 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese Fine-Grained Financial Sentiment Analysis with Large Language Models
Jul 06, 2023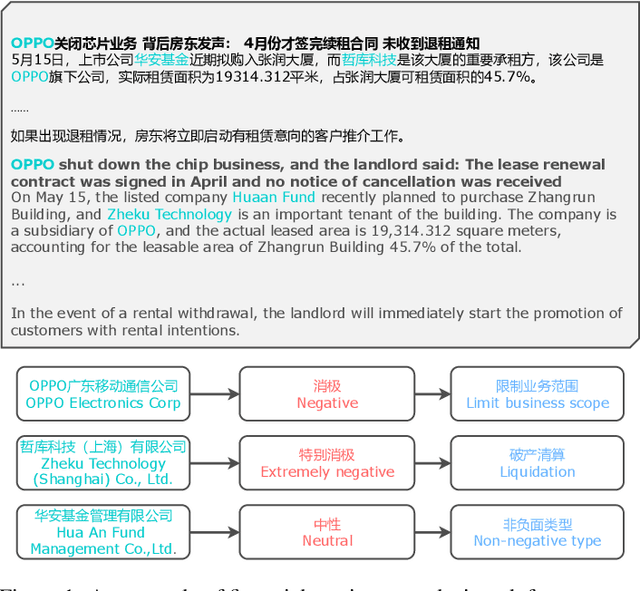
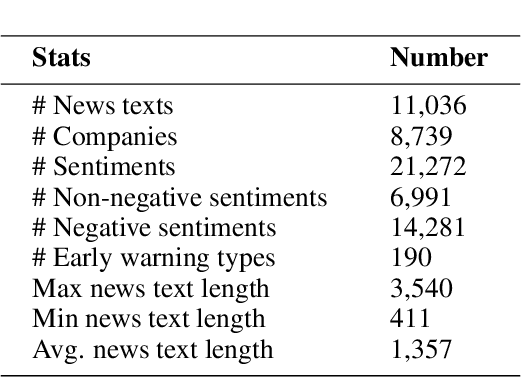
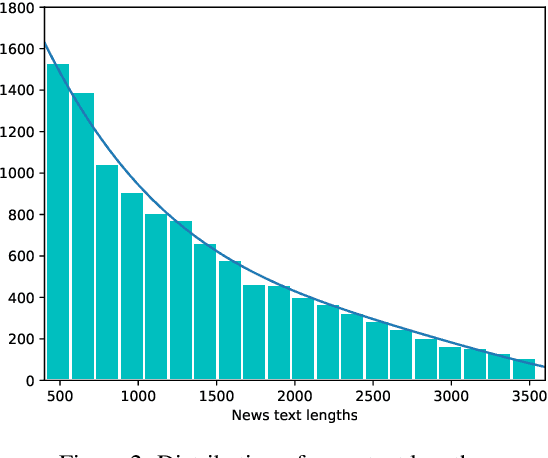
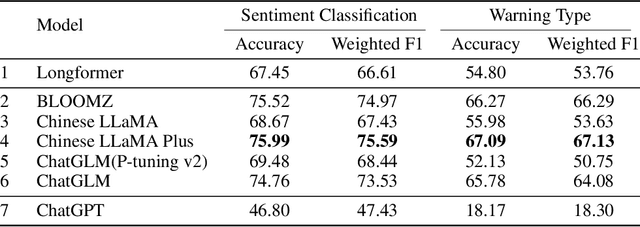
Entity-level fine-grained sentiment analysis in the financial domain is a crucial subtask of sentiment analysis and currently faces numerous challenges. The primary challenge stems from the lack of high-quality and large-scale annotated corpora specifically designed for financial text sentiment analysis, which in turn limits the availability of data necessary for developing effective text processing techniques. Recent advancements in large language models (LLMs) have yielded remarkable performance in natural language processing tasks, primarily centered around language pattern matching. In this paper, we propose a novel and extensive Chinese fine-grained financial sentiment analysis dataset, FinChina SA, for enterprise early warning. We thoroughly evaluate and experiment with well-known existing open-source LLMs using our dataset. We firmly believe that our dataset will serve as a valuable resource to advance the exploration of real-world financial sentiment analysis tasks, which should be the focus of future research. Our dataset and all code to replicate the experimental results will be released.
