 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-GCN: A Graph Convolutional Network Accelerator with Runtime Locality Enhancement through Islandization
Mar 07, 2022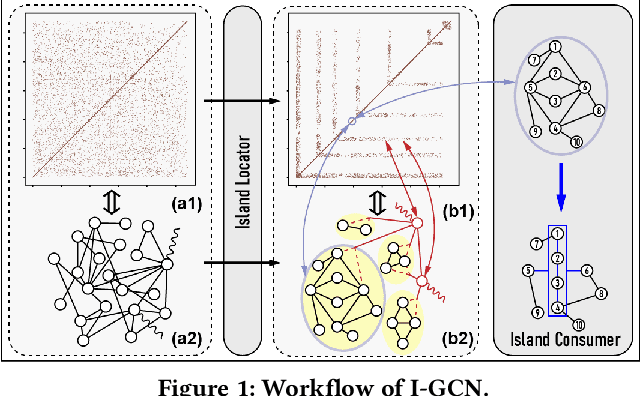
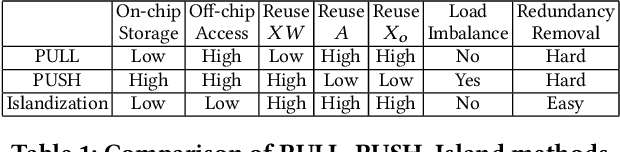
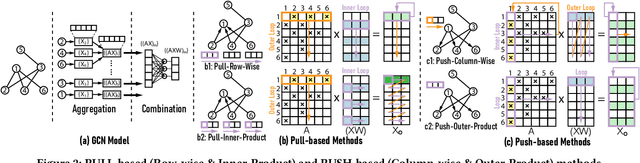

Graph Convolutional Networks (GCNs) have drawn tremendous attention in the past three years. Compared with other deep learning modalities, high-performance hardware acceleration of GCNs is as critical but even more challenging. The hurdles arise from the poor data locality and redundant computation due to the large size, high sparsity, and irregular non-zero distribution of real-world graphs. In this paper we propose a novel hardware accelerator for GCN inference, called I-GCN, that significantly improves data locality and reduces unnecessary computation. The mechanism is a new online graph restructuring algorithm we refer to as islandization. The proposed algorithm finds clusters of nodes with strong internal but weak external connections. The islandization process yields two major benefits. First, by processing islands rather than individual nodes, there is better on-chip data reuse and fewer off-chip memory accesses. Second, there is less redundant computation as aggregation for common/shared neighbors in an island can be reused. The parallel search, identification, and leverage of graph islands are all handled purely in hardware at runtime working in an incremental pipeline. This is done without any preprocessing of the graph data or adjustment of the GCN model structure. Experimental results show that I-GCN can significantly reduce off-chip accesses and prune 38% of aggregation operations, leading to performance speedups over CPUs, GPUs, the prior art GCN accelerators of 5549x, 403x, and 5.7x on average, respectively.
