 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Eye View: Monocular Real-time Perception Package for Autonomous Driving
Mar 22, 2026Amidst the rapid advancement of camera-based autonomous driving technology, effectiveness is often prioritized with limited attention to computational efficiency. To address this issue, this paper introduces LRHPerception, a real-time monocular perception package for autonomous driving that uses single-view camera video to interpret the surrounding environment. The proposed system combines the computational efficiency of end-to-end learning with the rich representational detail of local mapping methodologies. With significant improvements in object tracking and prediction, road segmentation, and depth estimation integrated into a unified framework, LRHPerception processes monocular image data into a five-channel tensor consisting of RGB, road segmentation, and pixel-level depth estimation, augmented with object detection and trajectory prediction. Experimental results demonstrate strong performance, achieving real-time processing at 29 FPS on a single GPU, representing a 555% speedup over the fastest mapping-based approach.
Zeros can be Informative: Masked Binary U-Net for Image Segmentation on Tensor Cores
Jan 15, 2026Real-time image segmentation is a key enabler for AR/VR, robotics, drones, and autonomous systems, where tight accuracy, latency, and energy budgets must be met on resource-constrained edge devices. While U-Net offers a favorable balance of accuracy and efficiency compared to large transformer-based models, achieving real-time performance on high-resolution input remains challenging due to compute, memory, and power limits. Extreme quantization, particularly binary networks, is appealing for its hardware-friendly operations. However, two obstacles limit practicality: (1) severe accuracy degradation, and (2) a lack of end-to-end implementations that deliver efficiency on general-purpose GPUs. We make two empirical observations that guide our design. (1) An explicit zero state is essential: training with zero masking to binary U-Net weights yields noticeable sparsity. (2) Quantization sensitivity is uniform across layers. Motivated by these findings, we introduce Masked Binary U-Net (MBU-Net), obtained through a cost-aware masking strategy that prioritizes masking where it yields the highest accuracy-per-cost, reconciling accuracy with near-binary efficiency. To realize these gains in practice, we develop a GPU execution framework that maps MBU-Net to Tensor Cores via a subtractive bit-encoding scheme, efficiently implementing masked binary weights with binary activations. This design leverages native binary Tensor Core BMMA instructions, enabling high throughput and energy savings on widely available GPUs. Across 3 segmentation benchmarks, MBU-Net attains near full-precision accuracy (3% average drop) while delivering 2.04x speedup and 3.54x energy reductions over a 16-bit floating point U-Net.
Visual Fourier Prompt Tuning
Nov 02, 2024
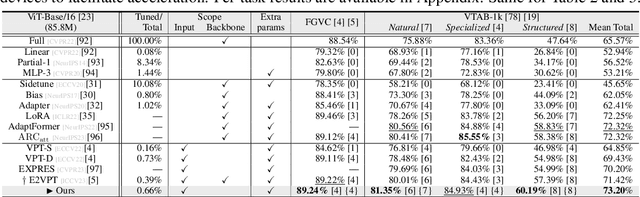
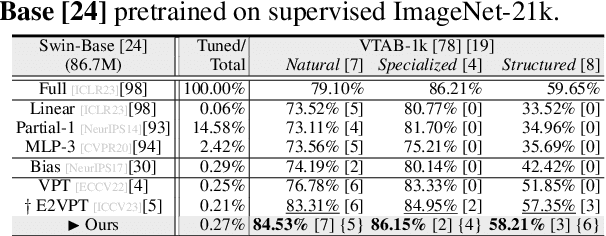
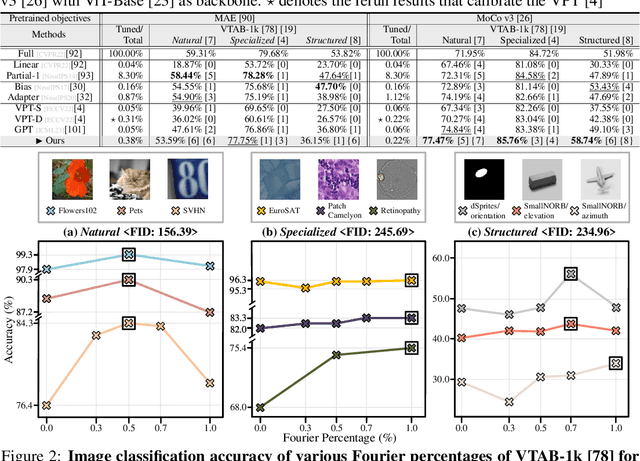
With the scale of vision Transformer-based models continuing to grow, finetuning these large-scale pretrained models for new tasks has become increasingly parameter-intensive. Visual prompt tuning is introduced as a parameter-efficient finetuning (PEFT) method to this trend. Despite its successes, a notable research challenge persists within almost all PEFT approaches: significant performance degradation is observed when there is a substantial disparity between the datasets applied in pretraining and finetuning phases. To address this challenge, we draw inspiration from human visual cognition, and propose the Visual Fourier Prompt Tuning (VFPT) method as a general and effective solution for adapting large-scale transformer-based models. Our approach innovatively incorporates the Fast Fourier Transform into prompt embeddings and harmoniously considers both spatial and frequency domain information. Apart from its inherent simplicity and intuitiveness, VFPT exhibits superior performance across all datasets, offering a general solution to dataset challenges, irrespective of data disparities. Empirical results demonstrate that our approach outperforms current state-of-the-art baselines on two benchmarks, with low parameter usage (e.g., 0.57% of model parameters on VTAB-1k) and notable performance enhancements (e.g., 73.20% of mean accuracy on VTAB-1k). Our code is avaliable at https://github.com/runtsang/VFPT.
