 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASBA: A-line State Space Model and B-line Attention for Sparse Optical Doppler Tomography Reconstruction
Jan 20, 2026Optical Doppler Tomography (ODT) is an emerging blood flow analysis technique. A 2D ODT image (B-scan) is generated by sequentially acquiring 1D depth-resolved raw A-scans (A-line) along the lateral axis (B-line), followed by Doppler phase-subtraction analysis. To ensure high-fidelity B-scan images, current practices rely on dense sampling, which prolongs scanning time, increases storage demands, and limits the capture of rapid blood flow dynamics. Recent studies have explored sparse sampling of raw A-scans to alleviate these limitations, but their effectiveness is hindered by the conservative sampling rates and the uniform modeling of flow and background signals. In this study, we introduce a novel blood flow-aware network, named ASBA (A-line ROI State space model and B-line phase Attention), to reconstruct ODT images from highly sparsely sampled raw A-scans. Specifically, we propose an A-line ROI state space model to extract sparsely distributed flow features along the A-line, and a B-line phase attention to capture long-range flow signals along each B-line based on phase difference. Moreover, we introduce a flow-aware weighted loss function that encourages the network to prioritize the accurate reconstruction of flow signals. Extensive experiments on real animal data demonstrate that the proposed approach clearly outperforms existing state-of-the-art reconstruction methods.
Sparse Reconstruction of Optical Doppler Tomography Based on State Space Model
Apr 26, 2024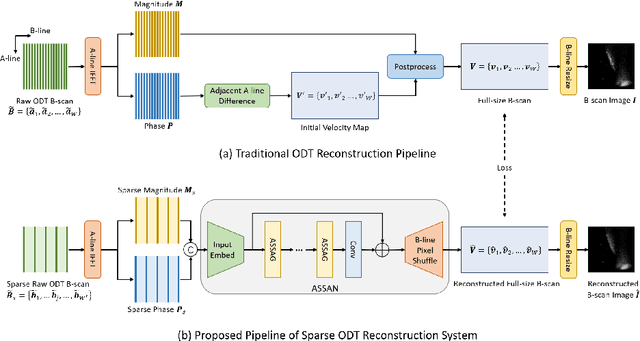
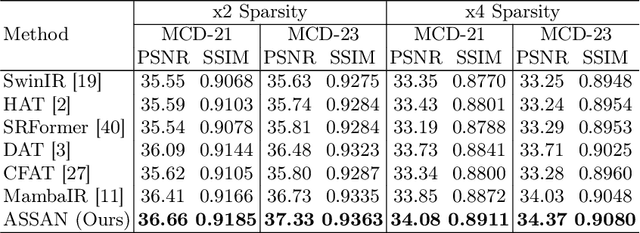
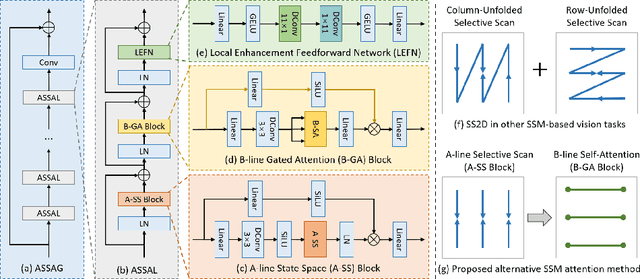

Optical Doppler Tomography (ODT) is a blood flow imaging technique popularly used in bioengineering applications. The fundamental unit of ODT is the 1D frequency response along the A-line (depth), named raw A-scan. A 2D ODT image (B-scan) is obtained by first sensing raw A-scans along the B-line (width), and then constructing the B-scan from these raw A-scans via magnitude-phase analysis and post-processing. To obtain a high-resolution B-scan with a precise flow map, densely sampled A-scans are required in current methods, causing both computational and storage burdens. To address this issue, in this paper we propose a novel sparse reconstruction framework with four main sequential steps: 1) early magnitude-phase fusion that encourages rich interaction of the complementary information in magnitude and phase, 2) State Space Model (SSM)-based representation learning, inspired by recent successes in Mamba and VMamba, to naturally capture both the intra-A-scan sequential information and between-A-scan interactions, 3) an Inception-based Feedforward Network module (IncFFN) to further boost the SSM-module, and 4) a B-line Pixel Shuffle (BPS) layer to effectively reconstruct the final results. In the experiments on real-world animal data, our method shows clear effectiveness in reconstruction accuracy. As the first application of SSM for image reconstruction tasks, we expect our work to inspire related explorations in not only efficient ODT imaging techniques but also generic image enhancement.
