 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch, Examine and Early-Termination: Fake News Detection with Annotation-Free Evidences
Jul 10, 2024Pioneer researches recognize evidences as crucial elements in fake news detection apart from patterns. Existing evidence-aware methods either require laborious pre-processing procedures to assure relevant and high-quality evidence data, or incorporate the entire spectrum of available evidences in all news cases, regardless of the quality and quantity of the retrieved data. In this paper, we propose an approach named \textbf{SEE} that retrieves useful information from web-searched annotation-free evidences with an early-termination mechanism. The proposed SEE is constructed by three main phases: \textbf{S}earching online materials using the news as a query and directly using their titles as evidences without any annotating or filtering procedure, sequentially \textbf{E}xamining the news alongside with each piece of evidence via attention mechanisms to produce new hidden states with retrieved information, and allowing \textbf{E}arly-termination within the examining loop by assessing whether there is adequate confidence for producing a correct prediction. We have conducted extensive experiments on datasets with unprocessed evidences, i.e., Weibo21, GossipCop, and pre-processed evidences, namely Snopes and PolitiFact. The experimental results demonstrate that the proposed method outperforms state-of-the-art approaches.
Fact-checking based fake news detection: a review
Jan 03, 2024This paper reviews and summarizes the research results on fact-based fake news from the perspectives of tasks and problems, algorithm strategies, and datasets. First, the paper systematically explains the task definition and core problems of fact-based fake news detection. Second, the paper summarizes the existing detection methods based on the algorithm principles. Third, the paper analyzes the classic and newly proposed datasets in the field, and summarizes the experimental results on each dataset. Finally, the paper summarizes the advantages and disadvantages of existing methods, proposes several challenges that methods in this field may face, and looks forward to the next stage of research. It is hoped that this paper will provide reference for subsequent work in the field.
Multi-modal Fake News Detection on Social Media via Multi-grained Information Fusion
Apr 03, 2023The easy sharing of multimedia content on social media has caused a rapid dissemination of fake news, which threatens society's stability and security. Therefore, fake news detection has garnered extensive research interest in the field of social forensics. Current methods primarily concentrate on the integration of textual and visual features but fail to effectively exploit multi-modal information at both fine-grained and coarse-grained levels. Furthermore, they suffer from an ambiguity problem due to a lack of correlation between modalities or a contradiction between the decisions made by each modality. To overcome these challenges, we present a Multi-grained Multi-modal Fusion Network (MMFN) for fake news detection. Inspired by the multi-grained process of human assessment of news authenticity, we respectively employ two Transformer-based pre-trained models to encode token-level features from text and images. The multi-modal module fuses fine-grained features, taking into account coarse-grained features encoded by the CLIP encoder. To address the ambiguity problem, we design uni-modal branches with similarity-based weighting to adaptively adjust the use of multi-modal features. Experimental results demonstrate that the proposed framework outperforms state-of-the-art methods on three prevalent datasets.
Robust Watermarking for Video Forgery Detection with Improved Imperceptibility and Robustness
Jul 07, 2022



Videos are prone to tampering attacks that alter the meaning and deceive the audience. Previous video forgery detection schemes find tiny clues to locate the tampered areas. However, attackers can successfully evade supervision by destroying such clues using video compression or blurring. This paper proposes a video watermarking network for tampering localization. We jointly train a 3D-UNet-based watermark embedding network and a decoder that predicts the tampering mask. The perturbation made by watermark embedding is close to imperceptible. Considering that there is no off-the-shelf differentiable video codec simulator, we propose to mimic video compression by ensembling simulation results of other typical attacks, e.g., JPEG compression and blurring, as an approximation. Experimental results demonstrate that our method generates watermarked videos with good imperceptibility and robustly and accurately locates tampered areas within the attacked version.