Diff-PIC: Revolutionizing Particle-In-Cell Simulation for Advancing Nuclear Fusion with Diffusion Models
Aug 03, 2024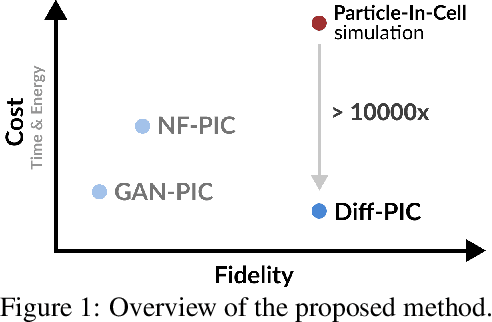
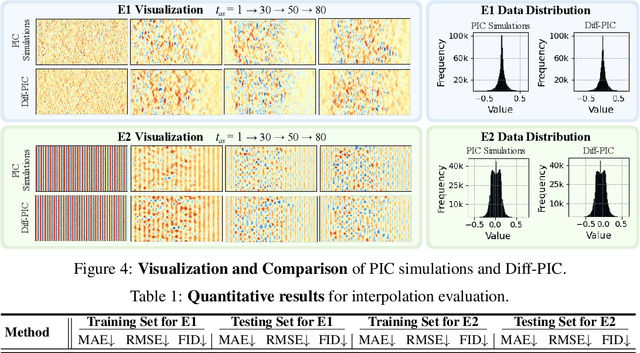
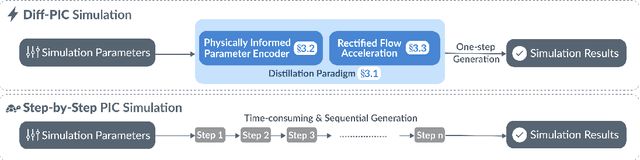
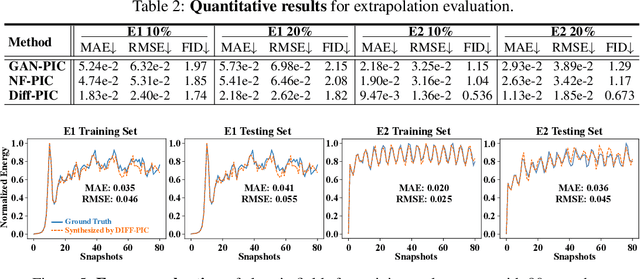
Sustainable energy is a crucial global challenge, and recent breakthroughs in nuclear fusion ignition underscore the potential of harnessing energy extracted from nuclear fusion in everyday life, thereby drawing significant attention to fusion ignition research, especially Laser-Plasma Interaction (LPI). Unfortunately, the complexity of LPI at ignition scale renders theory-based analysis nearly impossible -- instead, it has to rely heavily on Particle-in-Cell (PIC) simulations, which is extremely computationally intensive, making it a major bottleneck in advancing fusion ignition. In response, this work introduces Diff-PIC, a novel paradigm that leverages conditional diffusion models as a computationally efficient alternative to PIC simulations for generating high-fidelity scientific data. Specifically, we design a distillation paradigm to distill the physical patterns captured by PIC simulations into diffusion models, demonstrating both theoretical and practical feasibility. Moreover, to ensure practical effectiveness, we provide solutions for two critical challenges: (1) We develop a physically-informed conditional diffusion model that can learn and generate meaningful embeddings for mathematically continuous physical conditions. This model offers algorithmic generalization and adaptable transferability, effectively capturing the complex relationships between physical conditions and simulation outcomes; and (2) We employ the rectified flow technique to make our model a one-step conditional diffusion model, enhancing its efficiency further while maintaining high fidelity and physical validity. Diff-PIC establishes a new paradigm for using diffusion models to overcome the computational barriers in nuclear fusion research, setting a benchmark for future innovations and advancements in this field.