Rule Mining over Knowledge Graphs via Reinforcement Learning
Feb 21, 2022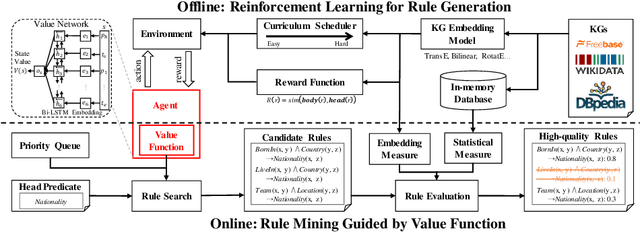
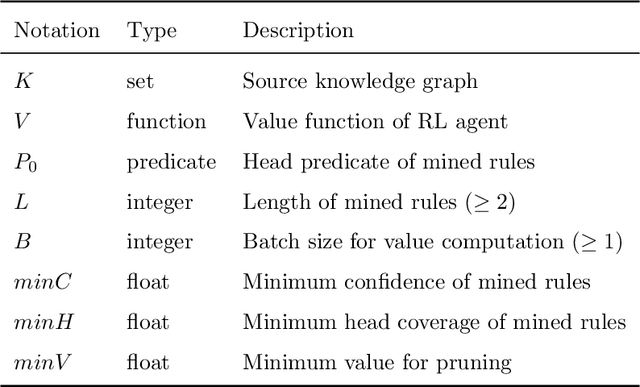
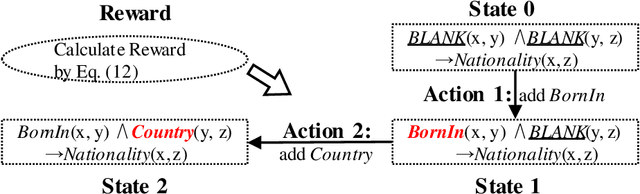
Knowledge graphs (KGs) are an important source repository for a wide range of applications and rule mining from KGs recently attracts wide research interest in the KG-related research community. Many solutions have been proposed for the rule mining from large-scale KGs, which however are limited in the inefficiency of rule generation and ineffectiveness of rule evaluation. To solve these problems, in this paper we propose a generation-then-evaluation rule mining approach guided by reinforcement learning. Specifically, a two-phased framework is designed. The first phase aims to train a reinforcement learning agent for rule generation from KGs, and the second is to utilize the value function of the agent to guide the step-by-step rule generation. We conduct extensive experiments on several datasets and the results prove that our rule mining solution achieves state-of-the-art performance in terms of efficiency and effectiveness.
* Knowledge-Based Systems
Revisiting the Negative Data of Distantly Supervised Relation Extraction
May 21, 2021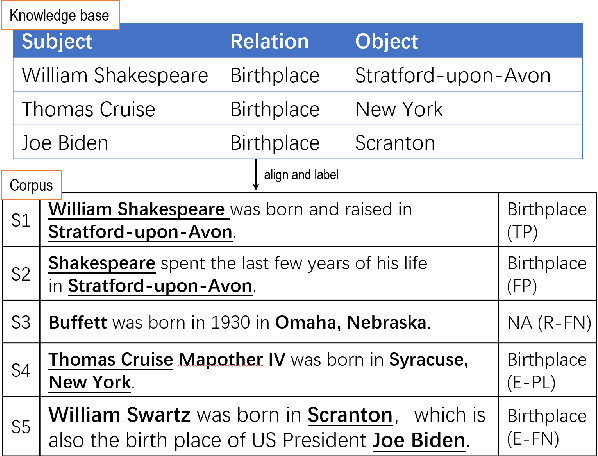
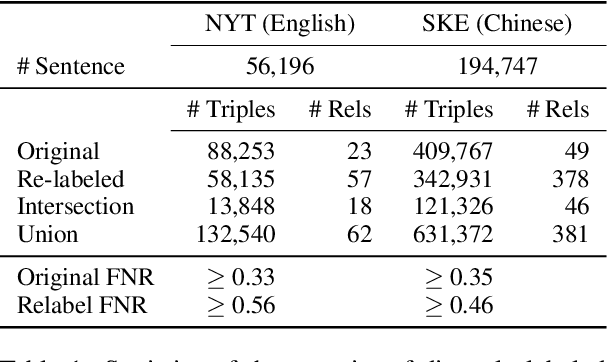
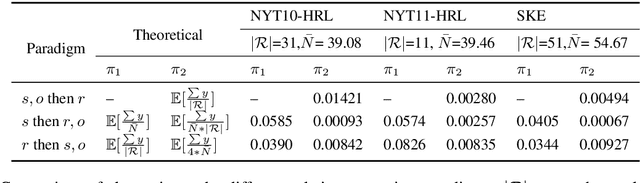
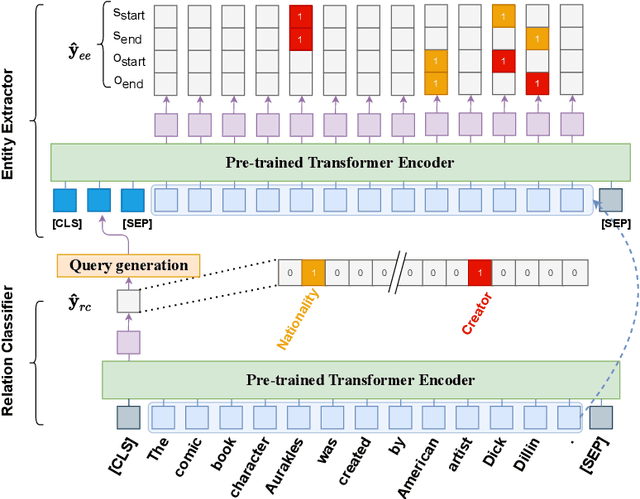
Distantly supervision automatically generates plenty of training samples for relation extraction. However, it also incurs two major problems: noisy labels and imbalanced training data. Previous works focus more on reducing wrongly labeled relations (false positives) while few explore the missing relations that are caused by incompleteness