 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Power-System Dynamic Trajectories with Foundation Models
Apr 16, 2026As power systems transition toward renewable-rich and inverter-dominated operations, accurate time-domain dynamic analysis becomes increasingly critical. Such analysis supports key operational tasks, including transient stability assessment, dynamic security analysis, contingency screening, and post-fault trajectory evaluation. In practice, these tasks may operate under several challenges, including unknown and time-varying system parameters, privacy constraints on data sharing, and the need for fast online inference. Existing learning-based approaches are typically trained for individual systems and therefore lack generalization across operating conditions and physical parameters. Hence, this paper proposes LArge Scale Small ODE (LASS)-ODE-Power, a learning framework for general-purpose time-domain prediction. The proposed approach leverages large-scale pretraining on more than 40 GB of DAE or ordinary differential-equation (ODE) trajectories to learn transferable representations. The resulting model supports trajectory prediction from short measurement prefixes across diverse dynamic regimes, including electromechanical and inverter-driven systems. Hence, the model can be directly used without data sharing in a zero-shot setting. In addition, the proposed architecture incorporates parallel and linearized computation to achieve fast inference. Moreover, to enhance task-specific performance in power systems, a specialized fine-tuning strategy is developed based on approximately 1 GB of heterogeneous power-system dynamic data. Extensive experiments over diverse power-system simulation scenarios demonstrate that LASS-ODE-Power consistently outperforms existing learning-based models in trajectory prediction accuracy with efficient inference.
Context-specific Credibility-aware Multimodal Fusion with Conditional Probabilistic Circuits
Mar 27, 2026Multimodal fusion requires integrating information from multiple sources that may conflict depending on context. Existing fusion approaches typically rely on static assumptions about source reliability, limiting their ability to resolve conflicts when a modality becomes unreliable due to situational factors such as sensor degradation or class-specific corruption. We introduce C$^2$MF, a context-specfic credibility-aware multimodal fusion framework that models per-instance source reliability using a Conditional Probabilistic Circuit (CPC). We formalize instance-level reliability through Context-Specific Information Credibility (CSIC), a KL-divergence-based measure computed exactly from the CPC. CSIC generalizes conventional static credibility estimates as a special case, enabling principled and adaptive reliability assessment. To evaluate robustness under cross-modal conflicts, we propose the Conflict benchmark, in which class-specific corruptions deliberately induce discrepancies between different modalities. Experimental results show that C$^2$MF improves predictive accuracy by up to 29% over static-reliability baselines in high-noise settings, while preserving the interpretability advantages of probabilistic circuit-based fusion.
Retrieval-Guided Photovoltaic Inventory Estimation from Satellite Imagery for Distribution Grid Planning
Mar 24, 2026The rapid expansion of distributed rooftop photovoltaic (PV) systems introduces increasing uncertainty in distribution grid planning, hosting capacity assessment, and voltage regulation. Reliable estimation of rooftop PV deployment from satellite imagery is therefore essential for accurate modeling of distributed generation at feeder and service-territory scales. However, conventional computer vision approaches rely on fixed learned representations and globally averaged visual correlations. This makes them sensitive to geographic distribution shifts caused by differences in roof materials, urban morphology, and imaging conditions across regions. To address these challenges, this paper proposes Solar Retrieval-Augmented Generation (Solar-RAG), a context-grounded framework for photovoltaic assessment that integrates similarity-based image retrieval with multimodal vision-language reasoning. Instead of producing predictions solely from internal model parameters, the proposed approach retrieves visually similar rooftop scenes with verified annotations and performs comparative reasoning against these examples during inference. This retrieval-guided mechanism provides geographically contextualized references that improve robustness under heterogeneous urban environments without requiring model retraining. The method outperform both conventional deep vision models and standalone vision-language models. Furthermore, feeder-level case studies show that improved PV inventory estimation reduces errors in voltage deviation analysis and hosting capacity assessment. The results demonstrate that the proposed method provides a scalable and geographically robust approach for monitoring distributed PV deployment. This enables more reliable integration of remote sensing data into distribution grid planning and distributed energy resource management.
