 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Consistent Data Augmentation for Neural Machine Translation via Conditional Masked Language Model
Sep 22, 2022
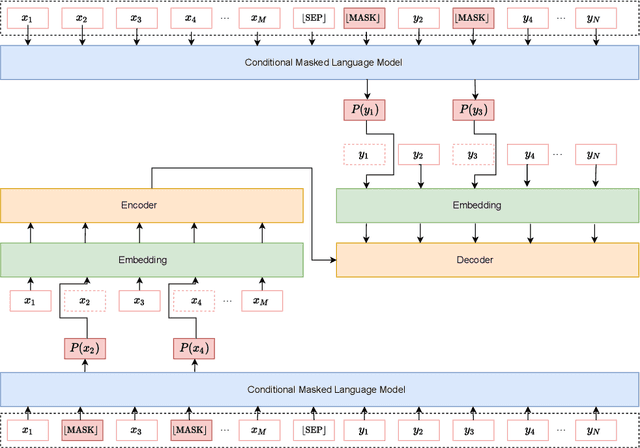
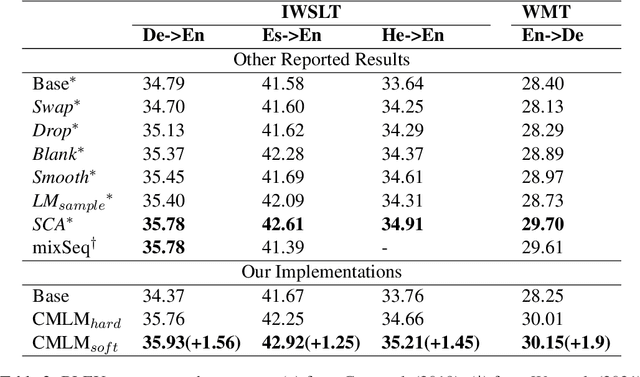
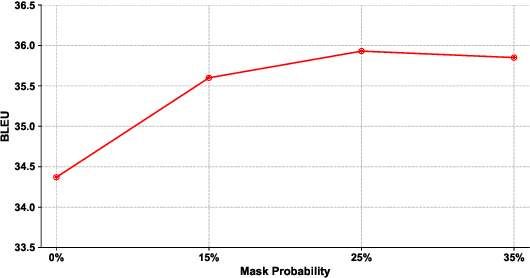
This paper introduces a new data augmentation method for neural machine translation that can enforce stronger semantic consistency both within and across languages. Our method is based on Conditional Masked Language Model (CMLM) which is bi-directional and can be conditional on both left and right context, as well as the label. We demonstrate that CMLM is a good technique for generating context-dependent word distributions. In particular, we show that CMLM is capable of enforcing semantic consistency by conditioning on both source and target during substitution. In addition, to enhance diversity, we incorporate the idea of soft word substitution for data augmentation which replaces a word with a probabilistic distribution over the vocabulary. Experiments on four translation datasets of different scales show that the overall solution results in more realistic data augmentation and better translation quality. Our approach consistently achieves the best performance in comparison with strong and recent works and yields improvements of up to 1.90 BLEU points over the baseline.
Complex Relation Extraction: Challenges and Opportunities
Dec 09, 2020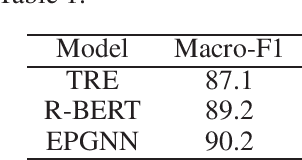

Relation extraction aims to identify the target relations of entities in texts. Relation extraction is very important for knowledge base construction and text understanding. Traditional binary relation extraction, including supervised, semi-supervised and distant supervised ones, has been extensively studied and significant results are achieved. In recent years, many complex relation extraction tasks, i.e., the variants of simple binary relation extraction, are proposed to meet the complex applications in practice. However, there is no literature to fully investigate and summarize these complex relation extraction works so far. In this paper, we first report the recent progress in traditional simple binary relation extraction. Then we summarize the existing complex relation extraction tasks and present the definition, recent progress, challenges and opportunities for each task.
