 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese Fine-Grained Financial Sentiment Analysis with Large Language Models
Jul 06, 2023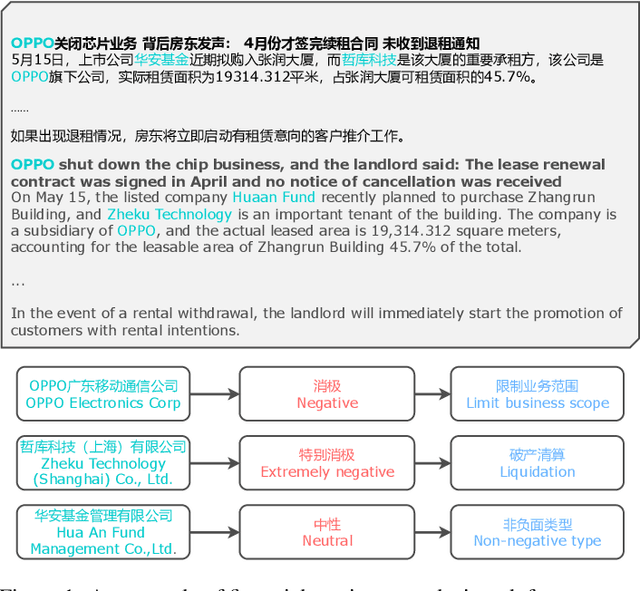
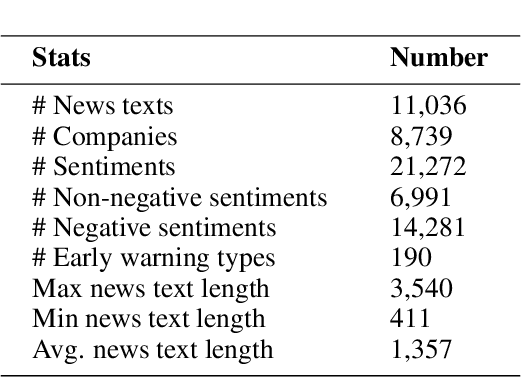
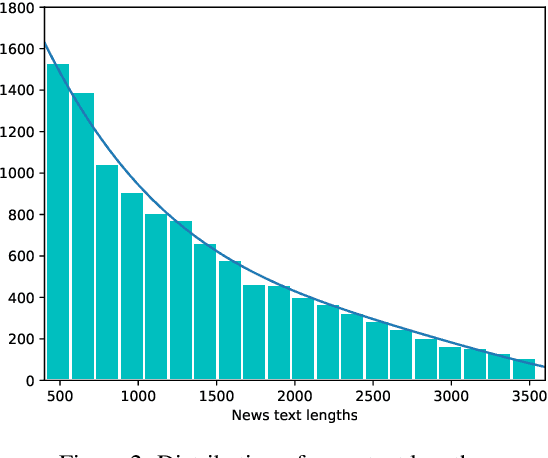
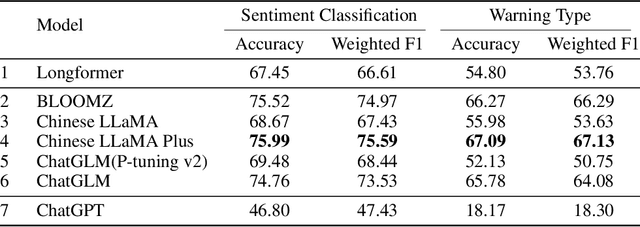
Entity-level fine-grained sentiment analysis in the financial domain is a crucial subtask of sentiment analysis and currently faces numerous challenges. The primary challenge stems from the lack of high-quality and large-scale annotated corpora specifically designed for financial text sentiment analysis, which in turn limits the availability of data necessary for developing effective text processing techniques. Recent advancements in large language models (LLMs) have yielded remarkable performance in natural language processing tasks, primarily centered around language pattern matching. In this paper, we propose a novel and extensive Chinese fine-grained financial sentiment analysis dataset, FinChina SA, for enterprise early warning. We thoroughly evaluate and experiment with well-known existing open-source LLMs using our dataset. We firmly believe that our dataset will serve as a valuable resource to advance the exploration of real-world financial sentiment analysis tasks, which should be the focus of future research. Our dataset and all code to replicate the experimental results will be released.