 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Quality Adaptive Active Learning for Chinese Clinical Named Entity Recognition
Aug 28, 2020
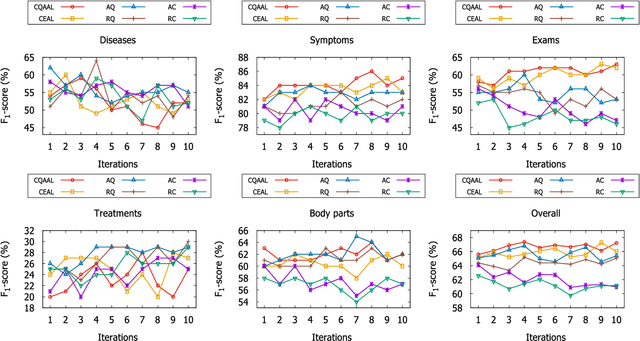

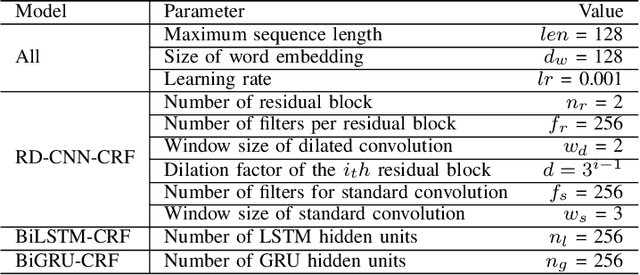
Clinical Named Entity Recognition (CNER) aims to automatically identity clinical terminologies in Electronic Health Records (EHRs), which is a fundamental and crucial step for clinical research. To train a high-performance model for CNER, it usually requires a large number of EHRs with high-quality labels. However, labeling EHRs, especially Chinese EHRs, is time-consuming and expensive. One effective solution to this is active learning, where a model asks labelers to annotate data which the model is uncertain of. Conventional active learning assumes a single labeler that always replies noiseless answers to queried labels. However, in real settings, multiple labelers provide diverse quality of annotation with varied costs and labelers with low overall annotation quality can still assign correct labels for some specific instances. In this paper, we propose a Cost-Quality Adaptive Active Learning (CQAAL) approach for CNER in Chinese EHRs, which maintains a balance between the annotation quality, labeling costs, and the informativeness of selected instances. Specifically, CQAAL selects cost-effective instance-labeler pairs to achieve better annotation quality with lower costs in an adaptive manner. Computational results on the CCKS-2017 Task 2 benchmark dataset demonstrate the superiority and effectiveness of the proposed CQAAL.
Active Learning for Chinese Word Segmentation in Medical Text
Aug 22, 2019
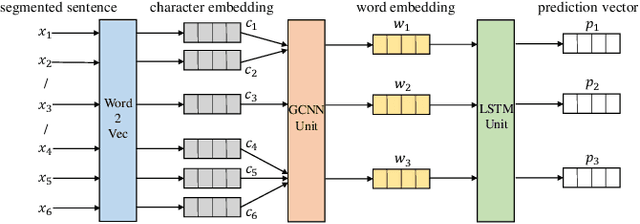
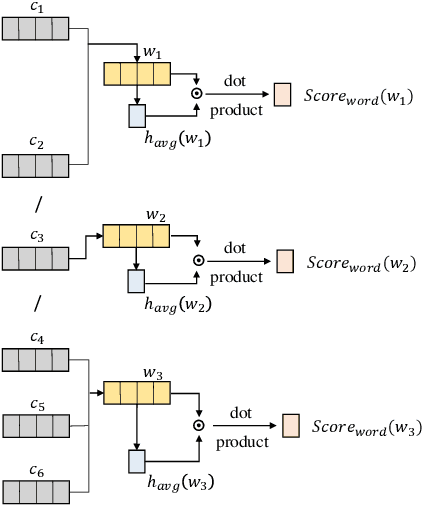

Electronic health records (EHRs) stored in hospital information systems completely reflect the patients' diagnosis and treatment processes, which are essential to clinical data mining. Chinese word segmentation (CWS) is a fundamental and important task for Chinese natural language processing. Currently, most state-of-the-art CWS methods greatly depend on large-scale manually-annotated data, which is a very time-consuming and expensive work, specially for the annotation in medical field. In this paper, we present an active learning method for CWS in medical text. To effectively utilize complete segmentation history, a new scoring model in sampling strategy is proposed, which combines information entropy with neural network. Besides, to capture interactions between adjacent characters, K-means clustering features are additionally added in word segmenter. We experimentally evaluate our proposed CWS method in medical text, experimental results based on EHRs collected from the Shuguang Hospital Affiliated to Shanghai University of Traditional Chinese Medicine show that our proposed method outperforms other reference methods, which can effectively save the cost of manual annotation.