PM-VIS: High-Performance Box-Supervised Video Instance Segmentation
Apr 22, 2024

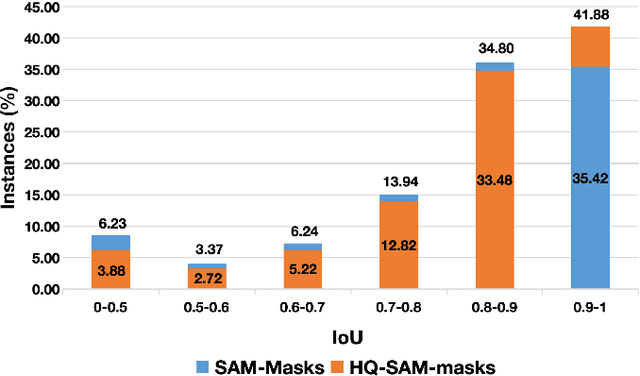
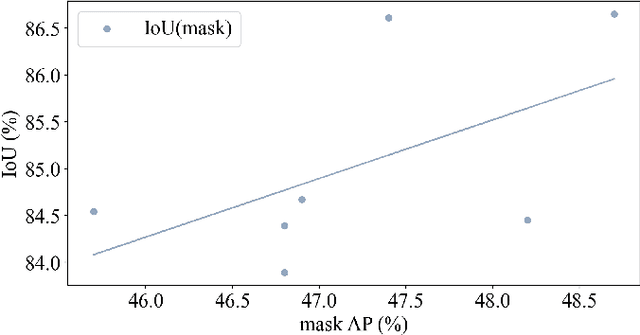
Labeling pixel-wise object masks in videos is a resource-intensive and laborious process. Box-supervised Video Instance Segmentation (VIS) methods have emerged as a viable solution to mitigate the labor-intensive annotation process. . In practical applications, the two-step approach is not only more flexible but also exhibits a higher recognition accuracy. Inspired by the recent success of Segment Anything Model (SAM), we introduce a novel approach that aims at harnessing instance box annotations from multiple perspectives to generate high-quality instance pseudo masks, thus enriching the information contained in instance annotations. We leverage ground-truth boxes to create three types of pseudo masks using the HQ-SAM model, the box-supervised VIS model (IDOL-BoxInst), and the VOS model (DeAOT) separately, along with three corresponding optimization mechanisms. Additionally, we introduce two ground-truth data filtering methods, assisted by high-quality pseudo masks, to further enhance the training dataset quality and improve the performance of fully supervised VIS methods. To fully capitalize on the obtained high-quality Pseudo Masks, we introduce a novel algorithm, PM-VIS, to integrate mask losses into IDOL-BoxInst. Our PM-VIS model, trained with high-quality pseudo mask annotations, demonstrates strong ability in instance mask prediction, achieving state-of-the-art performance on the YouTube-VIS 2019, YouTube-VIS 2021, and OVIS validation sets, notably narrowing the gap between box-supervised and fully supervised VIS methods.