Multimodal Fake News Detection with Adaptive Unimodal Representation Aggregation
Jun 12, 2022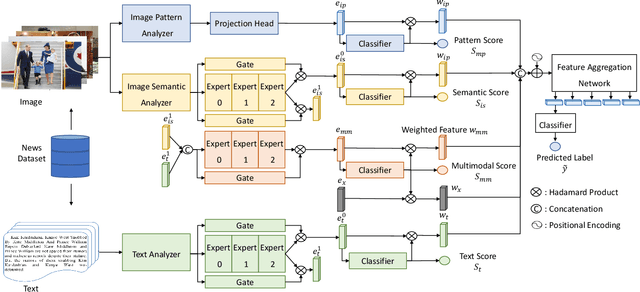
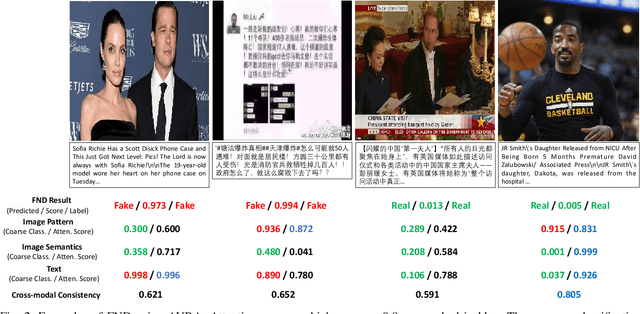
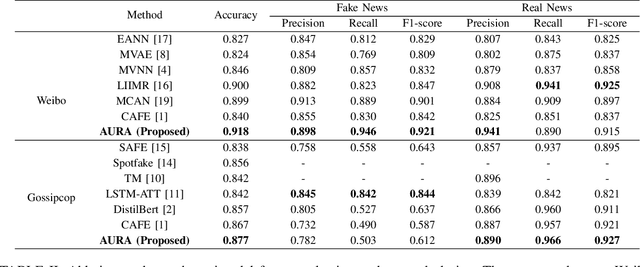
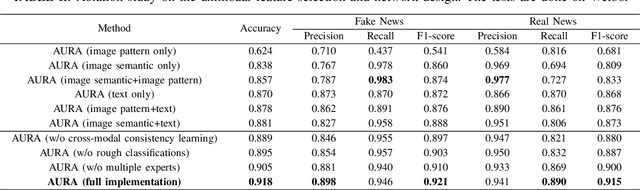
The development of Internet technology has continuously intensified the spread and destructive power of rumors and fake news. Previous researches on multimedia fake news detection include a series of complex feature extraction and fusion networks to achieve feature alignment between images and texts. However, what the multimodal features are composed of and how features from different modalities affect the decision-making process are still open questions. We present AURA, a multimodal fake news detection network with Adaptive Unimodal Representation Aggregation. We first extract representations respectively from image pattern, image semantics and text, and multimodal representations are generated by sending the semantic and linguistic representations into an expert network. Then, we perform coarse-level fake news detection and cross-modal cosistency learning according to the unimodal and multimodal representations. The classification and consistency scores are mapped into modality-aware attention scores that readjust the features. Finally, we aggregation and classify the weighted features for refined fake news detection. Comprehensive experiments on Weibo and Gossipcop prove that AURA can successfully beat several state-of-the-art FND schemes, where the overall prediction accuracy and the recall of fake news is steadily improved.
