 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Chinese Word Segmentation in Medical Text
Aug 22, 2019
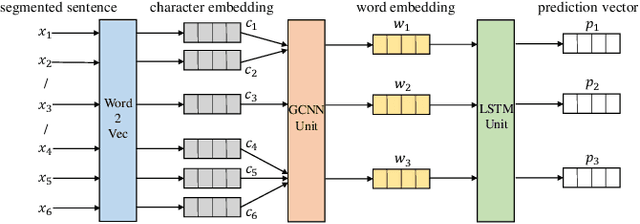
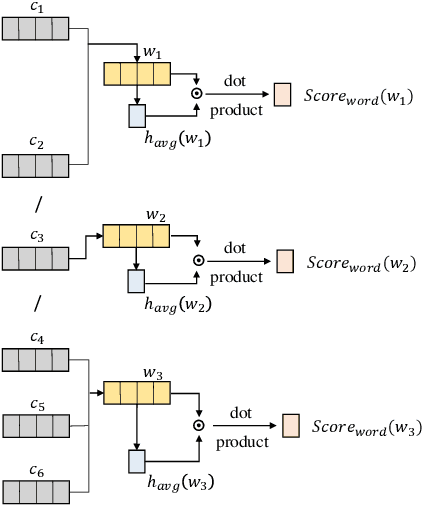

Electronic health records (EHRs) stored in hospital information systems completely reflect the patients' diagnosis and treatment processes, which are essential to clinical data mining. Chinese word segmentation (CWS) is a fundamental and important task for Chinese natural language processing. Currently, most state-of-the-art CWS methods greatly depend on large-scale manually-annotated data, which is a very time-consuming and expensive work, specially for the annotation in medical field. In this paper, we present an active learning method for CWS in medical text. To effectively utilize complete segmentation history, a new scoring model in sampling strategy is proposed, which combines information entropy with neural network. Besides, to capture interactions between adjacent characters, K-means clustering features are additionally added in word segmenter. We experimentally evaluate our proposed CWS method in medical text, experimental results based on EHRs collected from the Shuguang Hospital Affiliated to Shanghai University of Traditional Chinese Medicine show that our proposed method outperforms other reference methods, which can effectively save the cost of manual annotation.
CBOWRA: A Representation Learning Approach for Medication Anomaly Detection
Aug 20, 2019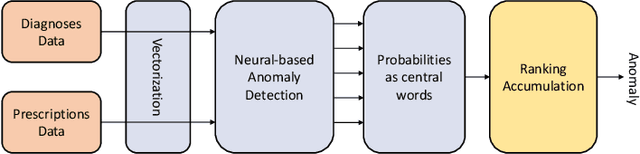
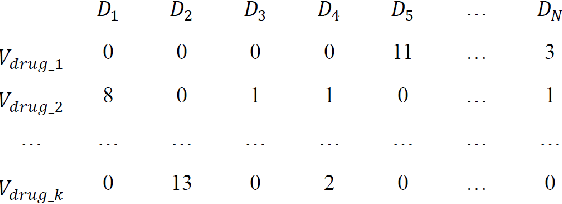
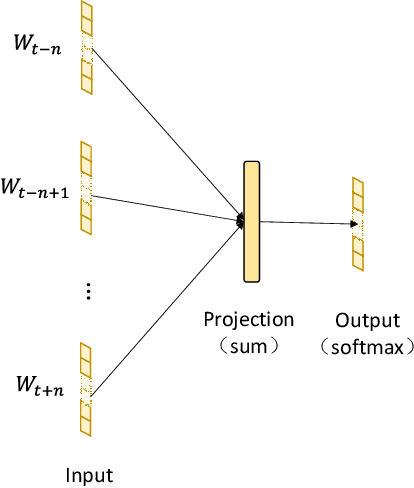
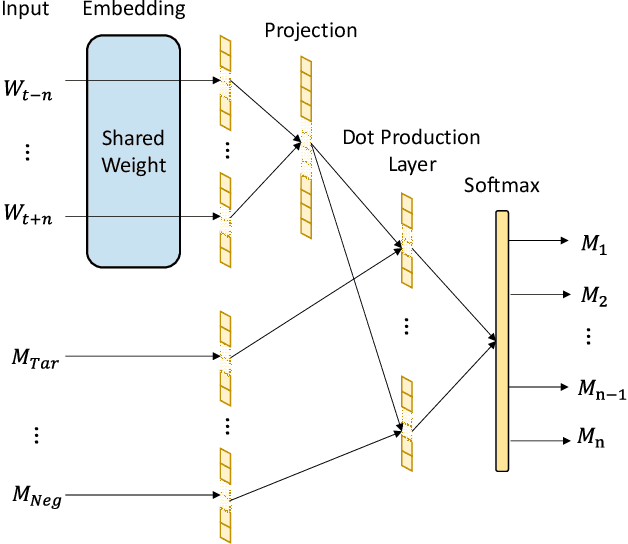
Electronic health record is an important source for clinical researches and applications, and errors inevitably occur in the data, which could lead to severe damages to both patients and hospital services. One of such error is the mismatches between diagnoses and prescriptions, which we address as 'medication anomaly' in the paper, and clinicians used to manually identify and correct them. With the development of machine learning techniques, researchers are able to train specific model for the task, but the process still requires expert knowledge to construct proper features, and few semantic relations are considered. In this paper, we propose a simple, yet effective detection method that tackles the problem by detecting the semantic inconsistency between diagnoses and prescriptions. Unlike traditional outlier or anomaly detection, the scheme uses continuous bag of words to construct the semantic connection between specific central words and their surrounding context. The detection of medication anomaly is transformed into identifying the least possible central word based on given context. To help distinguish the anomaly from normal context, we also incorporate a ranking accumulation strategy. The experiments were conducted on two real hospital electronic medical records, and the topN accuracy of the proposed method increased by 3.91 to 10.91% and 0.68 to 2.13% on the datasets, respectively, which is highly competitive to other traditional machine learning-based approaches.
Fast and Accurate Recognition of Chinese Clinical Named Entities with Residual Dilated Convolutions
Aug 29, 2018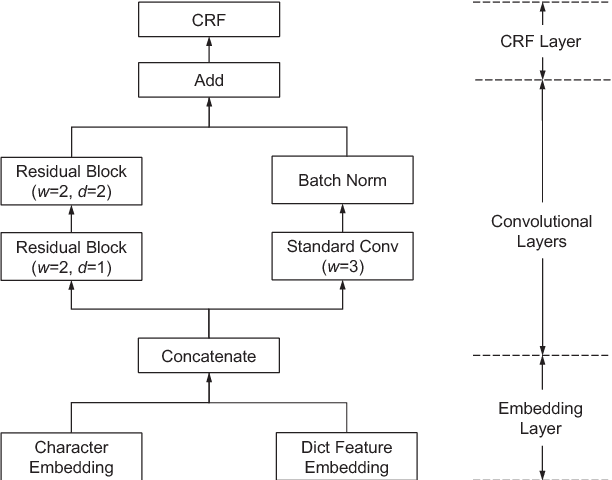
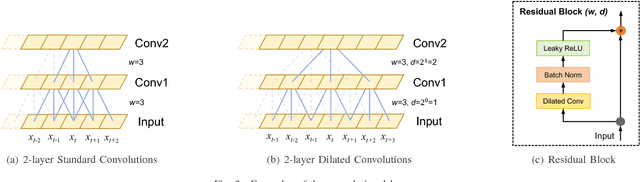
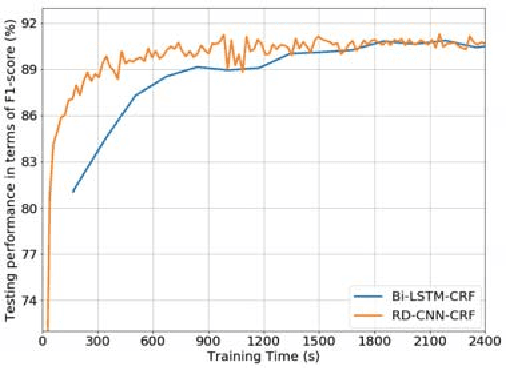