GMOT-40: A Benchmark for Generic Multiple Object Tracking
Dec 02, 2020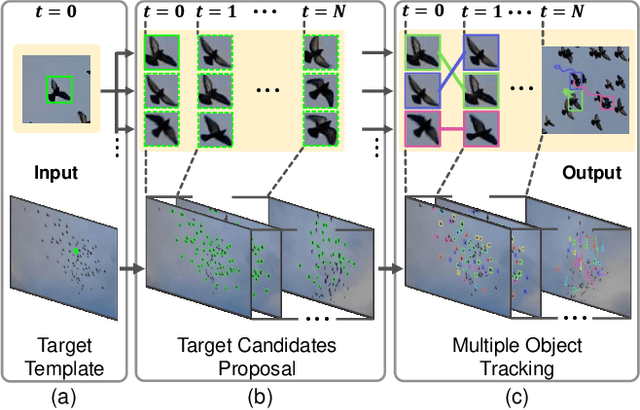
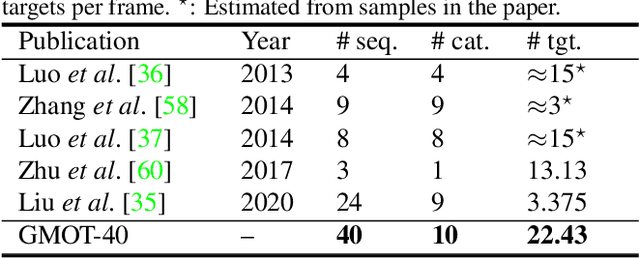
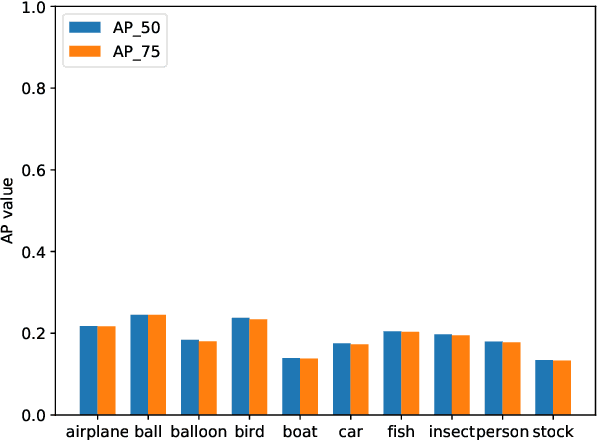

Multiple Object Tracking (MOT) has witnessed remarkable advances in recent years. However, existing studies dominantly request prior knowledge of the tracking target, and hence may not generalize well to unseen categories. In contrast, Generic Multiple Object Tracking (GMOT), which requires little prior information about the target, is largely under-explored. In this paper, we make contributions to boost the study of GMOT in three aspects. First, we construct the first public GMOT dataset, dubbed GMOT-40, which contains 40 carefully annotated sequences evenly distributed among 10 object categories. In addition, two tracking protocols are adopted to evaluate different characteristics of tracking algorithms. Second, by noting the lack of devoted tracking algorithms, we have designed a series of baseline GMOT algorithms. Third, we perform a thorough evaluation on GMOT-40, involving popular MOT algorithms (with necessary modifications) and the proposed baselines. We will release the GMOT-40 benchmark, the evaluation results, as well as the baseline algorithm to the public upon the publication of the paper.
