 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Shift Is Key to Learning Invariant Prediction
Jan 18, 2026An interesting phenomenon arises: Empirical Risk Minimization (ERM) sometimes outperforms methods specifically designed for out-of-distribution tasks. This motivates an investigation into the reasons behind such behavior beyond algorithmic design. In this study, we find that one such reason lies in the distribution shift across training domains. A large degree of distribution shift can lead to better performance even under ERM. Specifically, we derive several theoretical and empirical findings demonstrating that distribution shift plays a crucial role in model learning and benefits learning invariant prediction. Firstly, the proposed upper bounds indicate that the degree of distribution shift directly affects the prediction ability of the learned models. If it is large, the models' ability can increase, approximating invariant prediction models that make stable predictions under arbitrary known or unseen domains; and vice versa. We also prove that, under certain data conditions, ERM solutions can achieve performance comparable to that of invariant prediction models. Secondly, the empirical validation results demonstrated that the predictions of learned models approximate those of Oracle or Optimal models, provided that the degree of distribution shift in the training data increases.
Disentangled Modeling of Preferences and Social Influence for Group Recommendation
Jan 20, 2025



The group recommendation (GR) aims to suggest items for a group of users in social networks. Existing work typically considers individual preferences as the sole factor in aggregating group preferences. Actually, social influence is also an important factor in modeling users' contributions to the final group decision. However, existing methods either neglect the social influence of individual members or bundle preferences and social influence together as a unified representation. As a result, these models emphasize the preferences of the majority within the group rather than the actual interaction items, which we refer to as the preference bias issue in GR. Moreover, the self-supervised learning (SSL) strategies they designed to address the issue of group data sparsity fail to account for users' contextual social weights when regulating group representations, leading to suboptimal results. To tackle these issues, we propose a novel model based on Disentangled Modeling of Preferences and Social Influence for Group Recommendation (DisRec). Concretely, we first design a user-level disentangling network to disentangle the preferences and social influence of group members with separate embedding propagation schemes based on (hyper)graph convolution networks. We then introduce a socialbased contrastive learning strategy, selectively excluding user nodes based on their social importance to enhance group representations and alleviate the group-level data sparsity issue. The experimental results demonstrate that our model significantly outperforms state-of-the-art methods on two realworld datasets.
Unraveling Radiomics Complexity: Strategies for Optimal Simplicity in Predictive Modeling
Jul 05, 2024



Background: The high dimensionality of radiomic feature sets, the variability in radiomic feature types and potentially high computational requirements all underscore the need for an effective method to identify the smallest set of predictive features for a given clinical problem. Purpose: Develop a methodology and tools to identify and explain the smallest set of predictive radiomic features. Materials and Methods: 89,714 radiomic features were extracted from five cancer datasets: low-grade glioma, meningioma, non-small cell lung cancer (NSCLC), and two renal cell carcinoma cohorts (n=2104). Features were categorized by computational complexity into morphological, intensity, texture, linear filters, and nonlinear filters. Models were trained and evaluated on each complexity level using the area under the curve (AUC). The most informative features were identified, and their importance was explained. The optimal complexity level and associated most informative features were identified using systematic statistical significance analyses and a false discovery avoidance procedure, respectively. Their predictive importance was explained using a novel tree-based method. Results: MEDimage, a new open-source tool, was developed to facilitate radiomic studies. Morphological features were optimal for MRI-based meningioma (AUC: 0.65) and low-grade glioma (AUC: 0.68). Intensity features were optimal for CECT-based renal cell carcinoma (AUC: 0.82) and CT-based NSCLC (AUC: 0.76). Texture features were optimal for MRI-based renal cell carcinoma (AUC: 0.72). Tuning the Hounsfield unit range improved results for CECT-based renal cell carcinoma (AUC: 0.86). Conclusion: Our proposed methodology and software can estimate the optimal radiomics complexity level for specific medical outcomes, potentially simplifying the use of radiomics in predictive modeling across various contexts.
Metacognition-Enhanced Few-Shot Prompting With Positive Reinforcement
Dec 24, 2023



