 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFL-Tuning: Layer Tuning for Feed-Forward Network in Transformer
Jun 30, 2022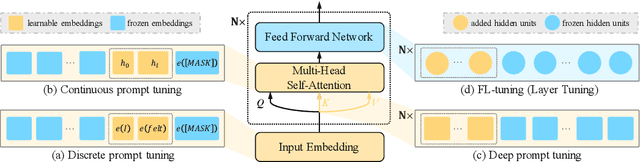
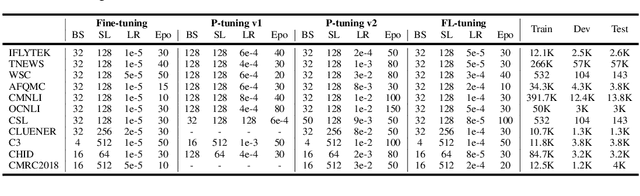
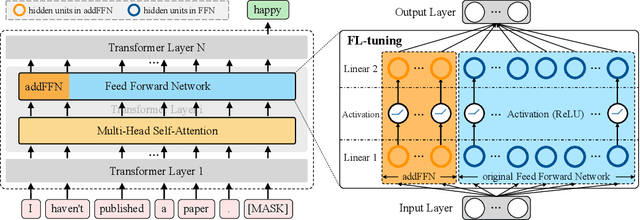
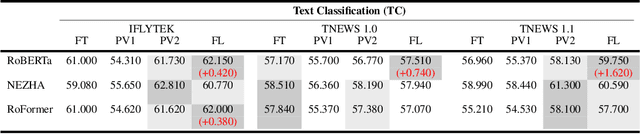
Prompt tuning is an emerging way of adapting pre-trained language models to downstream tasks. However, the existing studies are mainly to add prompts to the input sequence. This way would not work as expected due to the intermediate multi-head self-attention and feed-forward network computation, making model optimization not very smooth. Hence, we propose a novel tuning way called layer tuning, aiming to add learnable parameters in Transformer layers. Specifically, we focus on layer tuning for feed-forward network in the Transformer, namely FL-tuning. It introduces additional units into the hidden layer of each feed-forward network. We conduct extensive experiments on the public CLUE benchmark. The results show that: 1) Our FL-tuning outperforms prompt tuning methods under both full-data and few-shot settings in almost all cases. In particular, it improves accuracy by 17.93% (full-data setting) on WSC 1.0 and F1 by 16.142% (few-shot setting) on CLUENER over P-tuning v2. 2) Our FL-tuning is more stable and converges about 1.17 times faster than P-tuning v2. 3) With only about 3% of Transformer's parameters to be trained, FL-tuning is comparable with fine-tuning on most datasets, and significantly outperforms fine-tuning (e.g., accuracy improved by 12.9% on WSC 1.1) on several datasets. The source codes are available at https://github.com/genggui001/FL-Tuning.
WikiDiverse: A Multimodal Entity Linking Dataset with Diversified Contextual Topics and Entity Types
Apr 13, 2022
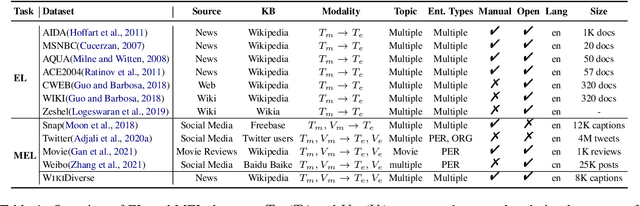
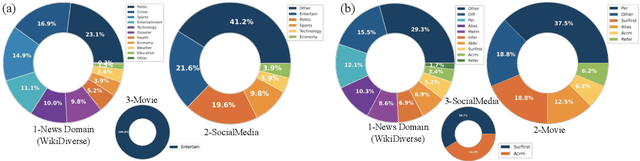

Multimodal Entity Linking (MEL) which aims at linking mentions with multimodal contexts to the referent entities from a knowledge base (e.g., Wikipedia), is an essential task for many multimodal applications. Although much attention has been paid to MEL, the shortcomings of existing MEL datasets including limited contextual topics and entity types, simplified mention ambiguity, and restricted availability, have caused great obstacles to the research and application of MEL. In this paper, we present WikiDiverse, a high-quality human-annotated MEL dataset with diversified contextual topics and entity types from Wikinews, which uses Wikipedia as the corresponding knowledge base. A well-tailored annotation procedure is adopted to ensure the quality of the dataset. Based on WikiDiverse, a sequence of well-designed MEL models with intra-modality and inter-modality attentions are implemented, which utilize the visual information of images more adequately than existing MEL models do. Extensive experimental analyses are conducted to investigate the contributions of different modalities in terms of MEL, facilitating the future research on this task. The dataset and baseline models are available at https://github.com/wangxw5/wikiDiverse.
