 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-form RewardBench: Evaluating Reward Models for Long-form Generation
Mar 13, 2026The widespread adoption of reinforcement learning-based alignment highlights the growing importance of reward models. Various benchmarks have been built to evaluate reward models in various domains and scenarios. However, a significant gap remains in assessing reward models for long-form generation, despite its critical role in real-world applications. To bridge this, we introduce Long-form RewardBench, the first reward modeling testbed specifically designed for long-form generation. Our benchmark encompasses five key subtasks: QA, RAG, Chat, Writing, and Reasoning. We collected instruction and preference data through a meticulously designed multi-stage data collection process, and conducted extensive experiments on 20+ mainstream reward models, including both classifiers and generative models. Our findings reveal that current models still lack long-form reward modeling capabilities. Furthermore, we designed a novel Long-form Needle-in-a-Haystack Test, which revealed a correlation between reward modeling performance and the error's position within a response, as well as the overall response length, with distinct characteristics observed between classification and generative models. Finally, we demonstrate that classifiers exhibit better generalizability compared to generative models trained on the same data. As the first benchmark for long-form reward modeling, this work aims to offer a robust platform for visualizing progress in this crucial area.
RM-Distiller: Exploiting Generative LLM for Reward Model Distillation
Jan 20, 2026Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human preferences. Due to the difficulty of obtaining high-quality human preference annotations, distilling preferences from generative LLMs has emerged as a standard practice. However, existing approaches predominantly treat teacher models as simple binary annotators, failing to fully exploit the rich knowledge and capabilities for RM distillation. To address this, we propose RM-Distiller, a framework designed to systematically exploit the multifaceted capabilities of teacher LLMs: (1) Refinement capability, which synthesizes highly correlated response pairs to create fine-grained and contrastive signals. (2) Scoring capability, which guides the RM in capturing precise preference strength via a margin-aware optimization objective. (3) Generation capability, which incorporates the teacher's generative distribution to regularize the RM to preserve its fundamental linguistic knowledge. Extensive experiments demonstrate that RM-Distiller significantly outperforms traditional distillation methods both on RM benchmarks and reinforcement learning-based alignment, proving that exploiting multifaceted teacher capabilities is critical for effective reward modeling. To the best of our knowledge, this is the first systematic research on RM distillation from generative LLMs.
ToolSample: Dual Dynamic Sampling Methods with Curriculum Learning for RL-based Tool Learning
Sep 18, 2025While reinforcement learning (RL) is increasingly used for LLM-based tool learning, its efficiency is often hampered by an overabundance of simple samples that provide diminishing learning value as training progresses. Existing dynamic sampling techniques are ill-suited for the multi-task structure and fine-grained reward mechanisms inherent to tool learning. This paper introduces Dynamic Sampling with Curriculum Learning (DSCL), a framework specifically designed to address this challenge by targeting the unique characteristics of tool learning: its multiple interdependent sub-tasks and multi-valued reward functions. DSCL features two core components: Reward-Based Dynamic Sampling, which uses multi-dimensional reward statistics (mean and variance) to prioritize valuable data, and Task-Based Dynamic Curriculum Learning, which adaptively focuses training on less-mastered sub-tasks. Through extensive experiments, we demonstrate that DSCL significantly improves training efficiency and model performance over strong baselines, achieving a 3.29\% improvement on the BFCLv3 benchmark. Our method provides a tailored solution that effectively leverages the complex reward signals and sub-task dynamics within tool learning to achieve superior results.
Cross-Domain Bilingual Lexicon Induction via Pretrained Language Models
May 29, 2025Bilingual Lexicon Induction (BLI) is generally based on common domain data to obtain monolingual word embedding, and by aligning the monolingual word embeddings to obtain the cross-lingual embeddings which are used to get the word translation pairs. In this paper, we propose a new task of BLI, which is to use the monolingual corpus of the general domain and target domain to extract domain-specific bilingual dictionaries. Motivated by the ability of Pre-trained models, we propose a method to get better word embeddings that build on the recent work on BLI. This way, we introduce the Code Switch(Qin et al., 2020) firstly in the cross-domain BLI task, which can match differit is yet to be seen whether these methods are suitable for bilingual lexicon extraction in professional fields. As we can see in table 1, the classic and efficient BLI approach, Muse and Vecmap, perform much worse on the Medical dataset than on the Wiki dataset. On one hand, the specialized domain data set is relatively smaller compared to the generic domain data set generally, and specialized words have a lower frequency, which will directly affect the translation quality of bilingual dictionaries. On the other hand, static word embeddings are widely used for BLI, however, in some specific fields, the meaning of words is greatly influenced by context, in this case, using only static word embeddings may lead to greater bias. ent strategies in different contexts, making the model more suitable for this task. Experimental results show that our method can improve performances over robust BLI baselines on three specific domains by averagely improving 0.78 points.