Inertial Confinement Fusion Forecasting via LLMs
Jul 15, 2024Controlled fusion energy is deemed pivotal for the advancement of human civilization. In this study, we introduce $\textbf{Fusion-LLM}$, a novel integration of Large Language Models (LLMs) with classical reservoir computing paradigms tailored to address challenges in Inertial Confinement Fusion ($\texttt{ICF}$). Our approach offers several key contributions: Firstly, we propose the $\textit{LLM-anchored Reservoir}$, augmented with a fusion-specific prompt, enabling accurate forecasting of hot electron dynamics during implosion. Secondly, we develop $\textit{Signal-Digesting Channels}$ to temporally and spatially describe the laser intensity across time, capturing the unique characteristics of $\texttt{ICF}$ inputs. Lastly, we design the $\textit{Confidence Scanner}$ to quantify the confidence level in forecasting, providing valuable insights for domain experts to design the $\texttt{ICF}$ process. Extensive experiments demonstrate the superior performance of our method, achieving 1.90 CAE, 0.14 $\texttt{top-1}$ MAE, and 0.11 $\texttt{top-5}$ MAE in predicting Hard X-ray ($\texttt{HXR}$) energies of $\texttt{ICF}$ tasks, which presents state-of-the-art comparisons against concurrent best systems. Additionally, we present $\textbf{Fusion4AI}$, the first $\texttt{ICF}$ benchmark based on physical experiments, aimed at fostering novel ideas in plasma physics research and enhancing the utility of LLMs in scientific exploration. Overall, our work strives to forge an innovative synergy between AI and plasma science for advancing fusion energy.
I-GCN: A Graph Convolutional Network Accelerator with Runtime Locality Enhancement through Islandization
Mar 07, 2022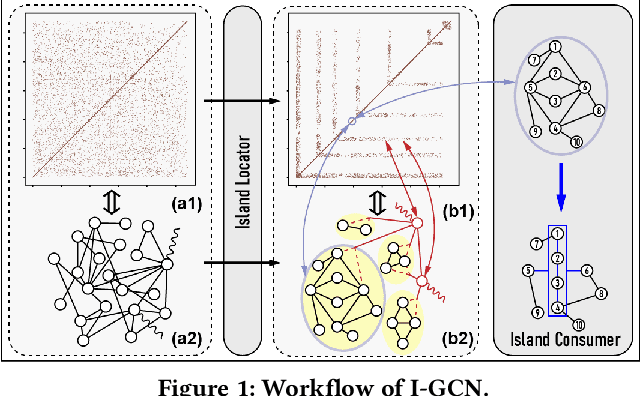
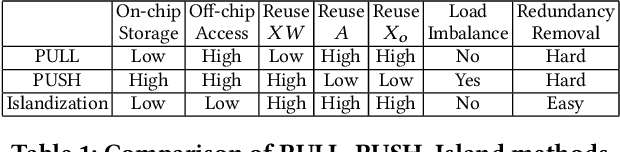
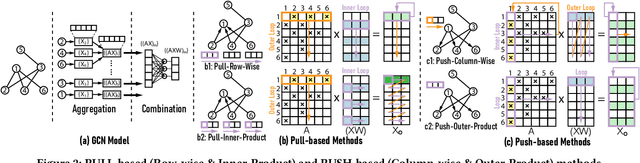

Graph Convolutional Networks (GCNs) have drawn tremendous attention in the past three years. Compared with other deep learning modalities, high-performance hardware acceleration of GCNs is as critical but even more challenging. The hurdles arise from the poor data locality and redundant computation due to the large size, high sparsity, and irregular non-zero distribution of real-world graphs. In this paper we propose a novel hardware accelerator for GCN inference, called I-GCN, that significantly improves data locality and reduces unnecessary computation. The mechanism is a new online graph restructuring algorithm we refer to as islandization. The proposed algorithm finds clusters of nodes with strong internal but weak external connections. The islandization process yields two major benefits. First, by processing islands rather than individual nodes, there is better on-chip data reuse and fewer off-chip memory accesses. Second, there is less redundant computation as aggregation for common/shared neighbors in an island can be reused. The parallel search, identification, and leverage of graph islands are all handled purely in hardware at runtime working in an incremental pipeline. This is done without any preprocessing of the graph data or adjustment of the GCN model structure. Experimental results show that I-GCN can significantly reduce off-chip accesses and prune 38% of aggregation operations, leading to performance speedups over CPUs, GPUs, the prior art GCN accelerators of 5549x, 403x, and 5.7x on average, respectively.
