 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialFly: Geometry-Guided Representation Alignment for UAV Vision-and-Language Navigation in Urban Environments
Mar 22, 2026UAVs play an important role in applications such as autonomous exploration, disaster response, and infrastructure inspection. However, UAV VLN in complex 3D environments remains challenging. A key difficulty is the structural representation mismatch between 2D visual perception and the 3D trajectory decision space, which limits spatial reasoning. To this end, we propose SpatialFly, a geometry-guided spatial representation framework for UAV VLN. Operating on RGB observations without explicit 3D reconstruction, SpatialFly introduces a geometry-guided 2D representation alignment mechanism. Specifically, the geometric prior injection module injects global structural cues into 2D semantic tokens to provide scene-level geometric guidance. The geometry-aware reparameterization module then aligns 2D semantic tokens with 3D geometric tokens through cross-modal attention, followed by gated residual fusion to preserve semantic discrimination. Experimental results show that SpatialFly consistently outperforms state-of-the-art UAV VLN baselines across both seen and unseen environments, reducing NE by 4.03m and improving SR by 1.27% over the strongest baseline on the unseen Full split. Additional trajectory-level analysis shows that SpatialFly produces trajectories with better path alignment and smoother, more stable motion.
Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
Mar 13, 2026A recent cutting-edge topic in multimodal modeling is to unify visual comprehension and generation within a single model. However, the two tasks demand mismatched decoding regimes and visual representations, making it non-trivial to jointly optimize within a shared feature space. In this work, we present Cheers, a unified multimodal model that decouples patch-level details from semantic representations, thereby stabilizing semantics for multimodal understanding and improving fidelity for image generation via gated detail residuals. Cheers includes three key components: (i) a unified vision tokenizer that encodes and compresses image latent states into semantic tokens for efficient LLM conditioning, (ii) an LLM-based Transformer that unifies autoregressive decoding for text generation and diffusion decoding for image generation, and (iii) a cascaded flow matching head that decodes visual semantics first and then injects semantically gated detail residuals from the vision tokenizer to refine high-frequency content. Experiments on popular benchmarks demonstrate that Cheers matches or surpasses advanced UMMs in both visual understanding and generation. Cheers also achieves 4x token compression, enabling more efficient high-resolution image encoding and generation. Notably, Cheers outperforms the Tar-1.5B on the popular benchmarks GenEval and MMBench, while requiring only 20% of the training cost, indicating effective and efficient (i.e., 4x token compression) unified multimodal modeling. We will release all code and data for future research.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
MM-UAVBench: How Well Do Multimodal Large Language Models See, Think, and Plan in Low-Altitude UAV Scenarios?
Dec 29, 2025While Multimodal Large Language Models (MLLMs) have exhibited remarkable general intelligence across diverse domains, their potential in low-altitude applications dominated by Unmanned Aerial Vehicles (UAVs) remains largely underexplored. Existing MLLM benchmarks rarely cover the unique challenges of low-altitude scenarios, while UAV-related evaluations mainly focus on specific tasks such as localization or navigation, without a unified evaluation of MLLMs'general intelligence. To bridge this gap, we present MM-UAVBench, a comprehensive benchmark that systematically evaluates MLLMs across three core capability dimensions-perception, cognition, and planning-in low-altitude UAV scenarios. MM-UAVBench comprises 19 sub-tasks with over 5.7K manually annotated questions, all derived from real-world UAV data collected from public datasets. Extensive experiments on 16 open-source and proprietary MLLMs reveal that current models struggle to adapt to the complex visual and cognitive demands of low-altitude scenarios. Our analyses further uncover critical bottlenecks such as spatial bias and multi-view understanding that hinder the effective deployment of MLLMs in UAV scenarios. We hope MM-UAVBench will foster future research on robust and reliable MLLMs for real-world UAV intelligence.
Speculative Decoding Meets Quantization: Compatibility Evaluation and Hierarchical Framework Design
May 29, 2025Speculative decoding and quantization effectively accelerate memory-bound inference of large language models. Speculative decoding mitigates the memory bandwidth bottleneck by verifying multiple tokens within a single forward pass, which increases computational effort. Quantization achieves this optimization by compressing weights and activations into lower bit-widths and also reduces computations via low-bit matrix multiplications. To further leverage their strengths, we investigate the integration of these two techniques. Surprisingly, experiments applying the advanced speculative decoding method EAGLE-2 to various quantized models reveal that the memory benefits from 4-bit weight quantization are diminished by the computational load from speculative decoding. Specifically, verifying a tree-style draft incurs significantly more time overhead than a single-token forward pass on 4-bit weight quantized models. This finding led to our new speculative decoding design: a hierarchical framework that employs a small model as an intermediate stage to turn tree-style drafts into sequence drafts, leveraging the memory access benefits of the target quantized model. Experimental results show that our hierarchical approach achieves a 2.78$\times$ speedup across various tasks for the 4-bit weight Llama-3-70B model on an A100 GPU, outperforming EAGLE-2 by 1.31$\times$. Code available at https://github.com/AI9Stars/SpecMQuant.
