 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Consistent Taxonomic Classification through Hierarchical Reasoning
Jan 21, 2026While Vision-Language Models (VLMs) excel at visual understanding, they often fail to grasp hierarchical knowledge. This leads to common errors where VLMs misclassify coarser taxonomic levels even when correctly identifying the most specific level (leaf level). Existing approaches largely overlook this issue by failing to model hierarchical reasoning. To address this gap, we propose VL-Taxon, a two-stage, hierarchy-based reasoning framework designed to improve both leaf-level accuracy and hierarchical consistency in taxonomic classification. The first stage employs a top-down process to enhance leaf-level classification accuracy. The second stage then leverages this accurate leaf-level output to ensure consistency throughout the entire taxonomic hierarchy. Each stage is initially trained with supervised fine-tuning to instill taxonomy knowledge, followed by reinforcement learning to refine the model's reasoning and generalization capabilities. Extensive experiments reveal a remarkable result: our VL-Taxon framework, implemented on the Qwen2.5-VL-7B model, outperforms its original 72B counterpart by over 10% in both leaf-level and hierarchical consistency accuracy on average on the iNaturalist-2021 dataset. Notably, this significant gain was achieved by fine-tuning on just a small subset of data, without relying on any examples generated by other VLMs.
ASBA: A-line State Space Model and B-line Attention for Sparse Optical Doppler Tomography Reconstruction
Jan 20, 2026Optical Doppler Tomography (ODT) is an emerging blood flow analysis technique. A 2D ODT image (B-scan) is generated by sequentially acquiring 1D depth-resolved raw A-scans (A-line) along the lateral axis (B-line), followed by Doppler phase-subtraction analysis. To ensure high-fidelity B-scan images, current practices rely on dense sampling, which prolongs scanning time, increases storage demands, and limits the capture of rapid blood flow dynamics. Recent studies have explored sparse sampling of raw A-scans to alleviate these limitations, but their effectiveness is hindered by the conservative sampling rates and the uniform modeling of flow and background signals. In this study, we introduce a novel blood flow-aware network, named ASBA (A-line ROI State space model and B-line phase Attention), to reconstruct ODT images from highly sparsely sampled raw A-scans. Specifically, we propose an A-line ROI state space model to extract sparsely distributed flow features along the A-line, and a B-line phase attention to capture long-range flow signals along each B-line based on phase difference. Moreover, we introduce a flow-aware weighted loss function that encourages the network to prioritize the accurate reconstruction of flow signals. Extensive experiments on real animal data demonstrate that the proposed approach clearly outperforms existing state-of-the-art reconstruction methods.
Sparse Reconstruction of Optical Doppler Tomography Based on State Space Model
Apr 26, 2024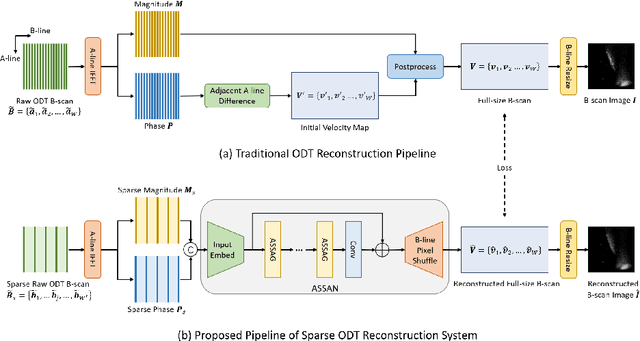
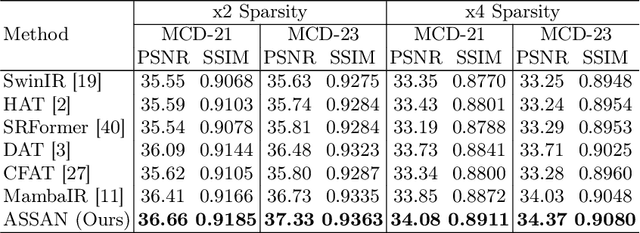
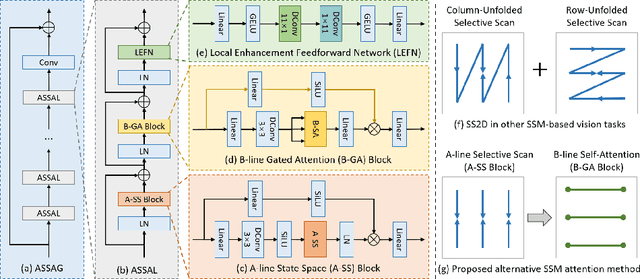

Optical Doppler Tomography (ODT) is a blood flow imaging technique popularly used in bioengineering applications. The fundamental unit of ODT is the 1D frequency response along the A-line (depth), named raw A-scan. A 2D ODT image (B-scan) is obtained by first sensing raw A-scans along the B-line (width), and then constructing the B-scan from these raw A-scans via magnitude-phase analysis and post-processing. To obtain a high-resolution B-scan with a precise flow map, densely sampled A-scans are required in current methods, causing both computational and storage burdens. To address this issue, in this paper we propose a novel sparse reconstruction framework with four main sequential steps: 1) early magnitude-phase fusion that encourages rich interaction of the complementary information in magnitude and phase, 2) State Space Model (SSM)-based representation learning, inspired by recent successes in Mamba and VMamba, to naturally capture both the intra-A-scan sequential information and between-A-scan interactions, 3) an Inception-based Feedforward Network module (IncFFN) to further boost the SSM-module, and 4) a B-line Pixel Shuffle (BPS) layer to effectively reconstruct the final results. In the experiments on real-world animal data, our method shows clear effectiveness in reconstruction accuracy. As the first application of SSM for image reconstruction tasks, we expect our work to inspire related explorations in not only efficient ODT imaging techniques but also generic image enhancement.
CCTV-Gun: Benchmarking Handgun Detection in CCTV Images
Apr 02, 2023



