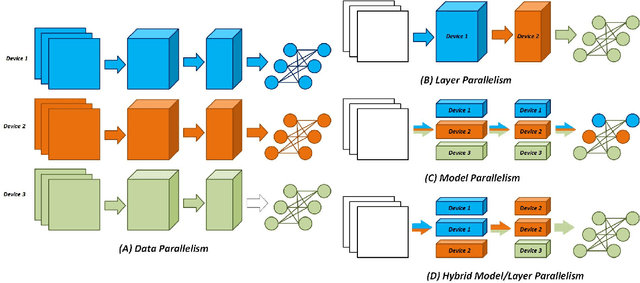
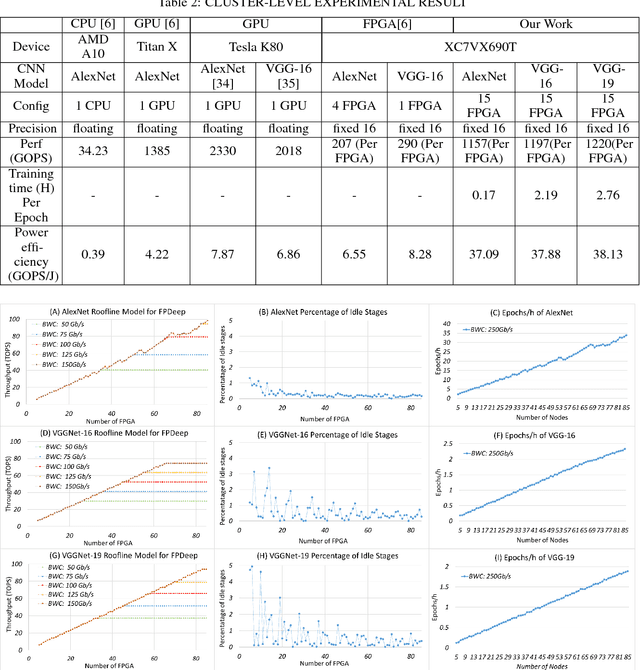
Deep Neural Networks (DNNs) have revolutionized numerous applications, but the demand for ever more performance remains unabated. Scaling DNN computations to larger clusters is generally done by distributing tasks in batch mode using methods such as distributed synchronous SGD. Among the issues with this approach is that to make the distributed cluster work with high utilization, the workload distributed to each node must be large, which implies nontrivial growth in the SGD mini-batch size. In this paper, we propose a framework called FPDeep, which uses a hybrid of model and layer parallelism to configure distributed reconfigurable clusters to train DNNs. This approach has numerous benefits. First, the design does not suffer from batch size growth. Second, novel workload and weight partitioning leads to balanced loads of both among nodes. And third, the entire system is a fine-grained pipeline. This leads to high parallelism and utilization and also minimizes the time features need to be cached while waiting for back-propagation. As a result, storage demand is reduced to the point where only on-chip memory is used for the convolution layers. We evaluate FPDeep with the Alexnet, VGG-16, and VGG-19 benchmarks. Experimental results show that FPDeep has good scalability to a large number of FPGAs, with the limiting factor being the FPGA-to-FPGA bandwidth. With 6 transceivers per FPGA, FPDeep shows linearity up to 83 FPGAs. Energy efficiency is evaluated with respect to GOPs/J. FPDeep provides, on average, 6.36x higher energy efficiency than comparable GPU servers.