of knowledge base (false negatives). Furthermore, the quantity of negative labels overwhelmingly surpasses the positive ones in previous problem formulations. In this paper, we first provide a thorough analysis of the above challenges caused by negative data. Next, we formulate the problem of relation extraction into as a positive unlabeled learning task to alleviate false negative problem. Thirdly, we propose a pipeline approach, dubbed \textsc{ReRe}, that performs sentence-level relation detection then subject/object extraction to achieve sample-efficient training. Experimental results show that the proposed method consistently outperforms existing approaches and remains excellent performance even learned with a large quantity of false positive samples.
Collective Loss Function for Positive and Unlabeled Learning
May 06, 2020
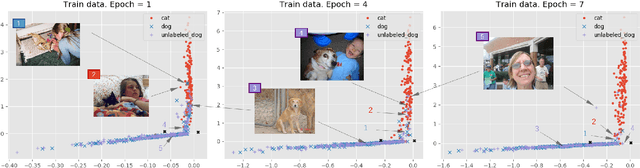
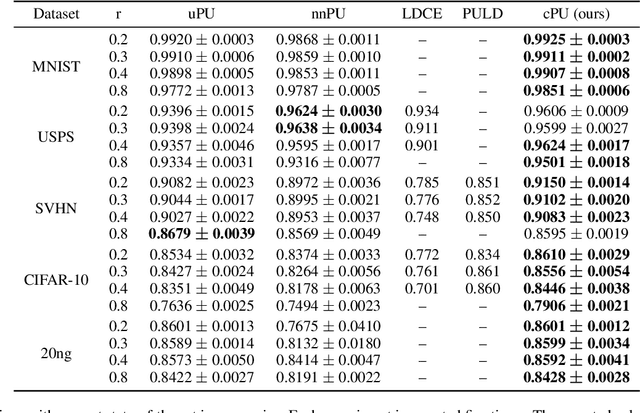
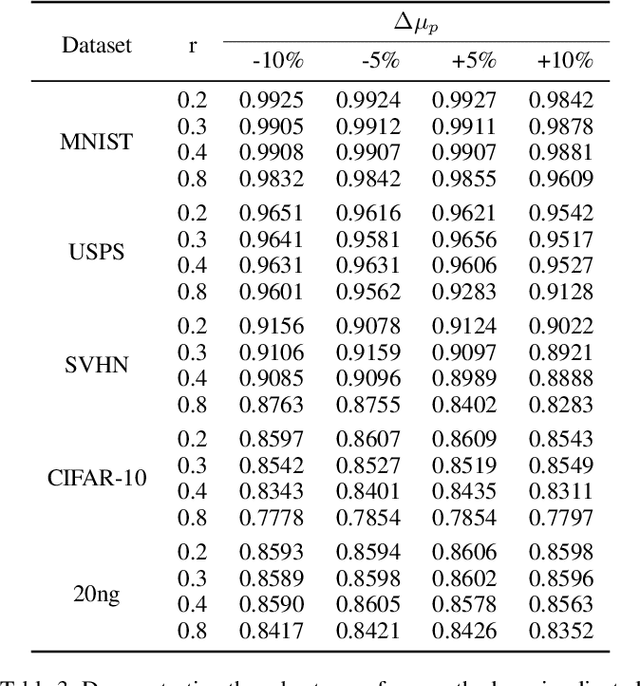
People learn to discriminate between classes without explicit exposure to negative examples. On the contrary, traditional machine learning algorithms often rely on negative examples, otherwise the model would be prone to collapse and always-true predictions. Therefore, it is crucial to design the learning objective which leads the model to converge and to perform predictions unbiasedly without explicit negative signals. In this paper, we propose a Collectively loss function to learn from only Positive and Unlabeled data (cPU). We theoretically elicit the loss function from the setting of PU learning. We perform intensive experiments on the benchmark and real-world datasets. The results show that cPU consistently outperforms the current state-of-the-art PU learning methods.