Multimodal Fake News Detection via CLIP-Guided Learning
May 28, 2022
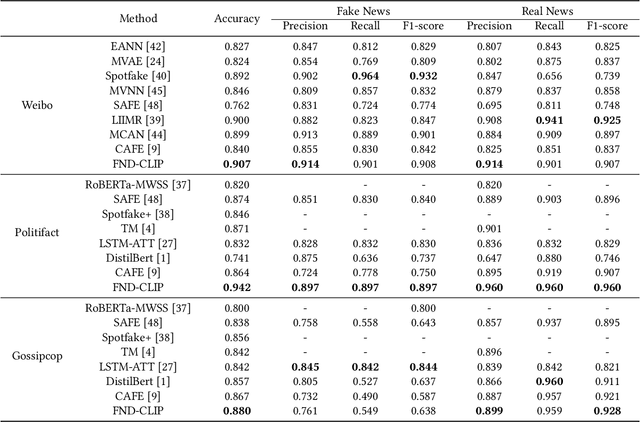
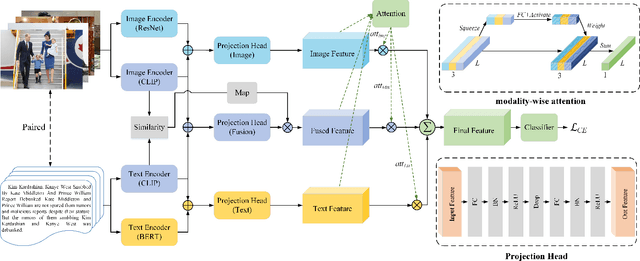

Multimodal fake news detection has attracted many research interests in social forensics. Many existing approaches introduce tailored attention mechanisms to guide the fusion of unimodal features. However, how the similarity of these features is calculated and how it will affect the decision-making process in FND are still open questions. Besides, the potential of pretrained multi-modal feature learning models in fake news detection has not been well exploited. This paper proposes a FND-CLIP framework, i.e., a multimodal Fake News Detection network based on Contrastive Language-Image Pretraining (CLIP). Given a targeted multimodal news, we extract the deep representations from the image and text using a ResNet-based encoder, a BERT-based encoder and two pair-wise CLIP encoders. The multimodal feature is a concatenation of the CLIP-generated features weighted by the standardized cross-modal similarity of the two modalities. The extracted features are further processed for redundancy reduction before feeding them into the final classifier. We introduce a modality-wise attention module to adaptively reweight and aggregate the features. We have conducted extensive experiments on typical fake news datasets. The results indicate that the proposed framework has a better capability in mining crucial features for fake news detection. The proposed FND-CLIP can achieve better performances than previous works, i.e., 0.7\%, 6.8\% and 1.3\% improvements in overall accuracy on Weibo, Politifact and Gossipcop, respectively. Besides, we justify that CLIP-based learning can allow better flexibility on multimodal feature selection.
Frequent Itemset-driven Search for Finding Minimum Node Separators in Complex Networks
Jan 18, 2022



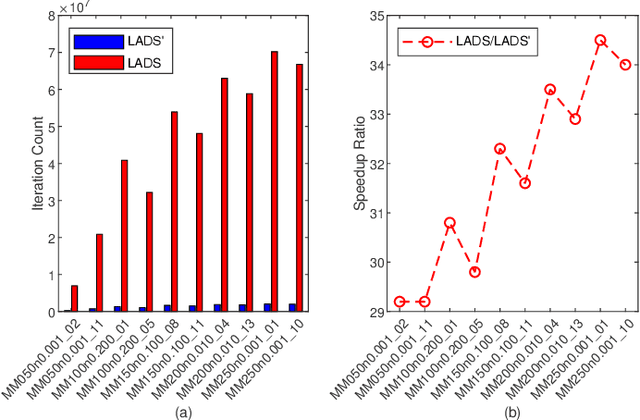
Finding an optimal set of critical nodes in a complex network has been a long-standing problem in the fields of both artificial intelligence and operations research. Potential applications include epidemic control, network security, carbon emission monitoring, emergence response, drug design, and vulnerability assessment. In this work, we consider the problem of finding a minimal node separator whose removal separates a graph into multiple different connected components with fewer than a limited number of vertices in each component. To solve it, we propose a frequent itemset-driven search approach, which integrates the concept of frequent itemset mining in data mining into the well-known memetic search framework. Starting from a high-quality population built by the solution construction and population repair procedures, it iteratively employs the frequent itemset recombination operator (to generate promising offspring solution based on itemsets that frequently occur in high-quality solutions), tabu search-based simulated annealing (to find high-quality local optima), population repair procedure (to modify the population), and rank-based population management strategy (to guarantee a healthy population). Extensive evaluations on 50 widely used benchmark instances show that it significantly outperforms state-of-the-art algorithms. In particular, it discovers 29 new upper bounds and matches 18 previous best-known bounds. Finally, experimental analyses are performed to confirm the effectiveness of key algorithmic modules of the proposed method.
