 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymphony: A Cognitively-Inspired Multi-Agent System for Long-Video Understanding
Mar 18, 2026Despite rapid developments and widespread applications of MLLM agents, they still struggle with long-form video understanding (LVU) tasks, which are characterized by high information density and extended temporal spans. Recent research on LVU agents demonstrates that simple task decomposition and collaboration mechanisms are insufficient for long-chain reasoning tasks. Moreover, directly reducing the time context through embedding-based retrieval may lose key information of complex problems. In this paper, we propose Symphony, a multi-agent system, to alleviate these limitations. By emulating human cognition patterns, Symphony decomposes LVU into fine-grained subtasks and incorporates a deep reasoning collaboration mechanism enhanced by reflection, effectively improving the reasoning capability. Additionally, Symphony provides a VLM-based grounding approach to analyze LVU tasks and assess the relevance of video segments, which significantly enhances the ability to locate complex problems with implicit intentions and large temporal spans. Experimental results show that Symphony achieves state-of-the-art performance on LVBench, LongVideoBench, VideoMME, and MLVU, with a 5.0% improvement over the prior state-of-the-art method on LVBench. Code is available at https://github.com/Haiyang0226/Symphony.
SEO: Stochastic Experience Optimization for Large Language Models
Jan 08, 2025Large Language Models (LLMs) can benefit from useful experiences to improve their performance on specific tasks. However, finding helpful experiences for different LLMs is not obvious, since it is unclear what experiences suit specific LLMs. Previous studies intended to automatically find useful experiences using LLMs, while it is difficult to ensure the effectiveness of the obtained experience. In this paper, we propose Stochastic Experience Optimization (SEO), an iterative approach that finds optimized model-specific experience without modifying model parameters through experience update in natural language. In SEO, we propose a stochastic validation method to ensure the update direction of experience, avoiding unavailing updates. Experimental results on three tasks for three LLMs demonstrate that experiences optimized by SEO can achieve consistently improved performance. Further analysis indicates that SEO-optimized experience can generalize to out-of-distribution data, boosting the performance of LLMs on similar tasks.
LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation
Feb 12, 2024
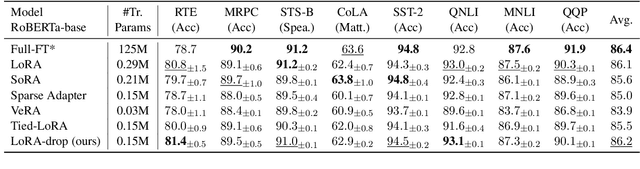

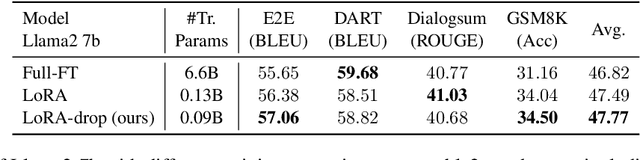
Low-Rank Adaptation (LoRA) introduces auxiliary parameters for each layer to fine-tune the pre-trained model under limited computing resources. But it still faces challenges of resource consumption when scaling up to larger models. Previous studies employ pruning techniques by evaluating the importance of LoRA parameters for different layers to address the problem. However, these efforts only analyzed parameter features to evaluate their importance. Indeed, the output of LoRA related to the parameters and data is the factor that directly impacts the frozen model. To this end, we propose LoRA-drop which evaluates the importance of the parameters by analyzing the LoRA output. We retain LoRA for important layers and the LoRA of the other layers share the same parameters. Abundant experiments on NLU and NLG tasks demonstrate the effectiveness of LoRA-drop.