LASS-ODE: Scaling ODE Computations to Connect Foundation Models with Dynamical Physical Systems
Feb 01, 2026Foundation models have transformed language, vision, and time series data analysis, yet progress on dynamic predictions for physical systems remains limited. Given the complexity of physical constraints, two challenges stand out. $(i)$ Physics-computation scalability: physics-informed learning can enforce physical regularization, but its computation (e.g., ODE integration) does not scale to extensive systems. $(ii)$ Knowledge-sharing efficiency: the attention mechanism is primarily computed within each system, which limits the extraction of shared ODE structures across systems. We show that enforcing ODE consistency does not require expensive nonlinear integration: a token-wise locally linear ODE representation preserves physical fidelity while scaling to foundation-model regimes. Thus, we propose novel token representations that respect locally linear ODE evolution. Such linearity substantially accelerates integration while accurately approximating the local data manifold. Second, we introduce a simple yet effective inter-system attention that augments attention with a common structure hub (CSH) that stores shared tokens and aggregates knowledge across systems. The resulting model, termed LASS-ODE (\underline{LA}rge-\underline{S}cale \underline{S}mall \underline{ODE}), is pretrained on our $40$GB ODE trajectory collections to enable strong in-domain performance, zero-shot generalization across diverse ODE systems, and additional improvements through fine-tuning.
Autonomous Self-Healing UAV Swarms for Robust 6G Non-Terrestrial Networks
Jan 19, 2026Recent years have seen an increased interest in the use of Non-terrestrial networks (NTNs), especially the unmanned aerial vehicles (UAVs) to provide cost-effective global connectivity in next-generation wireless networks. We introduce a resilient, adaptive, self-healing network design (RASHND) to optimize signal quality under dynamic interference and adversarial conditions. RASHND leverages inter-node communication and an intelligent algorithm selection process, incorporating combining techniques like distributed-Maximal Ratio Combining (d-MRC), distributed-Linear Minimum Mean Squared Error Estimation(d-LMMSE), and Selection Combining (SC). These algorithms are selected to improve performance by adapting to changing network conditions. To evaluate the effectiveness of the proposed RASHND solutions, a software-defined radio (SDR)-based hardware testbed afforded initial testing and evaluations. Additionally, we present results from UAV tests conducted on the AERPAW testbed to validate our solutions in real-world scenarios. The results demonstrate that RASHND significantly enhances the reliability and interference resilience of UAV networks, making them well-suited for critical communications.
Stone Soup: ADS-B-based Multi-Target Tracking with Stochastic Integration Filter
Jun 09, 2025This paper focuses on the multi-target tracking using the Stone Soup framework. In particular, we aim at evaluation of two multi-target tracking scenarios based on the simulated class-B dataset and ADS-B class-A dataset provided by OpenSky Network. The scenarios are evaluated w.r.t. selection of a local state estimator using a range of the Stone Soup metrics. Source code with scenario definitions and Stone Soup set-up are provided along with the paper.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025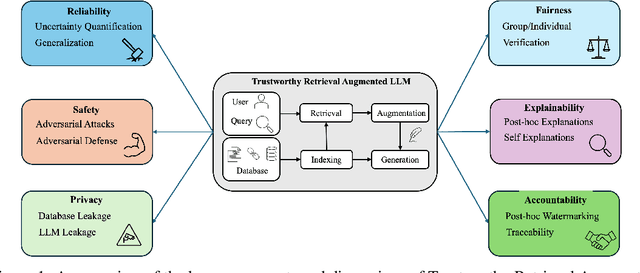
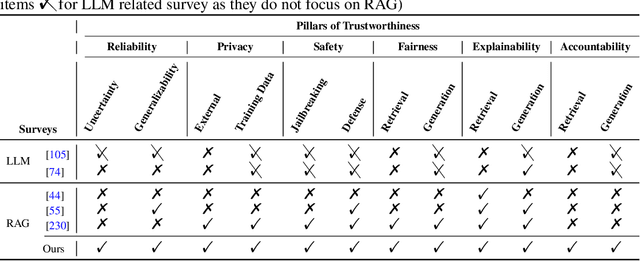


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Stochastic Integration Based Estimator: Robust Design and Stone Soup Implementation
Dec 10, 2024This paper deals with state estimation of nonlinear stochastic dynamic models. In particular, the stochastic integration rule, which provides asymptotically unbiased estimates of the moments of nonlinearly transformed Gaussian random variables, is reviewed together with the recently introduced stochastic integration filter (SIF). Using SIF, the respective multi-step prediction and smoothing algorithms are developed in full and efficient square-root form. The stochastic-integration-rule-based algorithms are implemented in Python (within the Stone Soup framework) and in MATLAB and are numerically evaluated and compared with the well-known unscented and extended Kalman filters using the Stone Soup defined tracking scenario.
