 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASBA: A-line State Space Model and B-line Attention for Sparse Optical Doppler Tomography Reconstruction
Jan 20, 2026Optical Doppler Tomography (ODT) is an emerging blood flow analysis technique. A 2D ODT image (B-scan) is generated by sequentially acquiring 1D depth-resolved raw A-scans (A-line) along the lateral axis (B-line), followed by Doppler phase-subtraction analysis. To ensure high-fidelity B-scan images, current practices rely on dense sampling, which prolongs scanning time, increases storage demands, and limits the capture of rapid blood flow dynamics. Recent studies have explored sparse sampling of raw A-scans to alleviate these limitations, but their effectiveness is hindered by the conservative sampling rates and the uniform modeling of flow and background signals. In this study, we introduce a novel blood flow-aware network, named ASBA (A-line ROI State space model and B-line phase Attention), to reconstruct ODT images from highly sparsely sampled raw A-scans. Specifically, we propose an A-line ROI state space model to extract sparsely distributed flow features along the A-line, and a B-line phase attention to capture long-range flow signals along each B-line based on phase difference. Moreover, we introduce a flow-aware weighted loss function that encourages the network to prioritize the accurate reconstruction of flow signals. Extensive experiments on real animal data demonstrate that the proposed approach clearly outperforms existing state-of-the-art reconstruction methods.
Sparse Reconstruction of Optical Doppler Tomography Based on State Space Model
Apr 26, 2024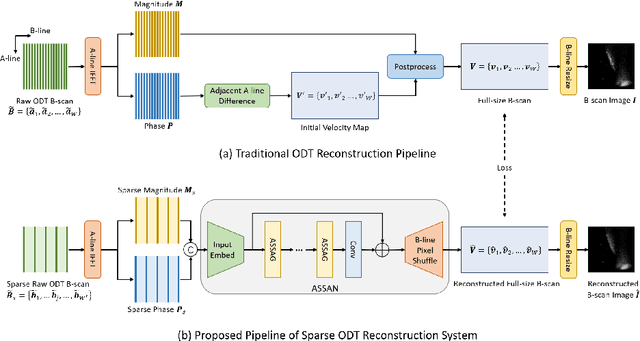
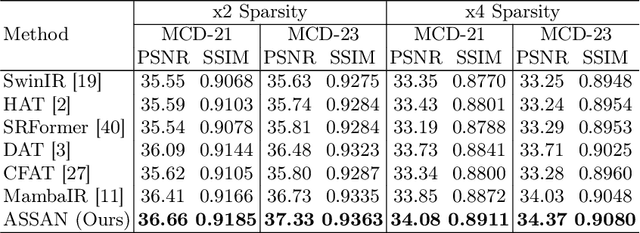
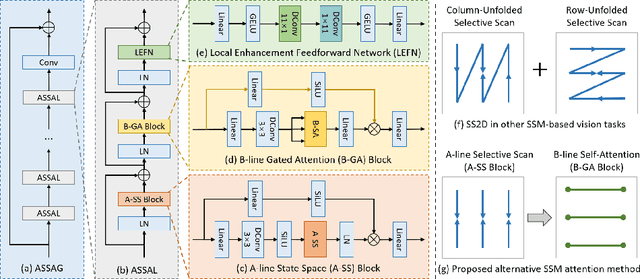

Optical Doppler Tomography (ODT) is a blood flow imaging technique popularly used in bioengineering applications. The fundamental unit of ODT is the 1D frequency response along the A-line (depth), named raw A-scan. A 2D ODT image (B-scan) is obtained by first sensing raw A-scans along the B-line (width), and then constructing the B-scan from these raw A-scans via magnitude-phase analysis and post-processing. To obtain a high-resolution B-scan with a precise flow map, densely sampled A-scans are required in current methods, causing both computational and storage burdens. To address this issue, in this paper we propose a novel sparse reconstruction framework with four main sequential steps: 1) early magnitude-phase fusion that encourages rich interaction of the complementary information in magnitude and phase, 2) State Space Model (SSM)-based representation learning, inspired by recent successes in Mamba and VMamba, to naturally capture both the intra-A-scan sequential information and between-A-scan interactions, 3) an Inception-based Feedforward Network module (IncFFN) to further boost the SSM-module, and 4) a B-line Pixel Shuffle (BPS) layer to effectively reconstruct the final results. In the experiments on real-world animal data, our method shows clear effectiveness in reconstruction accuracy. As the first application of SSM for image reconstruction tasks, we expect our work to inspire related explorations in not only efficient ODT imaging techniques but also generic image enhancement.
Self-Supervised Bulk Motion Artifact Removal in Optical Coherence Tomography Angiography
Mar 27, 2022



Optical coherence tomography angiography (OCTA) is an important imaging modality in many bioengineering tasks. The image quality of OCTA, however, is often degraded by Bulk Motion Artifacts (BMA), which are due to micromotion of subjects and typically appear as bright stripes surrounded by blurred areas. State-of-the-art methods usually treat BMA removal as a learning-based image inpainting problem, but require numerous training samples with nontrivial annotation. In addition, these methods discard the rich structural and appearance information carried in the BMA stripe region. To address these issues, in this paper we propose a self-supervised content-aware BMA removal model. First, the gradient-based structural information and appearance feature are extracted from the BMA area and injected into the model to capture more connectivity. Second, with easily collected defective masks, the model is trained in a self-supervised manner, in which only the clear areas are used for training while the BMA areas for inference. With the structural information and appearance feature from noisy image as references, our model can remove larger BMA and produce better visualizing result. In addition, only 2D images with defective masks are involved, hence improving the efficiency of our method. Experiments on OCTA of mouse cortex demonstrate that our model can remove most BMA with extremely large sizes and inconsistent intensities while previous methods fail.