Rule Mining over Knowledge Graphs via Reinforcement Learning
Feb 21, 2022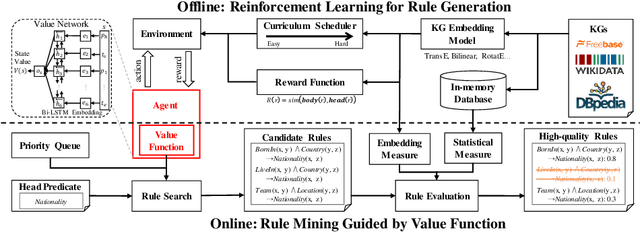
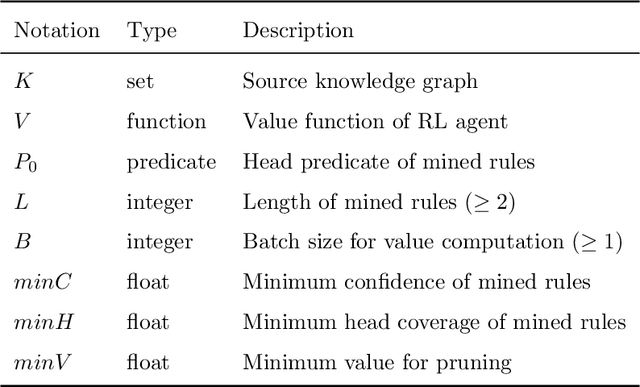
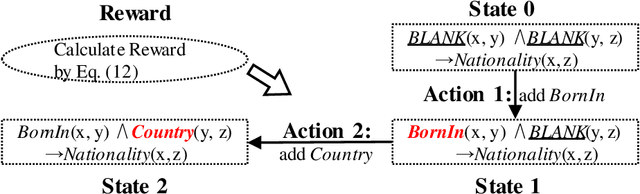
Knowledge graphs (KGs) are an important source repository for a wide range of applications and rule mining from KGs recently attracts wide research interest in the KG-related research community. Many solutions have been proposed for the rule mining from large-scale KGs, which however are limited in the inefficiency of rule generation and ineffectiveness of rule evaluation. To solve these problems, in this paper we propose a generation-then-evaluation rule mining approach guided by reinforcement learning. Specifically, a two-phased framework is designed. The first phase aims to train a reinforcement learning agent for rule generation from KGs, and the second is to utilize the value function of the agent to guide the step-by-step rule generation. We conduct extensive experiments on several datasets and the results prove that our rule mining solution achieves state-of-the-art performance in terms of efficiency and effectiveness.
* Knowledge-Based Systems
Collective Loss Function for Positive and Unlabeled Learning
May 06, 2020
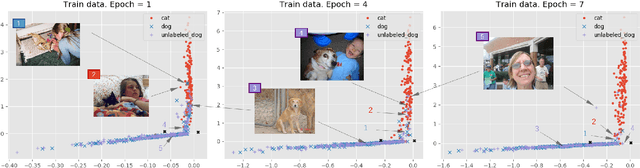
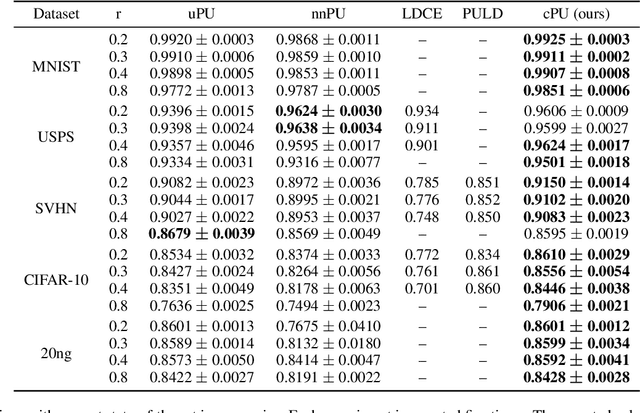
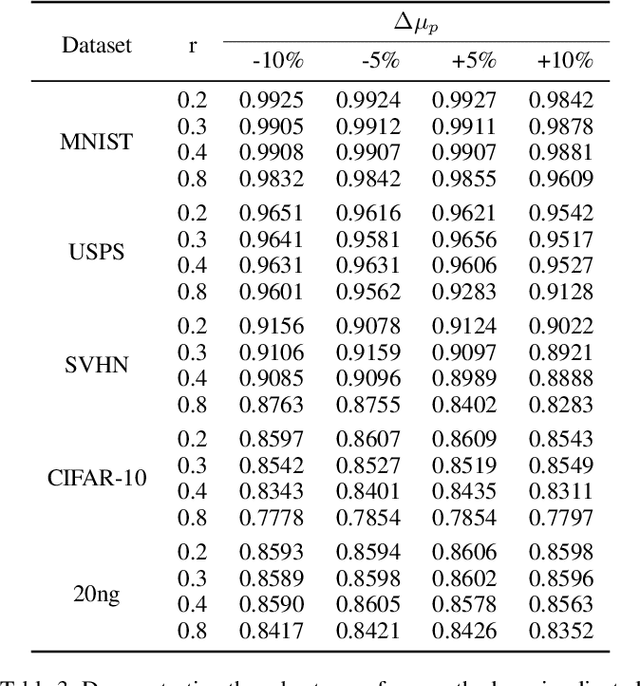
People learn to discriminate between classes without explicit exposure to negative examples. On the contrary, traditional machine learning algorithms often rely on negative examples, otherwise the model would be prone to collapse and always-true predictions. Therefore, it is crucial to design the learning objective which leads the model to converge and to perform predictions unbiasedly without explicit negative signals. In this paper, we propose a Collectively loss function to learn from only Positive and Unlabeled data (cPU). We theoretically elicit the loss function from the setting of PU learning. We perform intensive experiments on the benchmark and real-world datasets. The results show that cPU consistently outperforms the current state-of-the-art PU learning methods.