Heuristic Search for Rank Aggregation with Application to Label Ranking
Jan 11, 2022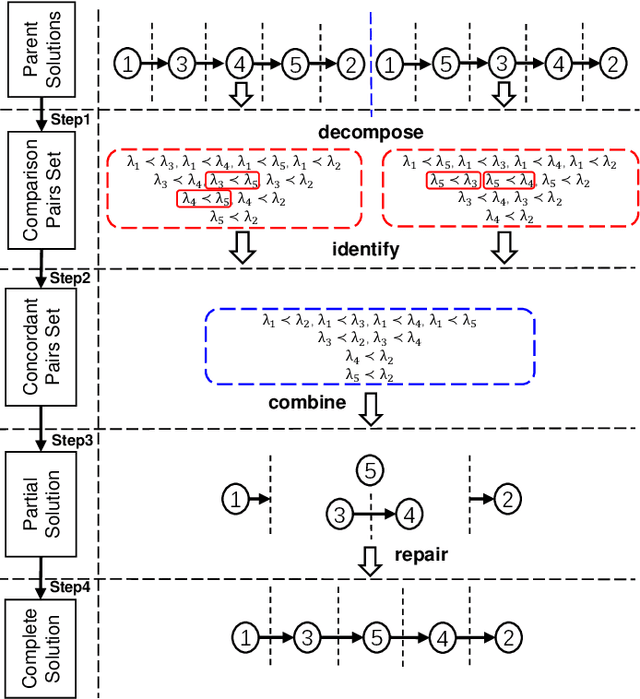
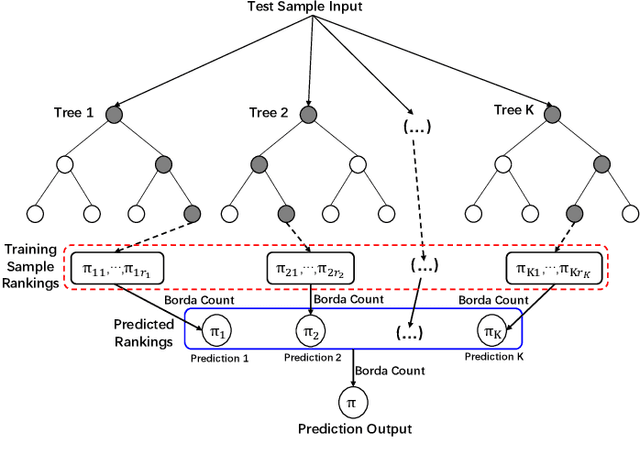
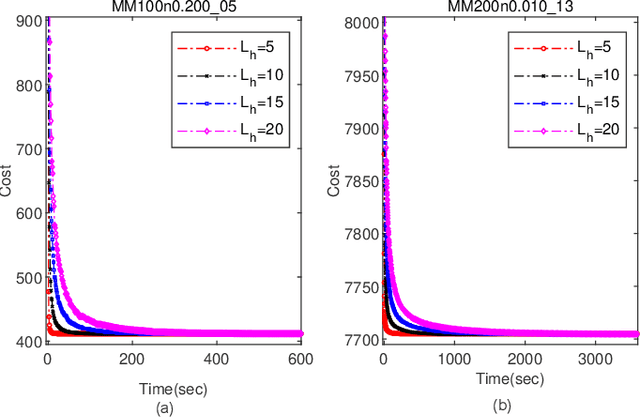
Rank aggregation aims to combine the preference rankings of a number of alternatives from different voters into a single consensus ranking. As a useful model for a variety of practical applications, however, it is a computationally challenging problem. In this paper, we propose an effective hybrid evolutionary ranking algorithm to solve the rank aggregation problem with both complete and partial rankings. The algorithm features a semantic crossover based on concordant pairs and a late acceptance local search reinforced by an efficient incremental evaluation technique. Experiments are conducted to assess the algorithm, indicating a highly competitive performance on benchmark instances compared with state-of-the-art algorithms. To demonstrate its practical usefulness, the algorithm is applied to label ranking, which is an important machine learning task.
