 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeNTi: Bridging Medical Calculator and LLM Agent with Nested Tool Calling
Oct 17, 2024
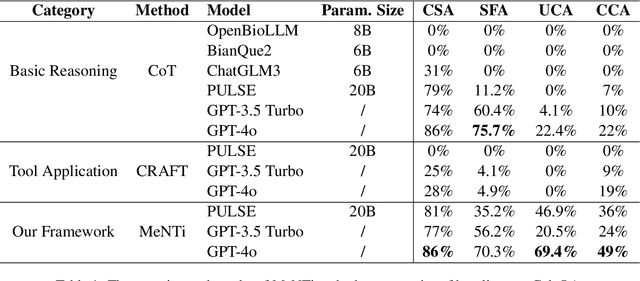
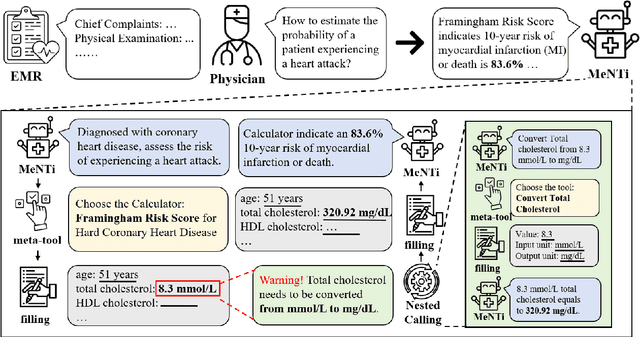
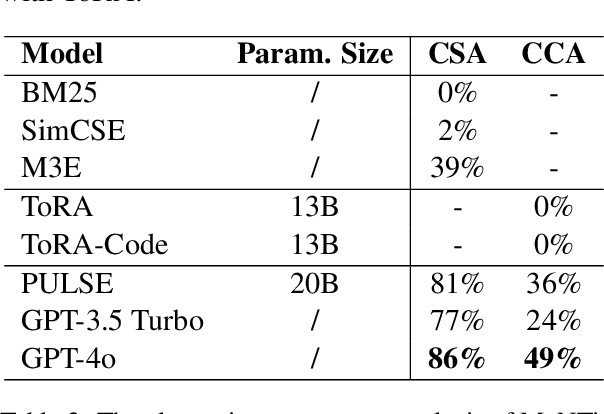
Integrating tools into Large Language Models (LLMs) has facilitated the widespread application. Despite this, in specialized downstream task contexts, reliance solely on tools is insufficient to fully address the complexities of the real world. This particularly restricts the effective deployment of LLMs in fields such as medicine. In this paper, we focus on the downstream tasks of medical calculators, which use standardized tests to assess an individual's health status. We introduce MeNTi, a universal agent architecture for LLMs. MeNTi integrates a specialized medical toolkit and employs meta-tool and nested calling mechanisms to enhance LLM tool utilization. Specifically, it achieves flexible tool selection and nested tool calling to address practical issues faced in intricate medical scenarios, including calculator selection, slot filling, and unit conversion. To assess the capabilities of LLMs for quantitative assessment throughout the clinical process of calculator scenarios, we introduce CalcQA. This benchmark requires LLMs to use medical calculators to perform calculations and assess patient health status. CalcQA is constructed by professional physicians and includes 100 case-calculator pairs, complemented by a toolkit of 281 medical tools. The experimental results demonstrate significant performance improvements with our framework. This research paves new directions for applying LLMs in demanding scenarios of medicine.