Structure-Aware Network for Lane Marker Extraction with Dynamic Vision Sensor
Aug 14, 2020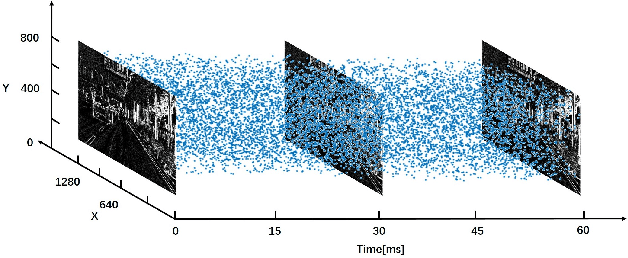

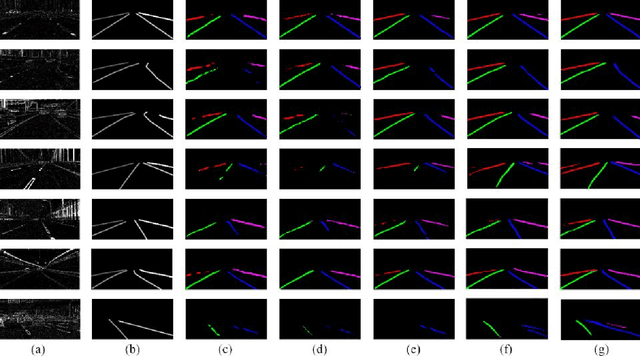

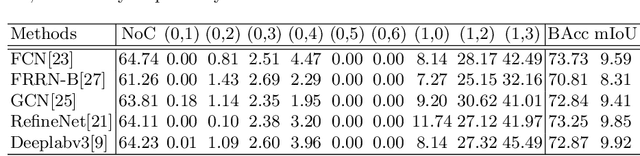
Lane marker extraction is a basic yet necessary task for autonomous driving. Although past years have witnessed major advances in lane marker extraction with deep learning models, they all aim at ordinary RGB images generated by frame-based cameras, which limits their performance in extreme cases, like huge illumination change. To tackle this problem, we introduce Dynamic Vision Sensor (DVS), a type of event-based sensor to lane marker extraction task and build a high-resolution DVS dataset for lane marker extraction. We collect the raw event data and generate 5,424 DVS images with a resolution of 1280$\times$800 pixels, the highest one among all DVS datasets available now. All images are annotated with multi-class semantic segmentation format. We then propose a structure-aware network for lane marker extraction in DVS images. It can capture directional information comprehensively with multidirectional slice convolution. We evaluate our proposed network with other state-of-the-art lane marker extraction models on this dataset. Experimental results demonstrate that our method outperforms other competitors. The dataset is made publicly available, including the raw event data, accumulated images and labels.
Semantic Change Pattern Analysis
Mar 07, 2020
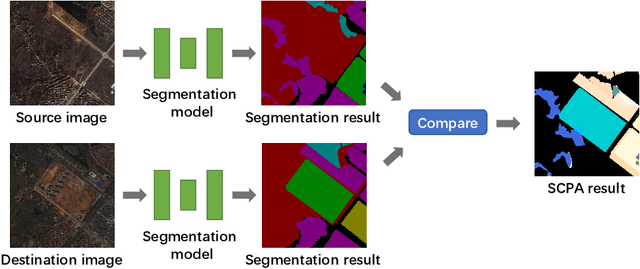
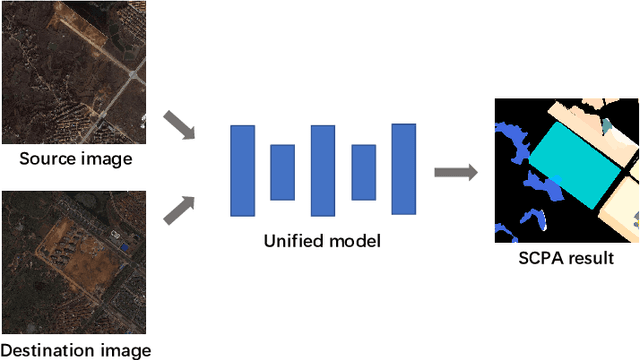
Change detection is an important problem in vision field, especially for aerial images. However, most works focus on traditional change detection, i.e., where changes happen, without considering the change type information, i.e., what changes happen. Although a few works have tried to apply semantic information to traditional change detection, they either only give the label of emerging objects without taking the change type into consideration, or set some kinds of change subjectively without specifying semantic information. To make use of semantic information and analyze change types comprehensively, we propose a new task called semantic change pattern analysis for aerial images. Given a pair of co-registered aerial images, the task requires a result including both where and what changes happen. We then describe the metric adopted for the task, which is clean and interpretable. We further provide the first well-annotated aerial image dataset for this task. Extensive baseline experiments are conducted as reference for following works. The aim of this work is to explore high-level information based on change detection and facilitate the development of this field with the publicly available dataset.