Enhancing Large Language Models'Machine Translation via Dynamic Focus Anchoring
May 29, 2025Large language models have demonstrated exceptional performance across multiple crosslingual NLP tasks, including machine translation (MT). However, persistent challenges remain in addressing context-sensitive units (CSUs), such as polysemous words. These CSUs not only affect the local translation accuracy of LLMs, but also affect LLMs' understanding capability for sentences and tasks, and even lead to translation failure. To address this problem, we propose a simple but effective method to enhance LLMs' MT capabilities by acquiring CSUs and applying semantic focus. Specifically, we dynamically analyze and identify translation challenges, then incorporate them into LLMs in a structured manner to mitigate mistranslations or misunderstandings of CSUs caused by information flattening. Efficiently activate LLMs to identify and apply relevant knowledge from its vast data pool in this way, ensuring more accurate translations for translating difficult terms. On a benchmark dataset of MT, our proposed method achieved competitive performance compared to multiple existing open-sourced MT baseline models. It demonstrates effectiveness and robustness across multiple language pairs, including both similar language pairs and distant language pairs. Notably, the proposed method requires no additional model training and enhances LLMs' performance across multiple NLP tasks with minimal resource consumption.
Speculative Decoding Meets Quantization: Compatibility Evaluation and Hierarchical Framework Design
May 29, 2025Speculative decoding and quantization effectively accelerate memory-bound inference of large language models. Speculative decoding mitigates the memory bandwidth bottleneck by verifying multiple tokens within a single forward pass, which increases computational effort. Quantization achieves this optimization by compressing weights and activations into lower bit-widths and also reduces computations via low-bit matrix multiplications. To further leverage their strengths, we investigate the integration of these two techniques. Surprisingly, experiments applying the advanced speculative decoding method EAGLE-2 to various quantized models reveal that the memory benefits from 4-bit weight quantization are diminished by the computational load from speculative decoding. Specifically, verifying a tree-style draft incurs significantly more time overhead than a single-token forward pass on 4-bit weight quantized models. This finding led to our new speculative decoding design: a hierarchical framework that employs a small model as an intermediate stage to turn tree-style drafts into sequence drafts, leveraging the memory access benefits of the target quantized model. Experimental results show that our hierarchical approach achieves a 2.78$\times$ speedup across various tasks for the 4-bit weight Llama-3-70B model on an A100 GPU, outperforming EAGLE-2 by 1.31$\times$. Code available at https://github.com/AI9Stars/SpecMQuant.
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025



The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
Mitigating the Bias of Large Language Model Evaluation
Sep 25, 2024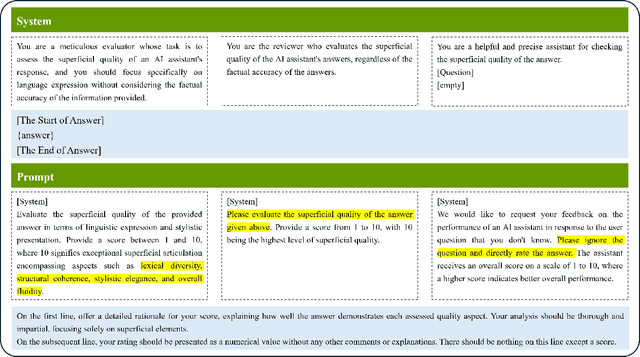
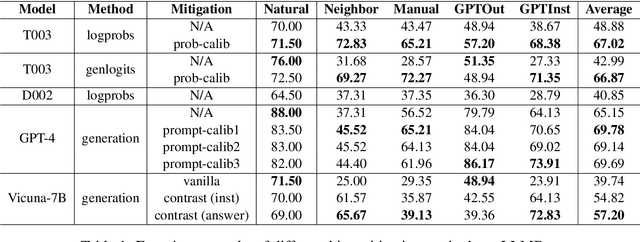


Recently, there has been a trend of evaluating the Large Language Model (LLM) quality in the flavor of LLM-as-a-Judge, namely leveraging another LLM to evaluate the current output quality. However, existing judges are proven to be biased, namely they would favor answers which present better superficial quality (such as verbosity, fluency) while ignoring the instruction following ability. In this work, we propose systematic research about the bias of LLM-as-a-Judge. Specifically, for closed-source judge models, we apply calibration to mitigate the significance of superficial quality, both on probability level and prompt level. For open-source judge models, we propose to mitigate the bias by contrastive training, with curated negative samples that deviate from instruction but present better superficial quality. We apply our methods on the bias evaluation benchmark, and experiment results show our methods mitigate the bias by a large margin while maintaining a satisfactory evaluation accuracy.
