 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatientEG Dataset: Bringing Event Graph Model with Temporal Relations to Electronic Medical Records
Dec 24, 2018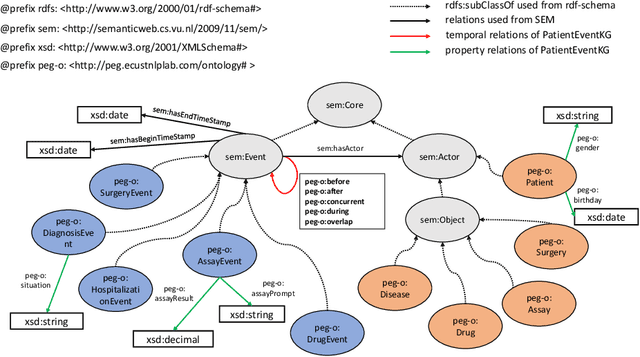
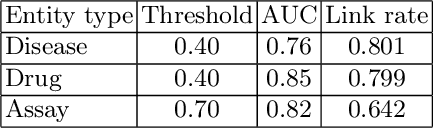
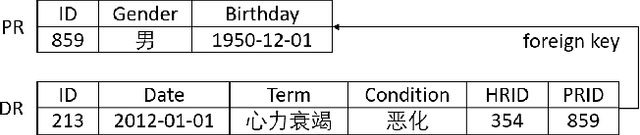

Medical activities, such as diagnoses, medicine treatments, and laboratory tests, as well as temporal relations between these activities are the basic concepts in clinical research. However, existing relational data model on electronic medical records (EMRs) lacks explicit and accurate semantic definitions of these concepts. It leads to the inconvenience of query construction and the inefficiency of query execution where multi-table join queries are frequently required. In this paper, we propose a patient event graph (PatientEG) model to capture the characteristics of EMRs. We respectively define five types of medical entities, five types of medical events and five types of temporal relations. Based on the proposed model, we also construct a PatientEG dataset with 191,294 events, 3,429 distinct entities, and 545,993 temporal relations using EMRs from Shanghai Shuguang hospital. To help to normalize entity values which contain synonyms, hyponymies, and abbreviations, we link them with the Chinese biomedical knowledge graph. With the help of PatientEG dataset, we are able to conveniently perform complex queries for clinical research such as auxiliary diagnosis and therapeutic effectiveness analysis. In addition, we provide a SPARQL endpoint to access PatientEG dataset and the dataset is also publicly available online. Also, we list several illustrative SPARQL queries on our website.
Recurrent Capsule Network for Relations Extraction: A Practical Application to the Severity Classification of Coronary Artery Disease
Jul 18, 2018