Few-shot prompting elicits the remarkable abilities of large language models by equipping them with a few demonstration examples in the input. However, the traditional method of providing large language models with all demonstration input-output pairs at once may not effectively guide large language models to learn the specific input-output mapping relationship. In this paper, inspired by the regulatory and supportive role of metacognition in students' learning, we propose a novel metacognition-enhanced few-shot prompting, which guides large language models to reflect on their thought processes to comprehensively learn the given demonstration examples. Furthermore, considering that positive reinforcement can improve students' learning motivation, we introduce positive reinforcement into our metacognition-enhanced few-shot prompting to promote the few-shot learning of large language models by providing response-based positive feedback. The experimental results on two real-world datasets show that our metacognition-enhanced few-shot prompting with positive reinforcement surpasses traditional few-shot prompting in classification accuracy and macro F1.
Is ChatGPT a Good Personality Recognizer? A Preliminary Study
Jul 26, 2023In recent years, personality has been regarded as a valuable personal factor being incorporated into numerous tasks such as sentiment analysis and product recommendation. This has led to widespread attention to text-based personality recognition task, which aims to identify an individual's personality based on given text. Considering that ChatGPT has recently exhibited remarkable abilities on various natural language processing tasks, we provide a preliminary evaluation of ChatGPT on text-based personality recognition task for generating effective personality data. Concretely, we employ a variety of prompting strategies to explore ChatGPT's ability in recognizing personality from given text, especially the level-oriented prompting strategy we designed for guiding ChatGPT in analyzing given text at a specified level. The experimental results on two representative real-world datasets reveal that ChatGPT with zero-shot chain-of-thought prompting exhibits impressive personality recognition ability and is capable to provide natural language explanations through text-based logical reasoning. Furthermore, by employing the level-oriented prompting strategy to optimize zero-shot chain-of-thought prompting, the performance gap between ChatGPT and corresponding state-of-the-art model has been narrowed even more. However, we observe that ChatGPT shows unfairness towards certain sensitive demographic attributes such as gender and age. Additionally, we discover that eliciting the personality recognition ability of ChatGPT helps improve its performance on personality-related downstream tasks such as sentiment classification and stress prediction.
DMF-Net: Dual-Branch Multi-Scale Feature Fusion Network for copy forgery identification of anti-counterfeiting QR code
Jan 19, 2022