Feature Importance-aware Graph Attention Network and Dueling Double Deep Q-Network Combined Approach for Critical Node Detection Problems
Dec 03, 2021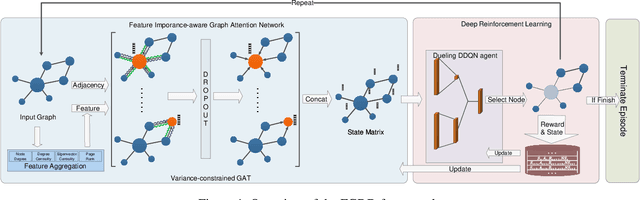
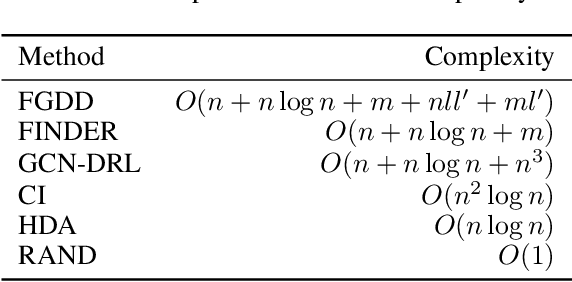
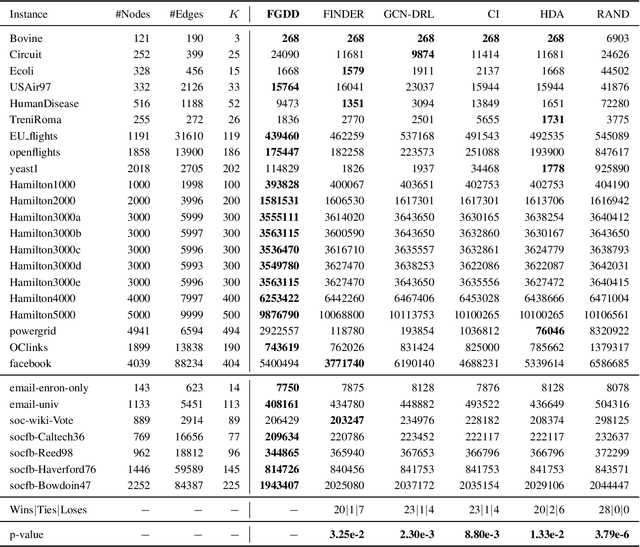
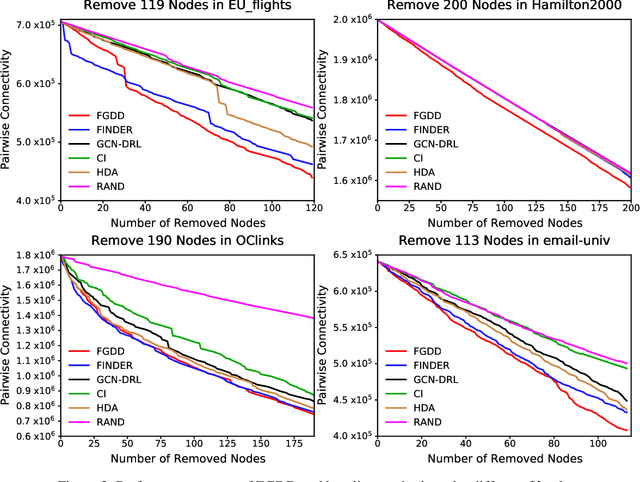
Detecting critical nodes in sparse networks is important in a variety of application domains. A Critical Node Problem (CNP) aims to find a set of critical nodes from a network whose deletion maximally degrades the pairwise connectivity of the residual network. Due to its general NP-hard nature, state-of-the-art CNP solutions are based on heuristic approaches. Domain knowledge and trial-and-error are usually required when designing such approaches, thus consuming considerable effort and time. This work proposes a feature importance-aware graph attention network for node representation and combines it with dueling double deep Q-network to create an end-to-end algorithm to solve CNP for the first time. It does not need any problem-specific knowledge or labeled datasets as required by most of existing methods. Once the model is trained, it can be generalized to cope with various types of CNPs (with different sizes and topological structures) without re-training. Extensive experiments on 28 real-world networks show that the proposed method is highly comparable to state-of-the-art methods. It does not require any problem-specific knowledge and, hence, can be applicable to many applications including those impossible ones by using the existing approaches. It can be combined with some local search methods to further improve its solution quality. Extensive comparison results are given to show its effectiveness in solving CNP.