Clinical Named Entity Recognition (CNER) aims to identify and classify clinical terms such as diseases, symptoms, treatments, exams, and body parts in electronic health records, which is a fundamental and crucial task for clinical and translation research. In recent years, deep learning methods have achieved significant success in CNER tasks. However, these methods depend greatly on Recurrent Neural Networks (RNNs), which maintain a vector of hidden activations that are propagated through time, thus causing too much time to train models. In this paper, we propose a Residual Dilated Convolutional Neural Network with Conditional Random Field (RD-CNN-CRF) to solve the Chinese CNER. Specifically, Chinese characters and dictionary features are first projected into dense vector representations, then they are fed into the residual dilated convolutional neural network to capture contextual features. Finally, a conditional random field is employed to capture dependencies between neighboring tags. Computational results on the CCKS-2017 Task 2 benchmark dataset show that our proposed RD-CNN-CRF method competes favorably with state-of-the-art RNN-based methods both in terms of computational performance and training time.
Recurrent Capsule Network for Relations Extraction: A Practical Application to the Severity Classification of Coronary Artery Disease
Jul 18, 2018

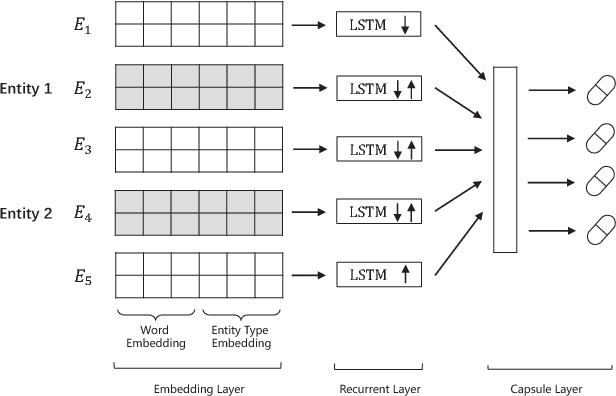
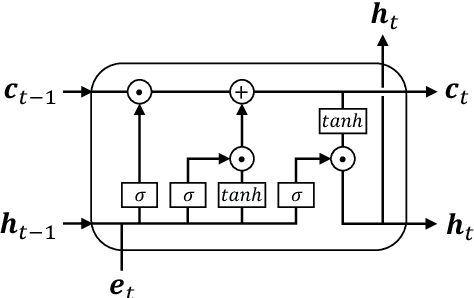
Coronary artery disease (CAD) is one of the leading causes of cardiovascular disease deaths. CAD condition progresses rapidly, if not diagnosed and treated at an early stage may eventually lead to an irreversible state of the heart muscle death. Invasive coronary arteriography is the gold standard technique for CAD diagnosis. Coronary arteriography texts describe which part has stenosis and how much stenosis is in details. It is crucial to conduct the severity classification of CAD. In this paper, we propose a recurrent capsule network (RCN) to extract semantic relations between clinical named entities in Chinese coronary arteriography texts, through which we can automatically find out the maximal stenosis for each lumen to inference how severe CAD is according to the improved method of Gensini. Experimental results on the corpus collected from Shanghai Shuguang Hospital show that our proposed RCN model achieves a F$_1$-score of 0.9641 in relation extraction, which outperforms the baseline methods.