Anti-counterfeiting QR codes are widely used in people's work and life, especially in product packaging. However, the anti-counterfeiting QR code has the risk of being copied and forged in the circulation process. In reality, copying is usually based on genuine anti-counterfeiting QR codes, but the brands and models of copiers are diverse, and it is extremely difficult to determine which individual copier the forged anti-counterfeiting code come from. In response to the above problems, this paper proposes a method for copy forgery identification of anti-counterfeiting QR code based on deep learning. We first analyze the production principle of anti-counterfeiting QR code, and convert the identification of copy forgery to device category forensics, and then a Dual-Branch Multi-Scale Feature Fusion network is proposed. During the design of the network, we conducted a detailed analysis of the data preprocessing layer, single-branch design, etc., combined with experiments, the specific structure of the dual-branch multi-scale feature fusion network is determined. The experimental results show that the proposed method has achieved a high accuracy of copy forgery identification, which exceeds the current series of methods in the field of image forensics.
GACAN: Graph Attention-Convolution-Attention Networks for Traffic Forecasting Based on Multi-granularity Time Series
Oct 27, 2021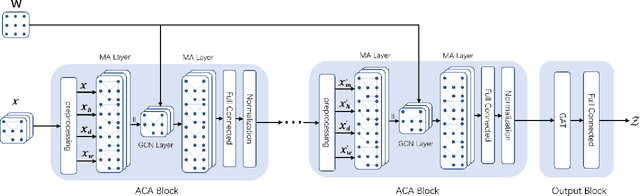
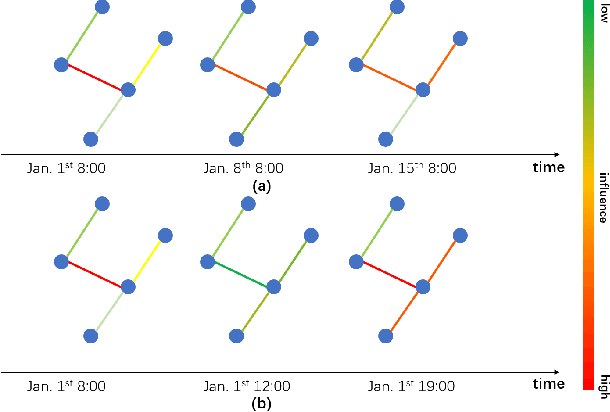
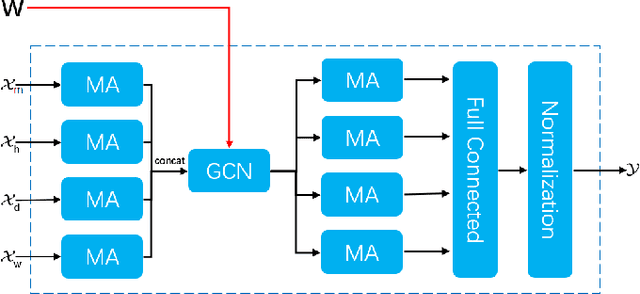
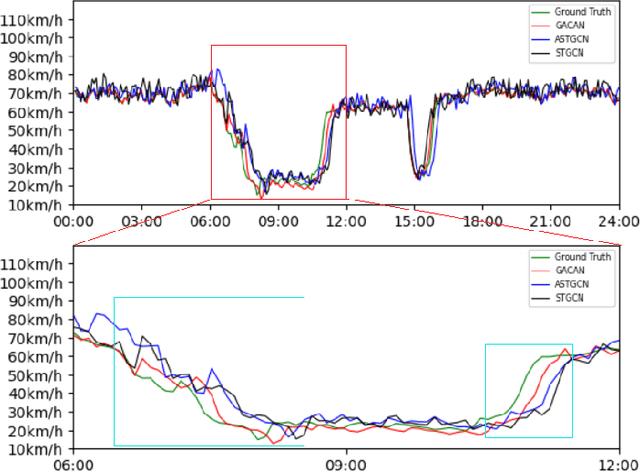
Traffic forecasting is an integral part of intelligent transportation systems (ITS). Achieving a high prediction accuracy is a challenging task due to a high level of dynamics and complex spatial-temporal dependency of road networks. For this task, we propose Graph Attention-Convolution-Attention Networks (GACAN). The model uses a novel Att-Conv-Att (ACA) block which contains two graph attention layers and one spectral-based GCN layer sandwiched in between. The graph attention layers are meant to capture temporal features while the spectral-based GCN layer is meant to capture spatial features. The main novelty of the model is the integration of time series of four different time granularities: the original time series, together with hourly, daily, and weekly time series. Unlike previous work that used multi-granularity time series by handling every time series separately, GACAN combines the outcome of processing all time series after each graph attention layer. Thus, the effects of different time granularities are integrated throughout the model. We perform a series of experiments on three real-world datasets. The experimental results verify the advantage of using multi-granularity time series and that the proposed GACAN model outperforms the state-of-the-art baselines.
* This paper has been published in the IJCNN 2021 (https://ieeexplore.ieee.org/document/9534064/)
Cost-Quality Adaptive Active Learning for Chinese Clinical Named Entity Recognition
Aug 28, 2020
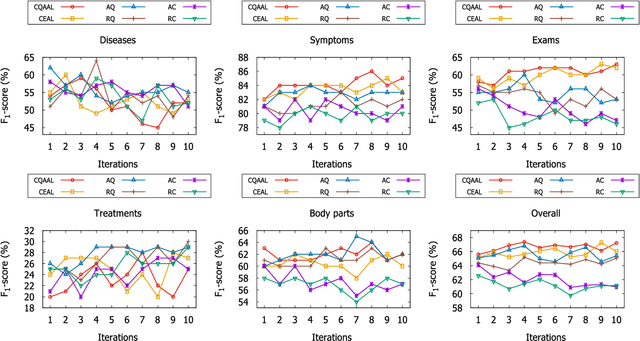

Clinical Named Entity Recognition (CNER) aims to automatically identity clinical terminologies in Electronic Health Records (EHRs), which is a fundamental and crucial step for clinical research. To train a high-performance model for CNER, it usually requires a large number of EHRs with high-quality labels. However, labeling EHRs, especially Chinese EHRs, is time-consuming and expensive. One effective solution to this is active learning, where a model asks labelers to annotate data which the model is uncertain of. Conventional active learning assumes a single labeler that always replies noiseless answers to queried labels. However, in real settings, multiple labelers provide diverse quality of annotation with varied costs and labelers with low overall annotation quality can still assign correct labels for some specific instances. In this paper, we propose a Cost-Quality Adaptive Active Learning (CQAAL) approach for CNER in Chinese EHRs, which maintains a balance between the annotation quality, labeling costs, and the informativeness of selected instances. Specifically, CQAAL selects cost-effective instance-labeler pairs to achieve better annotation quality with lower costs in an adaptive manner. Computational results on the CCKS-2017 Task 2 benchmark dataset demonstrate the superiority and effectiveness of the proposed CQAAL.
Active Learning for Chinese Word Segmentation in Medical Text
Aug 22, 2019
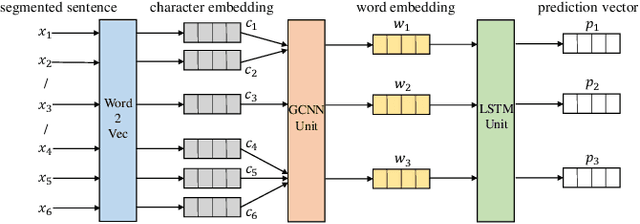
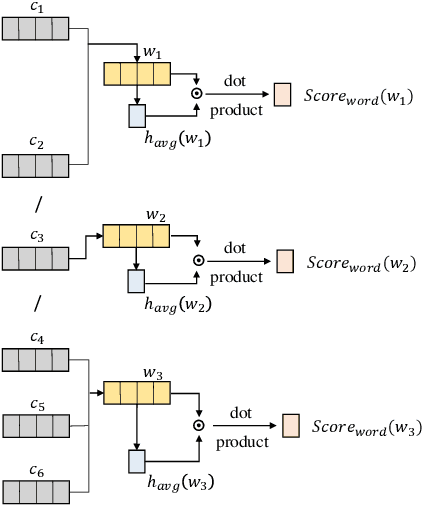