UWB-GCN: Hardware Acceleration of Graph-Convolution-Network through Runtime Workload Rebalancing
Aug 23, 2019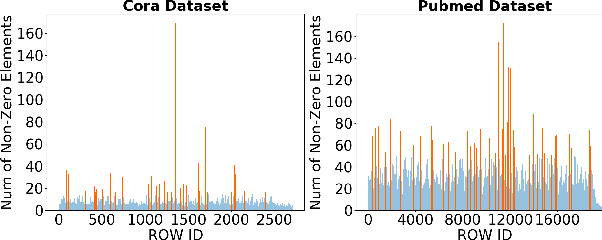
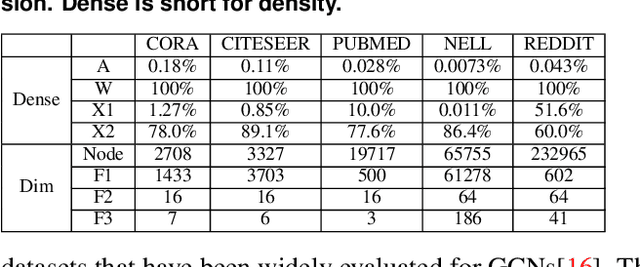
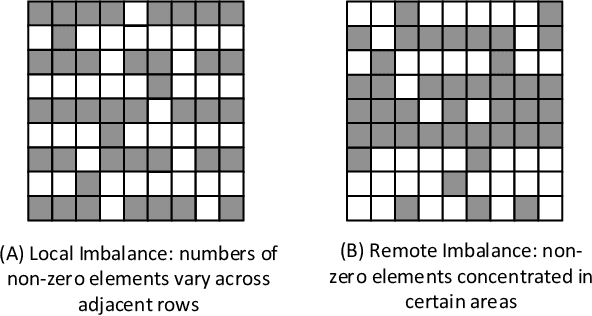
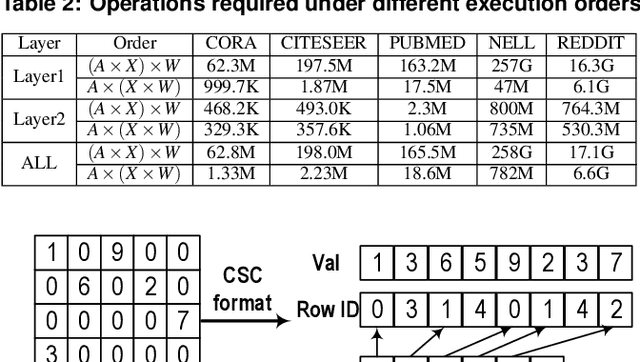
The recent development of deep learning has mostly been focusing on Euclidean data, such as images, videos, and audios. However, most real-world information and relationships are often expressed in graphs. Graph convolutional networks (GCNs) appear as a promising approach to efficiently learn from graph data structures, showing advantages in several practical applications such as social network analysis, knowledge discovery, 3D modeling, and motion capturing. However, practical graphs are often extremely large and unbalanced, posting significant performance demand and design challenges on the hardware dedicated to GCN inference. In this paper, we propose an architecture design called Ultra-Workload-Balanced-GCN (UWB-GCN) to accelerate graph convolutional network inference. To tackle the major performance bottleneck of workload imbalance, we propose two techniques: dynamic local sharing and dynamic remote switching, both of which rely on hardware flexibility to achieve performance auto-tuning with negligible area or delay overhead. Specifically, UWB-GCN is able to effectively profile the sparse graph pattern while continuously adjusting the workload distribution among parallel processing elements (PEs). After converging, the ideal configuration is reused for the remaining iterations. To the best of our knowledge, this is the first accelerator design targeted to GCNs and the first work that auto-tunes workload balance in accelerator at runtime through hardware, rather than software, approaches. Our methods can achieve near-ideal workload balance in processing sparse matrices. Experimental results show that UWB-GCN can finish the inference of the Nell graph (66K vertices, 266K edges) in 8.4ms, corresponding to 192x, 289x, and 7.3x respectively, compared to the CPU, GPU, and the baseline GCN design without workload rebalancing.