MedOdyssey: A Medical Domain Benchmark for Long Context Evaluation Up to 200K Tokens
Jun 21, 2024Numerous advanced Large Language Models (LLMs) now support context lengths up to 128K, and some extend to 200K. Some benchmarks in the generic domain have also followed up on evaluating long-context capabilities. In the medical domain, tasks are distinctive due to the unique contexts and need for domain expertise, necessitating further evaluation. However, despite the frequent presence of long texts in medical scenarios, evaluation benchmarks of long-context capabilities for LLMs in this field are still rare. In this paper, we propose MedOdyssey, the first medical long-context benchmark with seven length levels ranging from 4K to 200K tokens. MedOdyssey consists of two primary components: the medical-context "needles in a haystack" task and a series of tasks specific to medical applications, together comprising 10 datasets. The first component includes challenges such as counter-intuitive reasoning and novel (unknown) facts injection to mitigate knowledge leakage and data contamination of LLMs. The second component confronts the challenge of requiring professional medical expertise. Especially, we design the ``Maximum Identical Context'' principle to improve fairness by guaranteeing that different LLMs observe as many identical contexts as possible. Our experiment evaluates advanced proprietary and open-source LLMs tailored for processing long contexts and presents detailed performance analyses. This highlights that LLMs still face challenges and need for further research in this area. Our code and data are released in the repository: \url{https://github.com/JOHNNY-fans/MedOdyssey.}
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Apr 27, 2024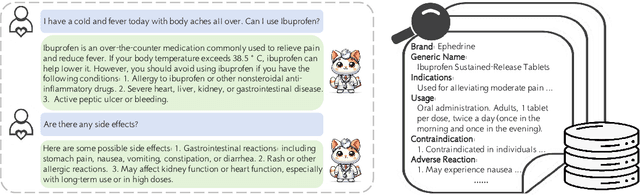

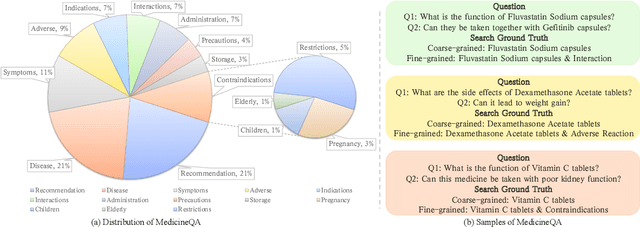
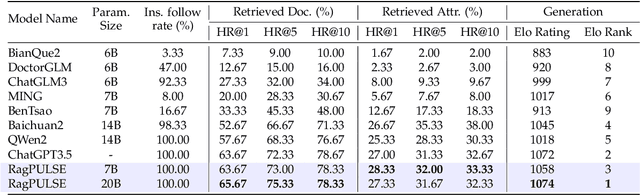
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new \textit{Distill-Retrieve-Read} framework instead of the previous \textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
MidMed: Towards Mixed-Type Dialogues for Medical Consultation
Jun 14, 2023



Most medical dialogue systems assume that patients have clear goals (medicine querying, surgical operation querying, etc.) before medical consultation. However, in many real scenarios, due to the lack of medical knowledge, it is usually difficult for patients to determine clear goals with all necessary slots. In this paper, we identify this challenge as how to construct medical consultation dialogue systems to help patients clarify their goals. To mitigate this challenge, we propose a novel task and create a human-to-human mixed-type medical consultation dialogue corpus, termed MidMed, covering five dialogue types: task-oriented dialogue for diagnosis, recommendation, knowledge-grounded dialogue, QA, and chitchat. MidMed covers four departments (otorhinolaryngology, ophthalmology, skin, and digestive system), with 8,175 dialogues. Furthermore, we build baselines on MidMed and propose an instruction-guiding medical dialogue generation framework, termed InsMed, to address this task. Experimental results show the effectiveness of InsMed.
CBEAF-Adapting: Enhanced Continual Pretraining for Building Chinese Biomedical Language Model
Nov 21, 2022Continual pretraining is a standard way of building a domain-specific pretrained language model from a general-domain language model. However, sequential task training may cause catastrophic forgetting, which affects the model performance in downstream tasks. In this paper, we propose a continual pretraining method for the BERT-based model, named CBEAF-Adapting (Chinese Biomedical Enhanced Attention-FFN Adapting). Its main idea is to introduce a small number of attention heads and hidden units inside each self-attention layer and feed-forward network. Using the Chinese biomedical domain as a running example, we trained a domain-specific language model named CBEAF-RoBERTa. We conduct experiments by applying models to downstream tasks. The results demonstrate that with only about 3% of model parameters trained, our method could achieve about 0.5%, 2% average performance gain compared to the best performing model in baseline and the domain-specific model, PCL-MedBERT, respectively. We also examine the forgetting problem of different pretraining methods. Our method alleviates the problem by about 13% compared to fine-tuning.