Gun violence is a critical security problem, and it is imperative for the computer vision community to develop effective gun detection algorithms for real-world scenarios, particularly in Closed Circuit Television (CCTV) surveillance data. Despite significant progress in visual object detection, detecting guns in real-world CCTV images remains a challenging and under-explored task. Firearms, especially handguns, are typically very small in size, non-salient in appearance, and often severely occluded or indistinguishable from other small objects. Additionally, the lack of principled benchmarks and difficulty collecting relevant datasets further hinder algorithmic development. In this paper, we present a meticulously crafted and annotated benchmark, called \textbf{CCTV-Gun}, which addresses the challenges of detecting handguns in real-world CCTV images. Our contribution is three-fold. Firstly, we carefully select and analyze real-world CCTV images from three datasets, manually annotate handguns and their holders, and assign each image with relevant challenge factors such as blur and occlusion. Secondly, we propose a new cross-dataset evaluation protocol in addition to the standard intra-dataset protocol, which is vital for gun detection in practical settings. Finally, we comprehensively evaluate both classical and state-of-the-art object detection algorithms, providing an in-depth analysis of their generalizing abilities. The benchmark will facilitate further research and development on this topic and ultimately enhance security. Code, annotations, and trained models are available at https://github.com/srikarym/CCTV-Gun.
Topic-to-Essay Generation with Comprehensive Knowledge Enhancement
Jun 29, 2021
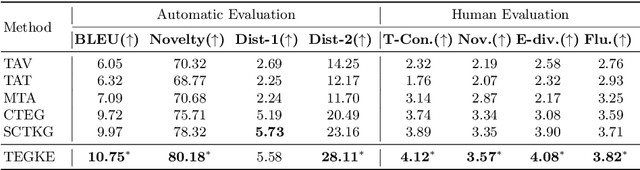

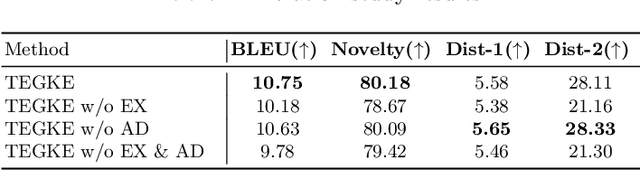
Generating high-quality and diverse essays with a set of topics is a challenging task in natural language generation. Since several given topics only provide limited source information, utilizing various topic-related knowledge is essential for improving essay generation performance. However, previous works cannot sufficiently use that knowledge to facilitate the generation procedure. This paper aims to improve essay generation by extracting information from both internal and external knowledge. Thus, a topic-to-essay generation model with comprehensive knowledge enhancement, named TEGKE, is proposed. For internal knowledge enhancement, both topics and related essays are fed to a teacher network as source information. Then, informative features would be obtained from the teacher network and transferred to a student network which only takes topics as input but provides comparable information compared with the teacher network. For external knowledge enhancement, a topic knowledge graph encoder is proposed. Unlike the previous works only using the nearest neighbors of topics in the commonsense base, our topic knowledge graph encoder could exploit more structural and semantic information of the commonsense knowledge graph to facilitate essay generation. Moreover, the adversarial training based on the Wasserstein distance is proposed to improve generation quality. Experimental results demonstrate that TEGKE could achieve state-of-the-art performance on both automatic and human evaluation.
Automated Detection of Equine Facial Action Units
Feb 17, 2021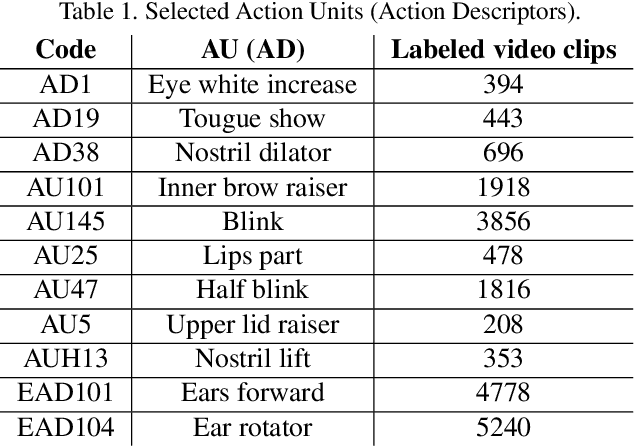

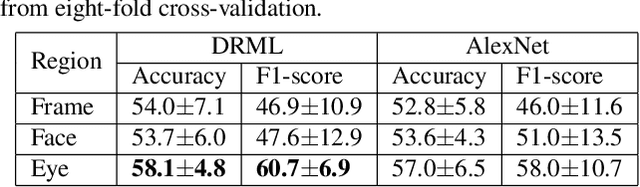

The recently developed Equine Facial Action Coding System (EquiFACS) provides a precise and exhaustive, but laborious, manual labelling method of facial action units of the horse. To automate parts of this process, we propose a Deep Learning-based method to detect EquiFACS units automatically from images. We use a cascade framework; we firstly train several object detectors to detect the predefined Region-of-Interest (ROI), and secondly apply binary classifiers for each action unit in related regions. We experiment with both regular CNNs and a more tailored model transferred from human facial action unit recognition. Promising initial results are presented for nine action units in the eye and lower face regions.