Cost-Quality Adaptive Active Learning for Chinese Clinical Named Entity Recognition
Aug 28, 2020
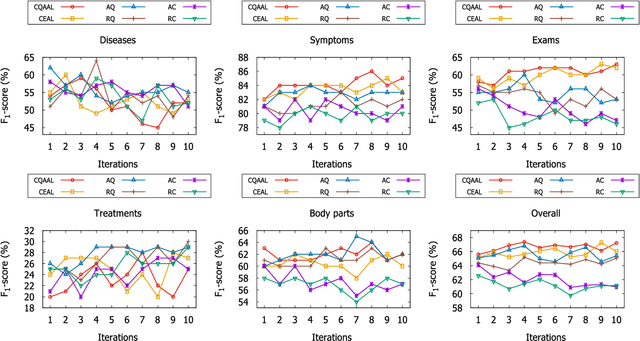

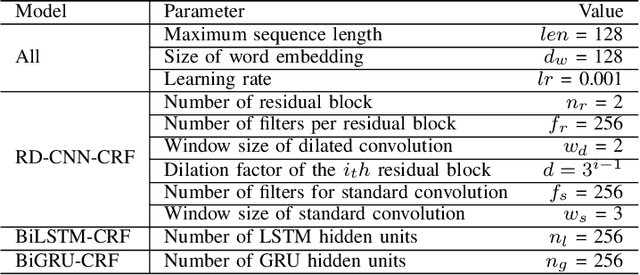
Clinical Named Entity Recognition (CNER) aims to automatically identity clinical terminologies in Electronic Health Records (EHRs), which is a fundamental and crucial step for clinical research. To train a high-performance model for CNER, it usually requires a large number of EHRs with high-quality labels. However, labeling EHRs, especially Chinese EHRs, is time-consuming and expensive. One effective solution to this is active learning, where a model asks labelers to annotate data which the model is uncertain of. Conventional active learning assumes a single labeler that always replies noiseless answers to queried labels. However, in real settings, multiple labelers provide diverse quality of annotation with varied costs and labelers with low overall annotation quality can still assign correct labels for some specific instances. In this paper, we propose a Cost-Quality Adaptive Active Learning (CQAAL) approach for CNER in Chinese EHRs, which maintains a balance between the annotation quality, labeling costs, and the informativeness of selected instances. Specifically, CQAAL selects cost-effective instance-labeler pairs to achieve better annotation quality with lower costs in an adaptive manner. Computational results on the CCKS-2017 Task 2 benchmark dataset demonstrate the superiority and effectiveness of the proposed CQAAL.