Enabling Real-Time Conversations with Minimal Training Costs
Sep 18, 2024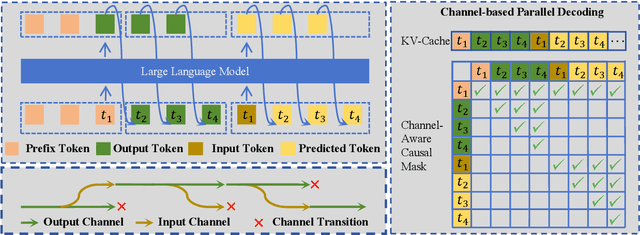
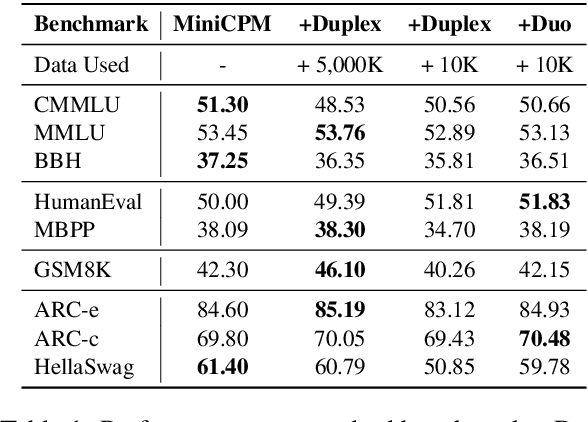
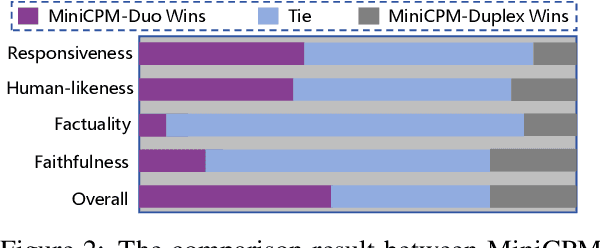
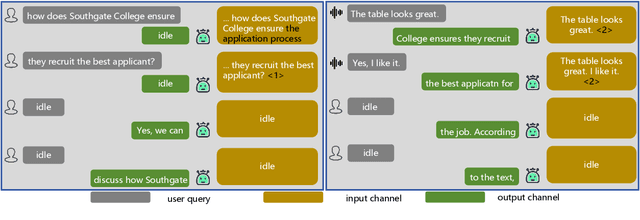
Large language models (LLMs) have demonstrated the ability to improve human efficiency through conversational interactions. Conventional LLM-powered dialogue systems, operating on a turn-based paradigm, preclude real-time interaction during response generation. To address this limitation, researchers have proposed duplex models. These models can dynamically adapt to user input, facilitating real-time interactive feedback. However, these methods typically require substantial computational resources to acquire the ability. To reduce overhead, this paper presents a new duplex decoding approach that enhances LLMs with duplex ability, requiring minimal additional training. Specifically, our method employs parallel decoding of queries and responses in conversations, effectively implementing a channel-division-multiplexing decoding strategy. Experimental results indicate that our proposed method significantly enhances the naturalness and human-likeness of user-AI interactions with minimal training costs.
PVF (Parameter Vulnerability Factor): A Quantitative Metric Measuring AI Vulnerability and Resilience Against Parameter Corruptions
May 02, 2024



Reliability of AI systems is a fundamental concern for the successful deployment and widespread adoption of AI technologies. Unfortunately, the escalating complexity and heterogeneity of AI hardware systems make them inevitably and increasingly susceptible to hardware faults (e.g., bit flips) that can potentially corrupt model parameters. Given this challenge, this paper aims to answer a critical question: How likely is a parameter corruption to result in an incorrect model output? To systematically answer this question, we propose a novel quantitative metric, Parameter Vulnerability Factor (PVF), inspired by architectural vulnerability factor (AVF) in computer architecture community, aiming to standardize the quantification of AI model resilience/vulnerability against parameter corruptions. We define a model parameter's PVF as the probability that a corruption in that particular model parameter will result in an incorrect output. Similar to AVF, this statistical concept can be derived from statistically extensive and meaningful fault injection (FI) experiments. In this paper, we present several use cases on applying PVF to three types of tasks/models during inference -- recommendation (DLRM), vision classification (CNN), and text classification (BERT). PVF can provide pivotal insights to AI hardware designers in balancing the tradeoff between fault protection and performance/efficiency such as mapping vulnerable AI parameter components to well-protected hardware modules. PVF metric is applicable to any AI model and has a potential to help unify and standardize AI vulnerability/resilience evaluation practice.
LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation
Feb 12, 2024
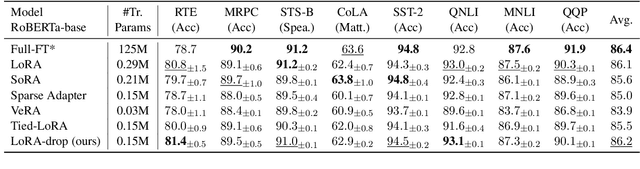

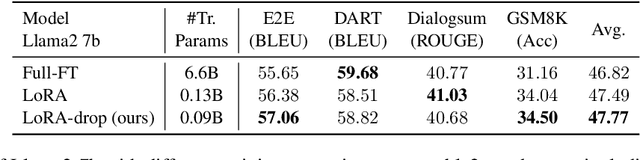
Low-Rank Adaptation (LoRA) introduces auxiliary parameters for each layer to fine-tune the pre-trained model under limited computing resources. But it still faces challenges of resource consumption when scaling up to larger models. Previous studies employ pruning techniques by evaluating the importance of LoRA parameters for different layers to address the problem. However, these efforts only analyzed parameter features to evaluate their importance. Indeed, the output of LoRA related to the parameters and data is the factor that directly impacts the frozen model. To this end, we propose LoRA-drop which evaluates the importance of the parameters by analyzing the LoRA output. We retain LoRA for important layers and the LoRA of the other layers share the same parameters. Abundant experiments on NLU and NLG tasks demonstrate the effectiveness of LoRA-drop.
Chinese Fine-Grained Financial Sentiment Analysis with Large Language Models
Jul 06, 2023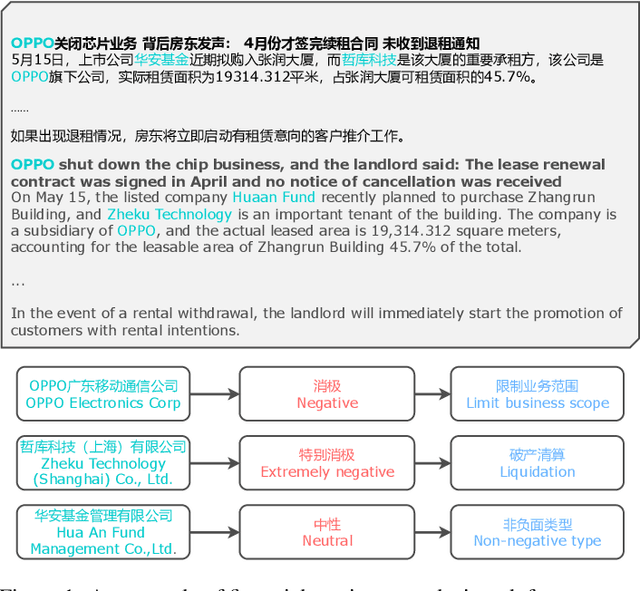
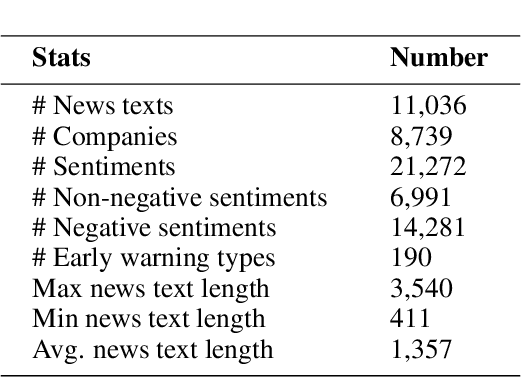
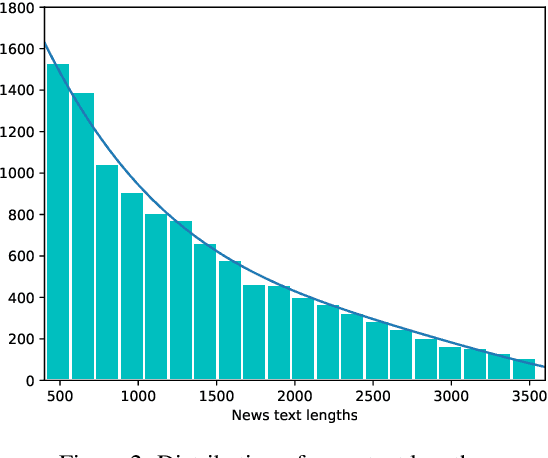
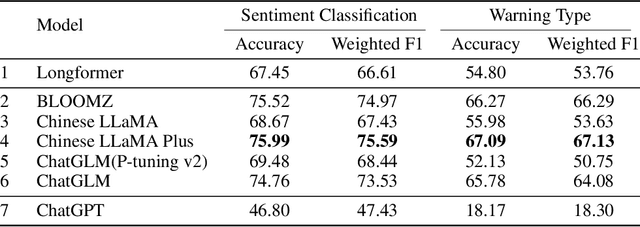
Entity-level fine-grained sentiment analysis in the financial domain is a crucial subtask of sentiment analysis and currently faces numerous challenges. The primary challenge stems from the lack of high-quality and large-scale annotated corpora specifically designed for financial text sentiment analysis, which in turn limits the availability of data necessary for developing effective text processing techniques. Recent advancements in large language models (LLMs) have yielded remarkable performance