Collective Loss Function for Positive and Unlabeled Learning
May 06, 2020
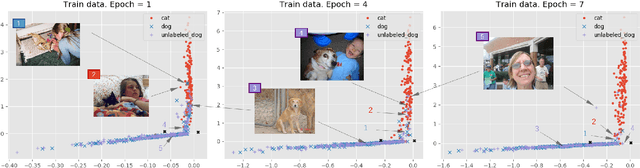
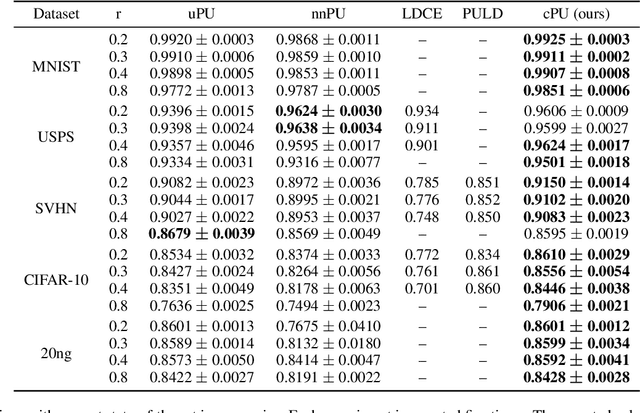
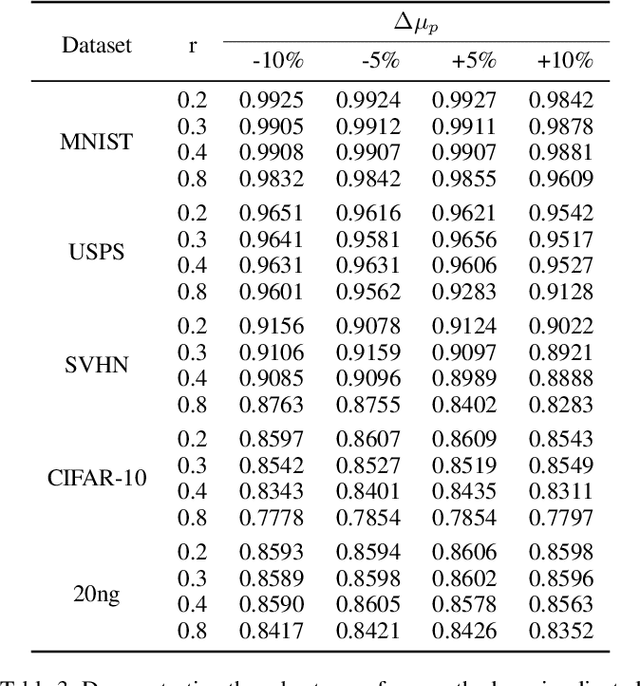
People learn to discriminate between classes without explicit exposure to negative examples. On the contrary, traditional machine learning algorithms often rely on negative examples, otherwise the model would be prone to collapse and always-true predictions. Therefore, it is crucial to design the learning objective which leads the model to converge and to perform predictions unbiasedly without explicit negative signals. In this paper, we propose a Collectively loss function to learn from only Positive and Unlabeled data (cPU). We theoretically elicit the loss function from the setting of PU learning. We perform intensive experiments on the benchmark and real-world datasets. The results show that cPU consistently outperforms the current state-of-the-art PU learning methods.
Breaking the Data Barrier: Towards Robust Speech Translation via Adversarial Stability Training
Oct 28, 2019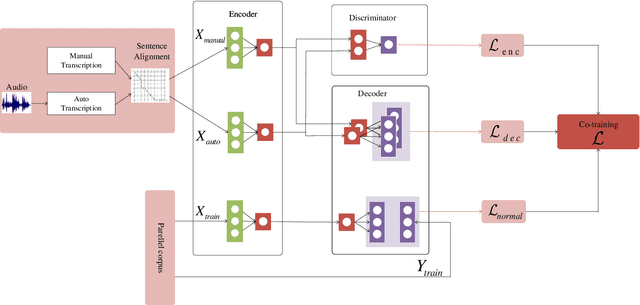
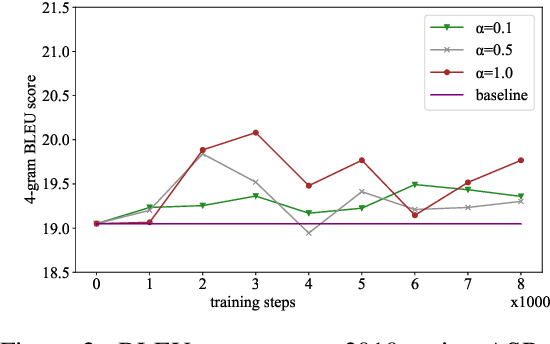
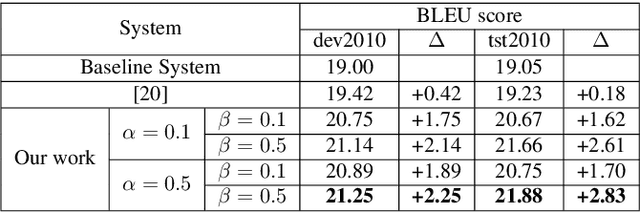
In a pipeline speech translation system, automatic speech recognition (ASR) system will transmit errors in recognition to the downstream machine translation (MT) system. A standard machine translation system is usually trained on parallel corpus composed of clean text and will perform poorly on text with recognition noise, a gap well known in speech translation community. In this paper, we propose a training architecture which aims at making a neural machine translation model more robust against speech recognition errors. Our approach addresses the encoder and the decoder simultaneously using adversarial learning and data augmentation, respectively. Experimental results on IWSLT2018 speech translation task show that our approach can bridge the gap between the ASR output and the MT input, outperforms the baseline by up to 2.83 BLEU on noisy ASR output, while maintaining close performance on clean text.