FL-Tuning: Layer Tuning for Feed-Forward Network in Transformer
Jun 30, 2022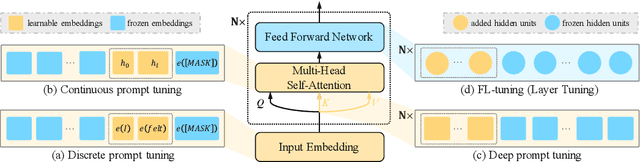
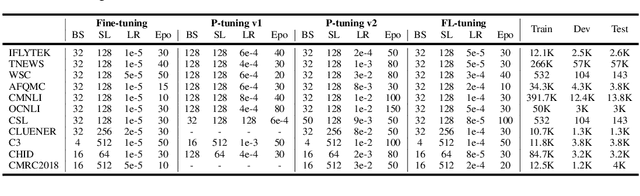
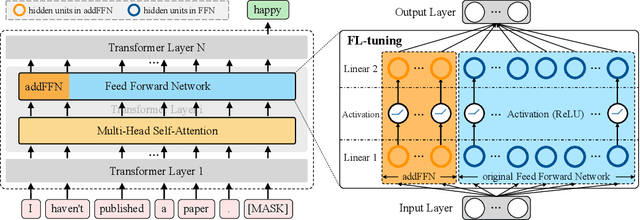
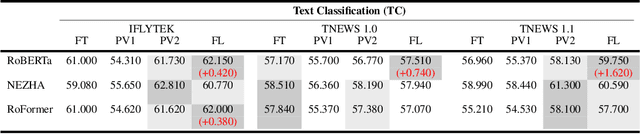
Prompt tuning is an emerging way of adapting pre-trained language models to downstream tasks. However, the existing studies are mainly to add prompts to the input sequence. This way would not work as expected due to the intermediate multi-head self-attention and feed-forward network computation, making model optimization not very smooth. Hence, we propose a novel tuning way called layer tuning, aiming to add learnable parameters in Transformer layers. Specifically, we focus on layer tuning for feed-forward network in the Transformer, namely FL-tuning. It introduces additional units into the hidden layer of each feed-forward network. We conduct extensive experiments on the public CLUE benchmark. The results show that: 1) Our FL-tuning outperforms prompt tuning methods under both full-data and few-shot settings in almost all cases. In particular, it improves accuracy by 17.93% (full-data setting) on WSC 1.0 and F1 by 16.142% (few-shot setting) on CLUENER over P-tuning v2. 2) Our FL-tuning is more stable and converges about 1.17 times faster than P-tuning v2. 3) With only about 3% of Transformer's parameters to be trained, FL-tuning is comparable with fine-tuning on most datasets, and significantly outperforms fine-tuning (e.g., accuracy improved by 12.9% on WSC 1.1) on several datasets. The source codes are available at https://github.com/genggui001/FL-Tuning.
A multi-perspective combined recall and rank framework for Chinese procedure terminology normalization
Jan 22, 2021


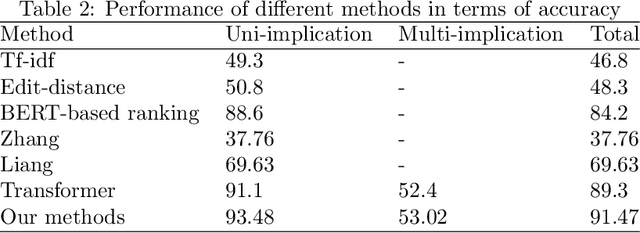
Medical terminology normalization aims to map the clinical mention to terminologies come from a knowledge base, which plays an important role in analyzing Electronic Health Record(EHR) and many downstream tasks. In this paper, we focus on Chinese procedure terminology normalization. The expression of terminologies are various and one medical mention may be linked to multiple terminologies. Previous study explores some methods such as multi-class classification or learning to rank(LTR) to sort the terminologies by literature and semantic information. However, these information is inadequate to find the right terminologies, particularly in multi-implication cases. In this work, we propose a combined recall and rank framework to solve the above problems. This framework is composed of a multi-task candidate generator(MTCG), a keywords attentive ranker(KAR) and a fusion block(FB). MTCG is utilized to predict the mention implication number and recall candidates with semantic similarity. KAR is based on Bert with a keywords attentive mechanism which focuses on keywords such as procedure sites and procedure types. FB merges the similarity come from MTCG and KAR to sort the terminologies from different perspectives. Detailed experimental analysis shows our proposed framework has a remarkable improvement on both performance and efficiency.
Fine-tuning BERT for Joint Entity and Relation Extraction in Chinese Medical Text
Aug 21, 2019

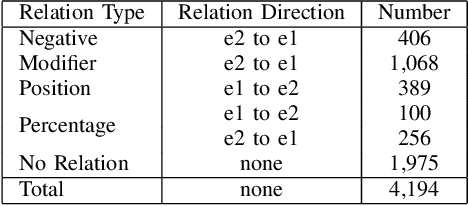
Entity and relation extraction is the necessary step in structuring medical text. However, the feature extraction ability of the bidirectional long short term memory network in the existing model does not achieve the best effect. At the same time, the language model has achieved excellent results in more and more natural language processing tasks. In this paper, we present a focused attention model for the joint entity and relation extraction task. Our model integrates well-known BERT language model into joint learning through dynamic range attention mechanism, thus improving the feature representation ability of shared parameter layer. Experimental results on coronary angiography texts collected from Shuguang Hospital show that the F1-score of named entity recognition and relation classification tasks reach 96.89% and 88.51%, which are better than state-of-the-art methods 1.65% and 1.22%, respectively.