in natural language processing tasks, primarily centered around language pattern matching. In this paper, we propose a novel and extensive Chinese fine-grained financial sentiment analysis dataset, FinChina SA, for enterprise early warning. We thoroughly evaluate and experiment with well-known existing open-source LLMs using our dataset. We firmly believe that our dataset will serve as a valuable resource to advance the exploration of real-world financial sentiment analysis tasks, which should be the focus of future research. Our dataset and all code to replicate the experimental results will be released.
Document-Level Relation Extraction with Sentences Importance Estimation and Focusing
Apr 27, 2022
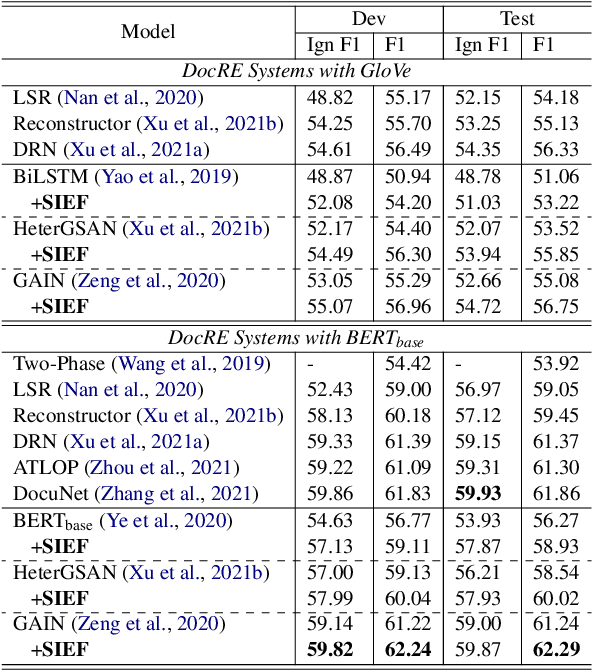
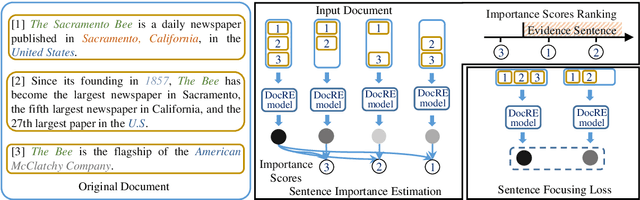
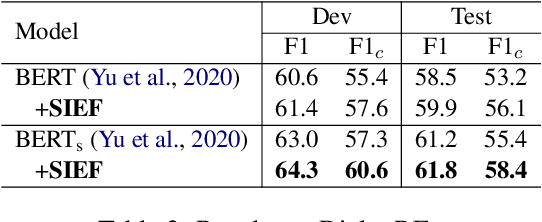
Document-level relation extraction (DocRE) aims to determine the relation between two entities from a document of multiple sentences. Recent studies typically represent the entire document by sequence- or graph-based models to predict the relations of all entity pairs. However, we find that such a model is not robust and exhibits bizarre behaviors: it predicts correctly when an entire test document is fed as input, but errs when non-evidence sentences are removed. To this end, we propose a Sentence Importance Estimation and Focusing (SIEF) framework for DocRE, where we design a sentence importance score and a sentence focusing loss, encouraging DocRE models to focus on evidence sentences. Experimental results on two domains show that our SIEF not only improves overall performance, but also makes DocRE models more robust. Moreover, SIEF is a general framework, shown to be effective when combined with a variety of base DocRE models.