Knowledge Reasoning via Jointly Modeling Knowledge Graphs and Soft Rules
Jan 07, 2023Knowledge graphs (KGs) play a crucial role in many applications, such as question answering, but incompleteness is an urgent issue for their broad application. Much research in knowledge graph completion (KGC) has been performed to resolve this issue. The methods of KGC can be classified into two major categories: rule-based reasoning and embedding-based reasoning. The former has high accuracy and good interpretability, but a major challenge is to obtain effective rules on large-scale KGs. The latter has good efficiency and scalability, but it relies heavily on data richness and cannot fully use domain knowledge in the form of logical rules. We propose a novel method that injects rules and learns representations iteratively to take full advantage of rules and embeddings. Specifically, we model the conclusions of rule groundings as 0-1 variables and use a rule confidence regularizer to remove the uncertainty of the conclusions. The proposed approach has the following advantages: 1) It combines the benefits of both rules and knowledge graph embeddings (KGEs) and achieves a good balance between efficiency and scalability. 2) It uses an iterative method to continuously improve KGEs and remove incorrect rule conclusions. Evaluations on two public datasets show that our method outperforms the current state-of-the-art methods, improving performance by 2.7\% and 4.3\% in mean reciprocal rank (MRR).
Path-based knowledge reasoning with textual semantic information for medical knowledge graph completion
May 28, 2021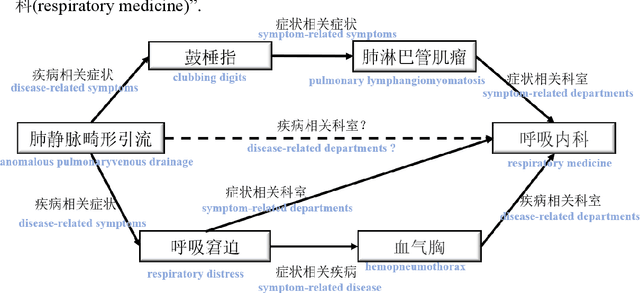

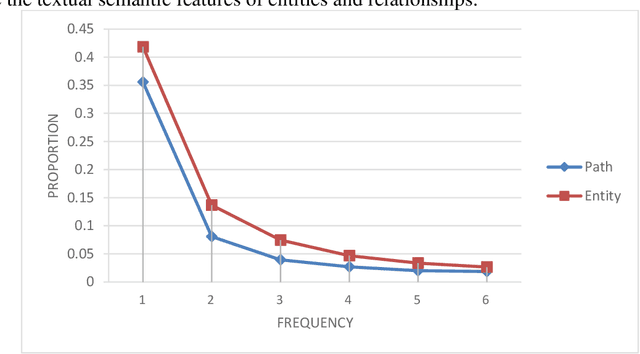

Background Knowledge graphs (KGs), especially medical knowledge graphs, are often significantly incomplete, so it necessitating a demand for medical knowledge graph completion (MedKGC). MedKGC can find new facts based on the exited knowledge in the KGs. The path-based knowledge reasoning algorithm is one of the most important approaches to this task. This type of method has received great attention in recent years because of its high performance and interpretability. In fact, traditional methods such as path ranking algorithm (PRA) take the paths between an entity pair as atomic features. However, the medical KGs are very sparse, which makes it difficult to model effective semantic representation for extremely sparse path features. The sparsity in the medical KGs is mainly reflected in the long-tailed distribution of entities and paths. Previous methods merely consider the context structure in the paths of the knowledge graph and ignore the textual semantics of the symbols in the path. Therefore, their performance cannot be further improved due to the two aspects of entity sparseness and path sparseness. To address the above issues, this paper proposes two novel path-based reasoning methods to solve the sparsity issues of entity and path respectively, which adopts the textual semantic information of entities and paths for MedKGC. By using the pre-trained model BERT, combining the textual semantic representations of the entities and the relationships, we model the task of symbolic reasoning in the medical KG as a numerical computing issue in textual semantic representation.