 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEO: Stochastic Experience Optimization for Large Language Models
Jan 08, 2025Large Language Models (LLMs) can benefit from useful experiences to improve their performance on specific tasks. However, finding helpful experiences for different LLMs is not obvious, since it is unclear what experiences suit specific LLMs. Previous studies intended to automatically find useful experiences using LLMs, while it is difficult to ensure the effectiveness of the obtained experience. In this paper, we propose Stochastic Experience Optimization (SEO), an iterative approach that finds optimized model-specific experience without modifying model parameters through experience update in natural language. In SEO, we propose a stochastic validation method to ensure the update direction of experience, avoiding unavailing updates. Experimental results on three tasks for three LLMs demonstrate that experiences optimized by SEO can achieve consistently improved performance. Further analysis indicates that SEO-optimized experience can generalize to out-of-distribution data, boosting the performance of LLMs on similar tasks.
SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
May 09, 2024



Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
Semantically Consistent Data Augmentation for Neural Machine Translation via Conditional Masked Language Model
Sep 22, 2022
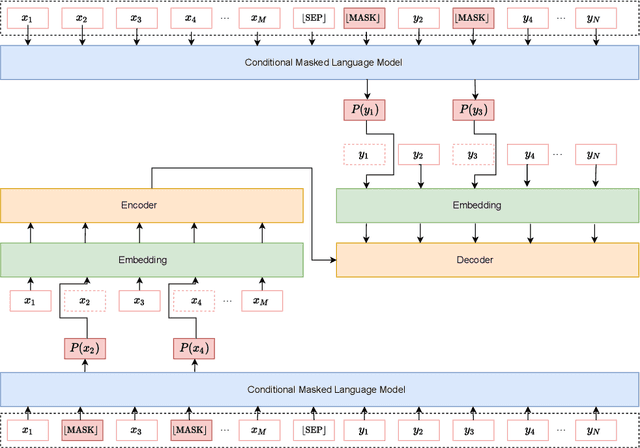
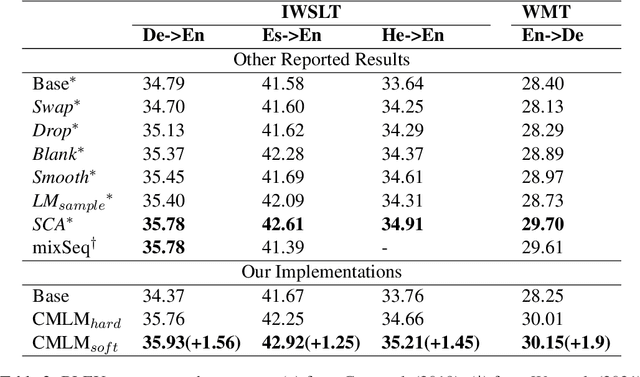
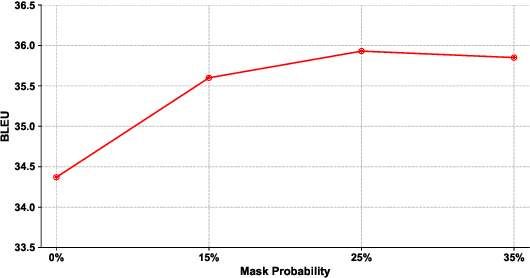
This paper introduces a new data augmentation method for neural machine translation that can enforce stronger semantic consistency both within and across languages. Our method is based on Conditional Masked Language Model (CMLM) which is bi-directional and can be conditional on both left and right context, as well as the label. We demonstrate that CMLM is a good technique for generating context-dependent word distributions. In particular, we show that CMLM is capable of enforcing semantic consistency by conditioning on both source and target during substitution. In addition, to enhance diversity, we incorporate the idea of soft word substitution for data augmentation which replaces a word with a probabilistic distribution over the vocabulary. Experiments on four translation datasets of different scales show that the overall solution results in more realistic data augmentation and better translation quality. Our approach consistently achieves the best performance in comparison with strong and recent works and yields improvements of up to 1.90 BLEU points over the baseline.
Breaking the Data Barrier: Towards Robust Speech Translation via Adversarial Stability Training
Oct 28, 2019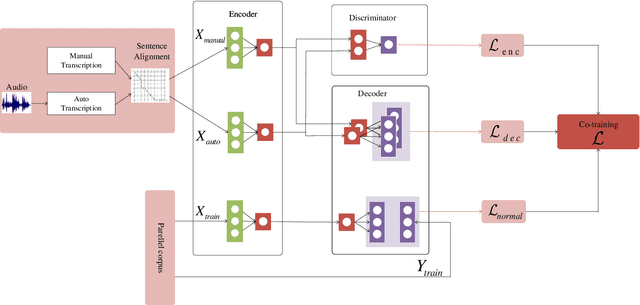
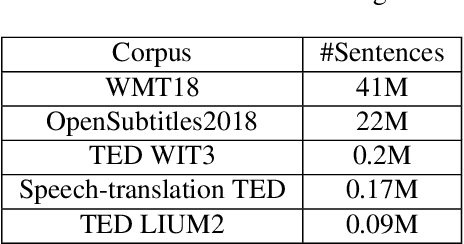
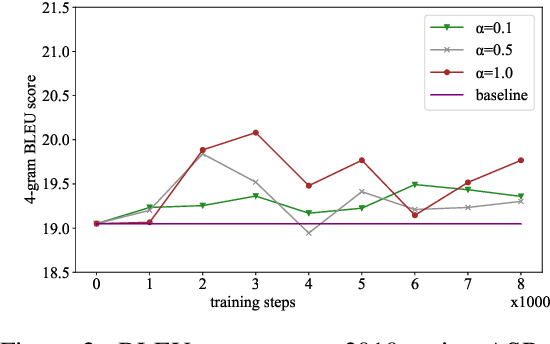
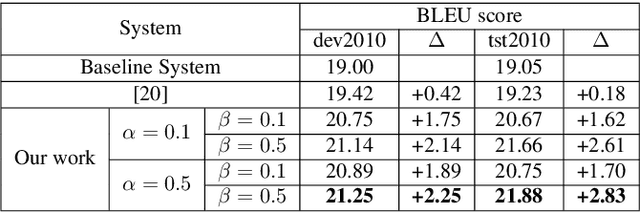
In a pipeline speech translation system, automatic speech recognition (ASR) system will transmit errors in recognition to the downstream machine translation (MT) system. A standard machine translation system is usually trained on parallel corpus composed of clean text and will perform poorly on text with recognition noise, a gap well known in speech translation community. In this paper, we propose a training architecture which aims at making a neural machine translation model more robust against speech recognition errors. Our approach addresses the encoder and the decoder simultaneously using adversarial learning and data augmentation, respectively. Experimental results on IWSLT2018 speech translation task show that our approach can bridge the gap between the ASR output and the MT input, outperforms the baseline by up to 2.83 BLEU on noisy ASR output, while maintaining close performance on clean text.