Towards Trustworthy Knowledge Graph Reasoning: An Uncertainty Aware Perspective
Oct 11, 2024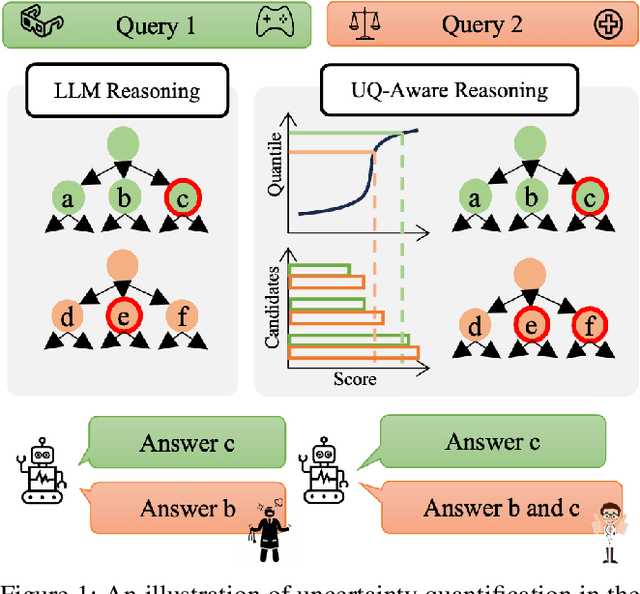



Recently, Knowledge Graphs (KGs) have been successfully coupled with Large Language Models (LLMs) to mitigate their hallucinations and enhance their reasoning capability, such as in KG-based retrieval-augmented frameworks. However, current KG-LLM frameworks lack rigorous uncertainty estimation, limiting their reliable deployment in high-stakes applications. Directly incorporating uncertainty quantification into KG-LLM frameworks presents challenges due to their complex architectures and the intricate interactions between the knowledge graph and language model components. To address this gap, we propose a new trustworthy KG-LLM framework, Uncertainty Aware Knowledge-Graph Reasoning (UAG), which incorporates uncertainty quantification into the KG-LLM framework. We design an uncertainty-aware multi-step reasoning framework that leverages conformal prediction to provide a theoretical guarantee on the prediction set. To manage the error rate of the multi-step process, we additionally introduce an error rate control module to adjust the error rate within the individual components. Extensive experiments show that our proposed UAG can achieve any pre-defined coverage rate while reducing the prediction set/interval size by 40% on average over the baselines.
Efficient Temporal Action Segmentation via Boundary-aware Query Voting
May 25, 2024Although the performance of Temporal Action Segmentation (TAS) has improved in recent years, achieving promising results often comes with a high computational cost due to dense inputs, complex model structures, and resource-intensive post-processing requirements. To improve the efficiency while keeping the performance, we present a novel perspective centered on per-segment classification. By harnessing the capabilities of Transformers, we tokenize each video segment as an instance token, endowed with intrinsic instance segmentation. To realize efficient action segmentation, we introduce BaFormer, a boundary-aware Transformer network. It employs instance queries for instance segmentation and a global query for class-agnostic boundary prediction, yielding continuous segment proposals. During inference, BaFormer employs a simple yet effective voting strategy to classify boundary-wise segments based on instance segmentation. Remarkably, as a single-stage approach, BaFormer significantly reduces the computational costs, utilizing only 6% of the running time compared to state-of-the-art method DiffAct, while producing better or comparable accuracy over several popular benchmarks. The code for this project is publicly available at https://github.com/peiyao-w/BaFormer.