Electronic health records (EHRs) stored in hospital information systems completely reflect the patients' diagnosis and treatment processes, which are essential to clinical data mining. Chinese word segmentation (CWS) is a fundamental and important task for Chinese natural language processing. Currently, most state-of-the-art CWS methods greatly depend on large-scale manually-annotated data, which is a very time-consuming and expensive work, specially for the annotation in medical field. In this paper, we present an active learning method for CWS in medical text. To effectively utilize complete segmentation history, a new scoring model in sampling strategy is proposed, which combines information entropy with neural network. Besides, to capture interactions between adjacent characters, K-means clustering features are additionally added in word segmenter. We experimentally evaluate our proposed CWS method in medical text, experimental results based on EHRs collected from the Shuguang Hospital Affiliated to Shanghai University of Traditional Chinese Medicine show that our proposed method outperforms other reference methods, which can effectively save the cost of manual annotation.
From the Periphery to the Center: Information Brokerage in an Evolving Network
May 02, 2018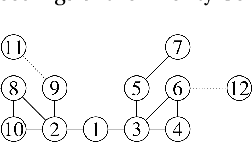
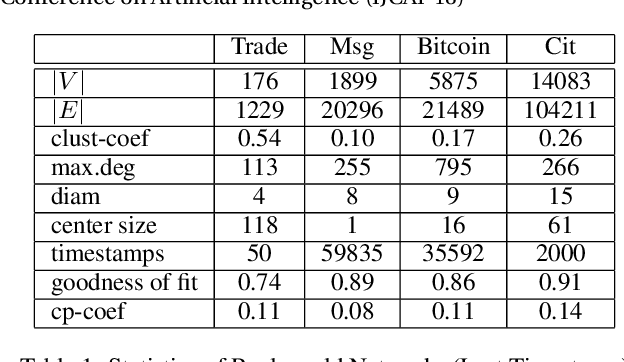

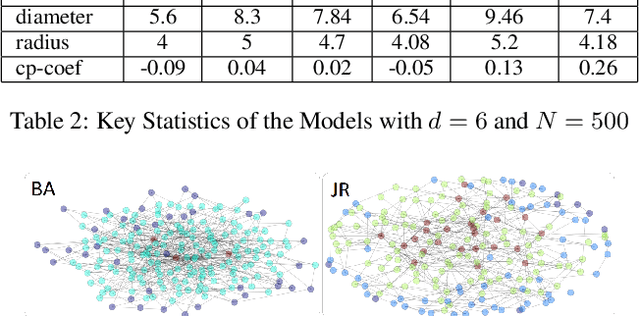
Interpersonal ties are pivotal to individual efficacy, status and performance in an agent society. This paper explores three important and interrelated themes in social network theory: the center/periphery partition of the network; network dynamics; and social integration of newcomers. We tackle the question: How would a newcomer harness information brokerage to integrate into a dynamic network going from periphery to center? We model integration as the interplay between the newcomer and the dynamics network and capture information brokerage using a process of relationship building. We analyze theoretical guarantees for the newcomer to reach the center through tactics; proving that a winning tactic always exists for certain types of network dynamics. We then propose three tactics and show their superior performance over alternative methods on four real-world datasets and four network models. In general, our tactics place the newcomer to the center by adding very few new edges on dynamic networks with approximately 14000 nodes.