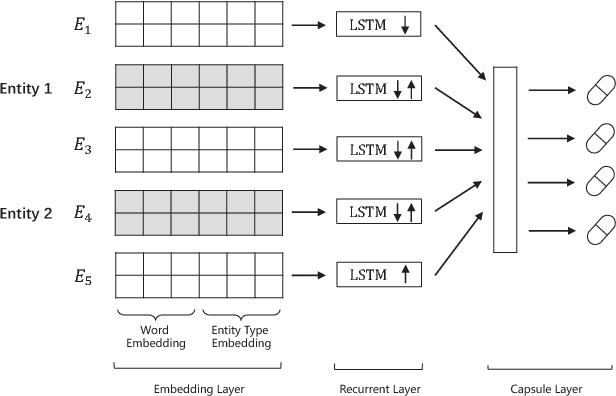
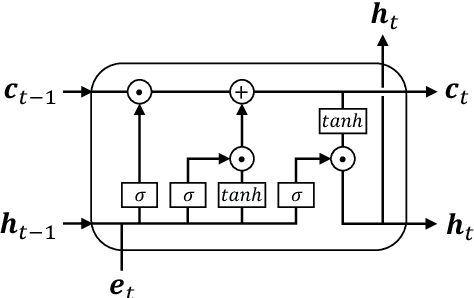
Coronary artery disease (CAD) is one of the leading causes of cardiovascular disease deaths. CAD condition progresses rapidly, if not diagnosed and treated at an early stage may eventually lead to an irreversible state of the heart muscle death. Invasive coronary arteriography is the gold standard technique for CAD diagnosis. Coronary arteriography texts describe which part has stenosis and how much stenosis is in details. It is crucial to conduct the severity classification of CAD. In this paper, we propose a recurrent capsule network (RCN) to extract semantic relations between clinical named entities in Chinese coronary arteriography texts, through which we can automatically find out the maximal stenosis for each lumen to inference how severe CAD is according to the improved method of Gensini. Experimental results on the corpus collected from Shanghai Shuguang Hospital show that our proposed RCN model achieves a F$_1$-score of 0.9641 in relation extraction, which outperforms the baseline methods.
An attention-based Bi-GRU-CapsNet model for hypernymy detection between compound entities
May 18, 2018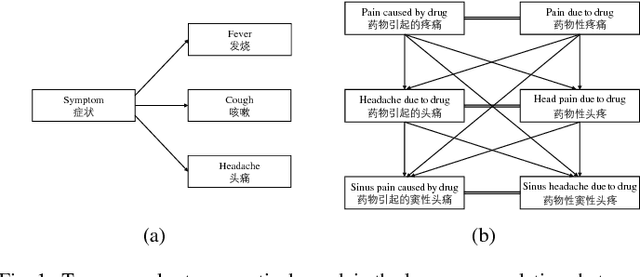
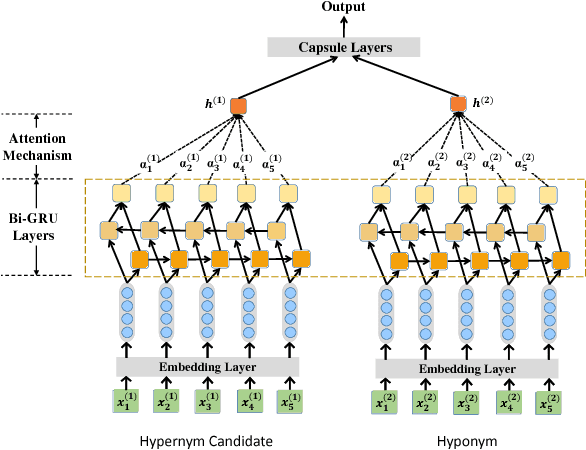
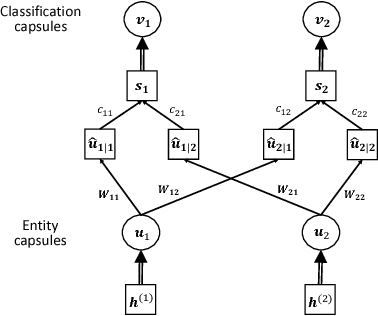
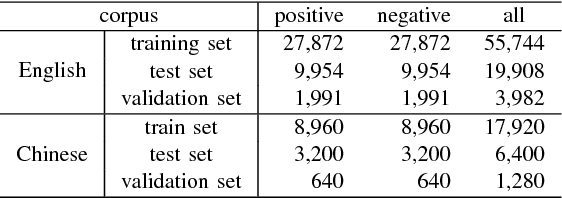
Named entities which composed of multiple continuous words frequently occur in domain-specific knowledge graphs. These entities are usually composable and extensible. Typical examples are names of symptoms and diseases in medical areas. To distinguish these entities from general entities, we name them compound entities. Hypernymy detection between compound entities plays an important role in domain-specific knowledge graph construction. Traditional hypernymy detection approaches cannot perform well on compound entities due to the lack of contextual information in texts, and even the absence of compound entities in training sets, i.e. Out-Of-Vocabulary (OOV) problem. In this paper, we present a novel attention-based Bi-GRU-CapsNet model to detect hypernymy relationship between compound entities. Our model consists of several important components. To avoid the OOV problem, English words or Chinese characters in compound entities are fed into Bidirectional Gated Recurrent Units (Bi-GRUs). An attention mechanism is designed to focus on the differences between two compound entities. Since there are some different cases in hypernymy relationship between compound entities, Capsule Network (CapsNet) is finally employed to decide whether the hypernymy relationship exists or not. Experimental results demonstrate the advantages of our model over the state-of-the-art methods both on English and Chinese corpora of symptom and disease pairs.
Incorporating Dictionaries into Deep Neural Networks for the Chinese Clinical Named Entity Recognition
Apr 13, 2018
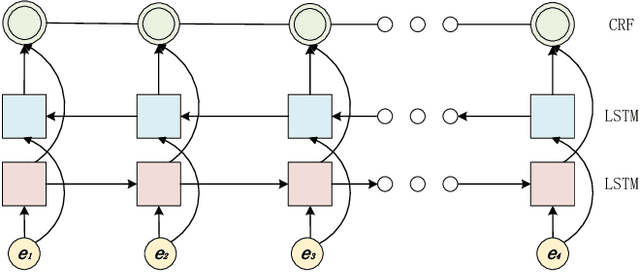

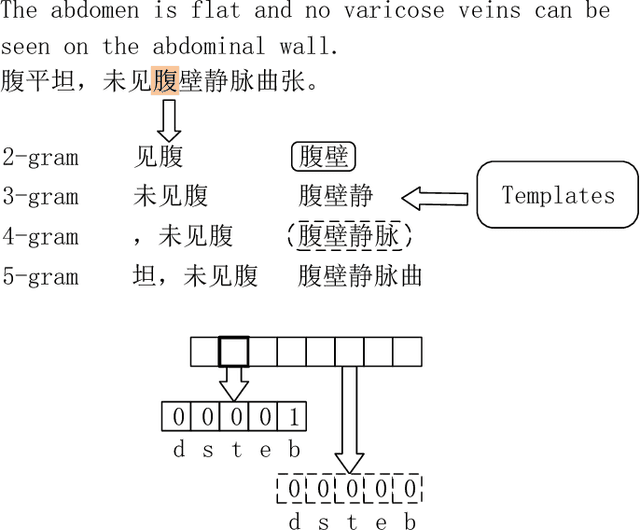
Clinical Named Entity Recognition (CNER) aims to identify and classify clinical terms such as diseases, symptoms, treatments, exams, and body parts in electronic health records, which is a fundamental and crucial task for clinical and translational research. In recent years, deep neural networks have achieved significant success in named entity recognition and many other Natural Language Processing (NLP) tasks. Most of these algorithms are trained end to end, and can automatically learn features from large scale labeled datasets. However, these data-driven methods typically lack the capability of processing rare or unseen entities. Previous statistical methods and feature engineering practice have demonstrated that human knowledge can provide valuable information for handling rare and unseen cases. In this paper, we address the problem by incorporating dictionaries into deep neural networks for the Chinese CNER task. Two different architectures that extend the Bi-directional Long Short-Term Memory (Bi-LSTM) neural network and five different feature representation schemes are proposed to handle the task. Computational results on the CCKS-2017 Task 2 benchmark dataset show that the proposed method achieves the highly competitive performance compared with the state-of-the-art deep learning methods.