 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBOWRA: A Representation Learning Approach for Medication Anomaly Detection
Paper and Code
Aug 20, 2019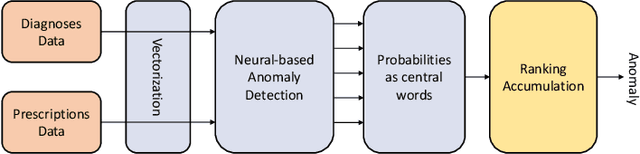
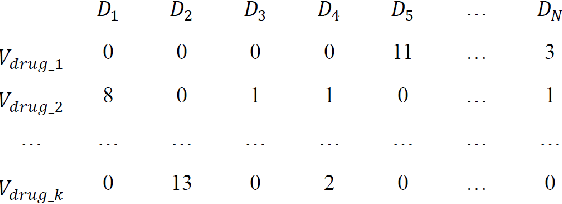
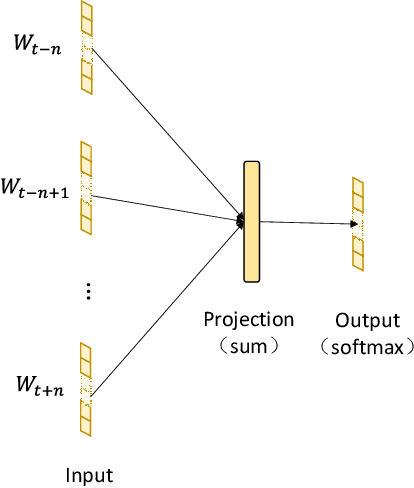
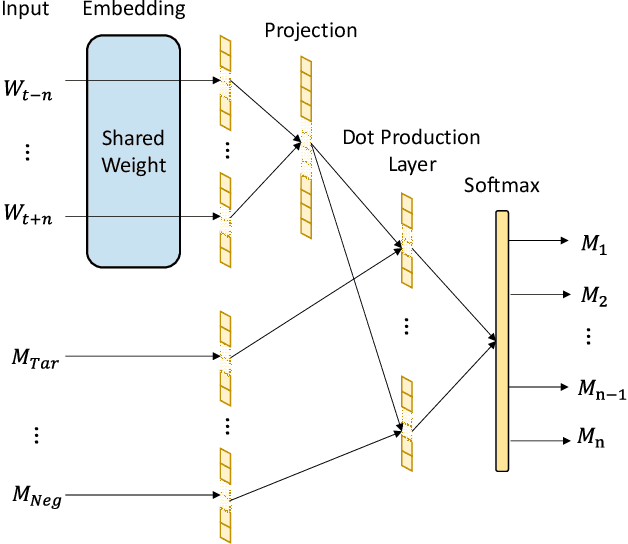
Electronic health record is an important source for clinical researches and applications, and errors inevitably occur in the data, which could lead to severe damages to both patients and hospital services. One of such error is the mismatches between diagnoses and prescriptions, which we address as 'medication anomaly' in the paper, and clinicians used to manually identify and correct them. With the development of machine learning techniques, researchers are able to train specific model for the task, but the process still requires expert knowledge to construct proper features, and few semantic relations are considered. In this paper, we propose a simple, yet effective detection method that tackles the problem by detecting the semantic inconsistency between diagnoses and prescriptions. Unlike traditional outlier or anomaly detection, the scheme uses continuous bag of words to construct the semantic connection between specific central words and their surrounding context. The detection of medication anomaly is transformed into identifying the least possible central word based on given context. To help distinguish the anomaly from normal context, we also incorporate a ranking accumulation strategy. The experiments were conducted on two real hospital electronic medical records, and the topN accuracy of the proposed method increased by 3.91 to 10.91% and 0.68 to 2.13% on the datasets, respectively, which is highly competitive to other traditional machine learning-based approaches.