 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFL-Tuning: Layer Tuning for Feed-Forward Network in Transformer
Jun 30, 2022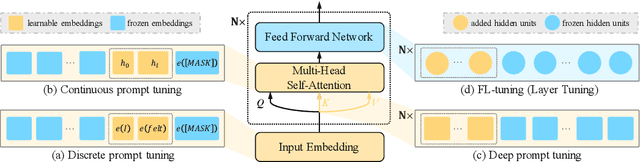
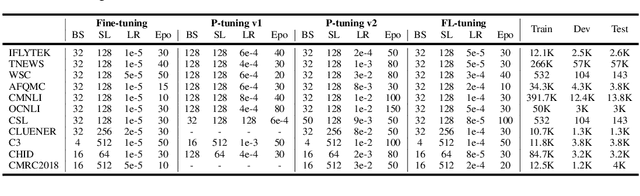
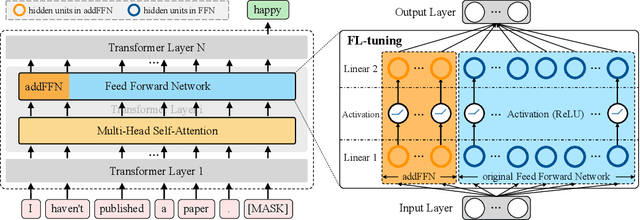
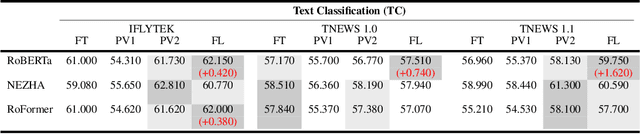
Prompt tuning is an emerging way of adapting pre-trained language models to downstream tasks. However, the existing studies are mainly to add prompts to the input sequence. This way would not work as expected due to the intermediate multi-head self-attention and feed-forward network computation, making model optimization not very smooth. Hence, we propose a novel tuning way called layer tuning, aiming to add learnable parameters in Transformer layers. Specifically, we focus on layer tuning for feed-forward network in the Transformer, namely FL-tuning. It introduces additional units into the hidden layer of each feed-forward network. We conduct extensive experiments on the public CLUE benchmark. The results show that: 1) Our FL-tuning outperforms prompt tuning methods under both full-data and few-shot settings in almost all cases. In particular, it improves accuracy by 17.93% (full-data setting) on WSC 1.0 and F1 by 16.142% (few-shot setting) on CLUENER over P-tuning v2. 2) Our FL-tuning is more stable and converges about 1.17 times faster than P-tuning v2. 3) With only about 3% of Transformer's parameters to be trained, FL-tuning is comparable with fine-tuning on most datasets, and significantly outperforms fine-tuning (e.g., accuracy improved by 12.9% on WSC 1.1) on several datasets. The source codes are available at https://github.com/genggui001/FL-Tuning.