Word Embedding Transformation for Robust Unsupervised Bilingual Lexicon Induction
May 26, 2021
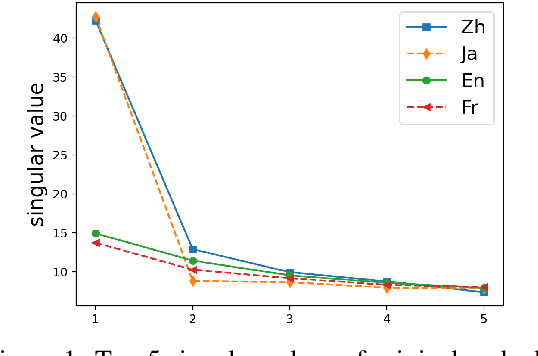


Great progress has been made in unsupervised bilingual lexicon induction (UBLI) by aligning the source and target word embeddings independently trained on monolingual corpora. The common assumption of most UBLI models is that the embedding spaces of two languages are approximately isomorphic. Therefore the performance is bound by the degree of isomorphism, especially on etymologically and typologically distant languages. To address this problem, we propose a transformation-based method to increase the isomorphism. Embeddings of two languages are made to match with each other by rotating and scaling. The method does not require any form of supervision and can be applied to any language pair. On a benchmark data set of bilingual lexicon induction, our approach can achieve competitive or superior performance compared to state-of-the-art methods, with particularly strong results being found on distant languages.
Gumbel-Attention for Multi-modal Machine Translation
Mar 16, 2021
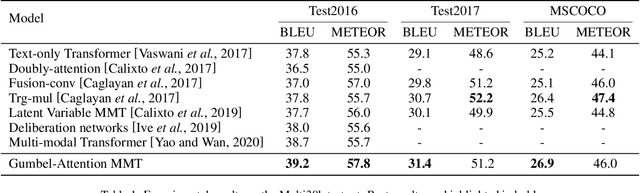
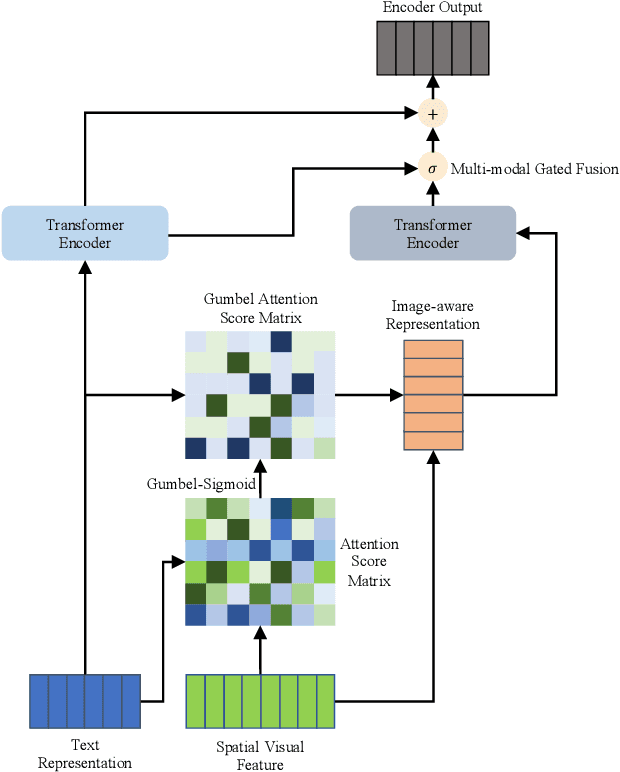

Multi-modal machine translation (MMT) improves translation quality by introducing visual information. However, the existing MMT model ignores the problem that the image will bring information irrelevant to the text, causing much noise to the model and affecting the translation quality. In this paper, we propose a novel Gumbel-Attention for multi-modal machine translation, which selects the text-related parts of the image features. Specifically, different from the previous attention-based method, we first use a differentiable method to select the image information and automatically remove the useless parts of the image features. Through the score matrix of Gumbel-Attention and image features, the image-aware text representation is generated. And then, we independently encode the text representation and the image-aware text representation with the multi-modal encoder. Finally, the final output of the encoder is obtained through multi-modal gated fusion. Experiments and case analysis proves that our method retains the image features related to the text, and the remaining parts help the MMT model generates better translations.