 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Consistent Data Augmentation for Neural Machine Translation via Conditional Masked Language Model
Paper and Code

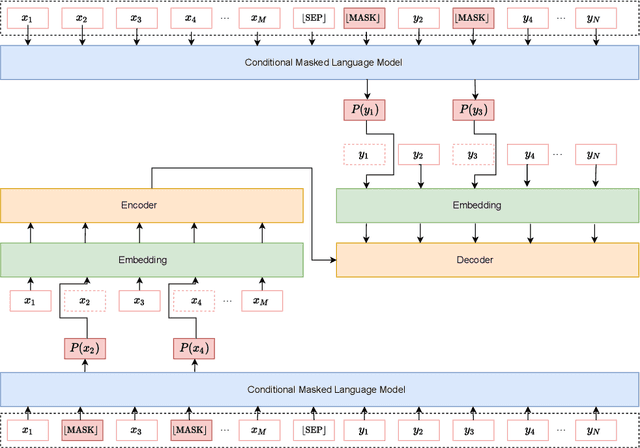
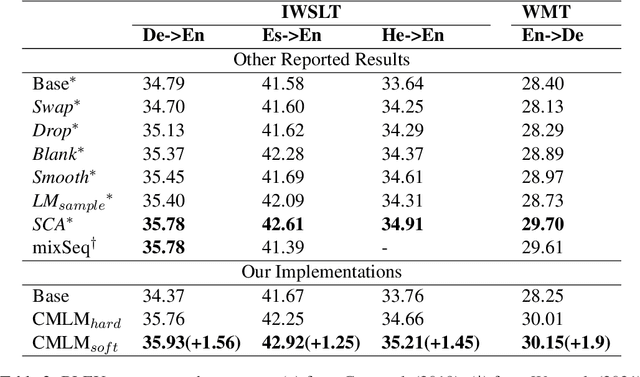
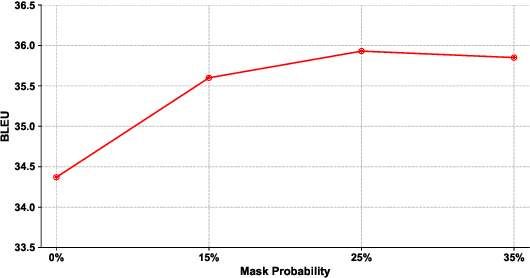
This paper introduces a new data augmentation method for neural machine translation that can enforce stronger semantic consistency both within and across languages. Our method is based on Conditional Masked Language Model (CMLM) which is bi-directional and can be conditional on both left and right context, as well as the label. We demonstrate that CMLM is a good technique for generating context-dependent word distributions. In particular, we show that CMLM is capable of enforcing semantic consistency by conditioning on both source and target during substitution. In addition, to enhance diversity, we incorporate the idea of soft word substitution for data augmentation which replaces a word with a probabilistic distribution over the vocabulary. Experiments on four translation datasets of different scales show that the overall solution results in more realistic data augmentation and better translation quality. Our approach consistently achieves the best performance in comparison with strong and recent works and yields improvements of up to 1.90 BLEU points over the baseline.