Enabling Highly Efficient Capsule Networks Processing Through A PIM-Based Architecture Design
Nov 07, 2019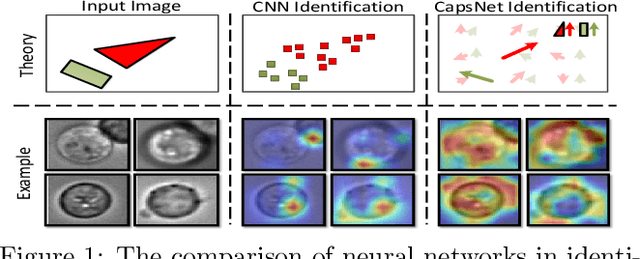

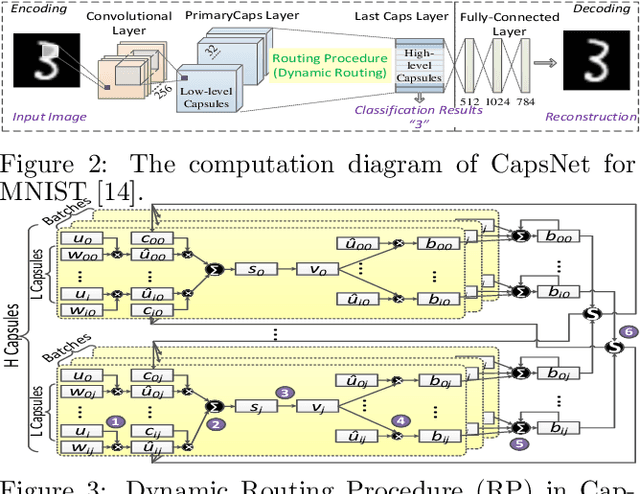
In recent years, the CNNs have achieved great successes in the image processing tasks, e.g., image recognition and object detection. Unfortunately, traditional CNN's classification is found to be easily misled by increasingly complex image features due to the usage of pooling operations, hence unable to preserve accurate position and pose information of the objects. To address this challenge, a novel neural network structure called Capsule Network has been proposed, which introduces equivariance through capsules to significantly enhance the learning ability for image segmentation and object detection. Due to its requirement of performing a high volume of matrix operations, CapsNets have been generally accelerated on modern GPU platforms that provide highly optimized software library for common deep learning tasks. However, based on our performance characterization on modern GPUs, CapsNets exhibit low efficiency due to the special program and execution features of their routing procedure, including massive unshareable intermediate variables and intensive synchronizations, which are very difficult to optimize at software level. To address these challenges, we propose a hybrid computing architecture design named \textit{PIM-CapsNet}. It preserves GPU's on-chip computing capability for accelerating CNN types of layers in CapsNet, while pipelining with an off-chip in-memory acceleration solution that effectively tackles routing procedure's inefficiency by leveraging the processing-in-memory capability of today's 3D stacked memory. Using routing procedure's inherent parallellization feature, our design enables hierarchical improvements on CapsNet inference efficiency through minimizing data movement and maximizing parallel processing in memory.