 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePM-VIS+: High-Performance Video Instance Segmentation without Video Annotation
Jun 28, 2024Video instance segmentation requires detecting, segmenting, and tracking objects in videos, typically relying on costly video annotations. This paper introduces a method that eliminates video annotations by utilizing image datasets. The PM-VIS algorithm is adapted to handle both bounding box and instance-level pixel annotations dynamically. We introduce ImageNet-bbox to supplement missing categories in video datasets and propose the PM-VIS+ algorithm to adjust supervision based on annotation types. To enhance accuracy, we use pseudo masks and semi-supervised optimization techniques on unannotated video data. This method achieves high video instance segmentation performance without manual video annotations, offering a cost-effective solution and new perspectives for video instance segmentation applications. The code will be available in https://github.com/ldknight/PM-VIS-plus
PM-VIS: High-Performance Box-Supervised Video Instance Segmentation
Apr 22, 2024

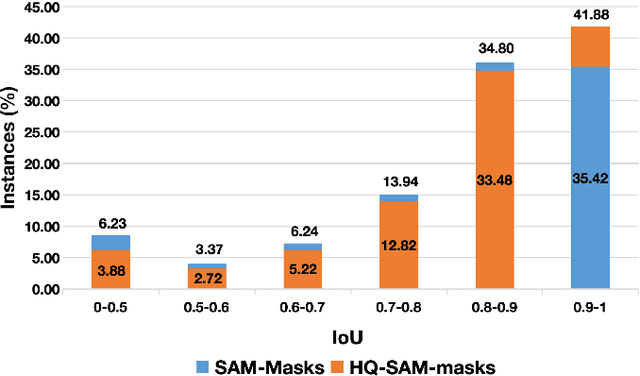
Labeling pixel-wise object masks in videos is a resource-intensive and laborious process. Box-supervised Video Instance Segmentation (VIS) methods have emerged as a viable solution to mitigate the labor-intensive annotation process. . In practical applications, the two-step approach is not only more flexible but also exhibits a higher recognition accuracy. Inspired by the recent success of Segment Anything Model (SAM), we introduce a novel approach that aims at harnessing instance box annotations from multiple perspectives to generate high-quality instance pseudo masks, thus enriching the information contained in instance annotations. We leverage ground-truth boxes to create three types of pseudo masks using the HQ-SAM model, the box-supervised VIS model (IDOL-BoxInst), and the VOS model (DeAOT) separately, along with three corresponding optimization mechanisms. Additionally, we introduce two ground-truth data filtering methods, assisted by high-quality pseudo masks, to further enhance the training dataset quality and improve the performance of fully supervised VIS methods. To fully capitalize on the obtained high-quality Pseudo Masks, we introduce a novel algorithm, PM-VIS, to integrate mask losses into IDOL-BoxInst. Our PM-VIS model, trained with high-quality pseudo mask annotations, demonstrates strong ability in instance mask prediction, achieving state-of-the-art performance on the YouTube-VIS 2019, YouTube-VIS 2021, and OVIS validation sets, notably narrowing the gap between box-supervised and fully supervised VIS methods.