 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Modeling of Equine Activity Budgets Using a 3D Skeleton Reconstructed from Surveillance Recordings
Jun 08, 2023



In this work, we present a pipeline to reconstruct the 3D pose of a horse from 4 simultaneous surveillance camera recordings. Our environment poses interesting challenges to tackle, such as limited field view of the cameras and a relatively closed and small environment. The pipeline consists of training a 2D markerless pose estimation model to work on every viewpoint, then applying it to the videos and performing triangulation. We present numerical evaluation of the results (error analysis), as well as show the utility of the achieved poses in downstream tasks of selected behavioral predictions. Our analysis of the predictive model for equine behavior showed a bias towards pain-induced horses, which aligns with our understanding of how behavior varies across painful and healthy subjects.
Going Deeper than Tracking: a Survey of Computer-Vision Based Recognition of Animal Pain and Affective States
Jun 16, 2022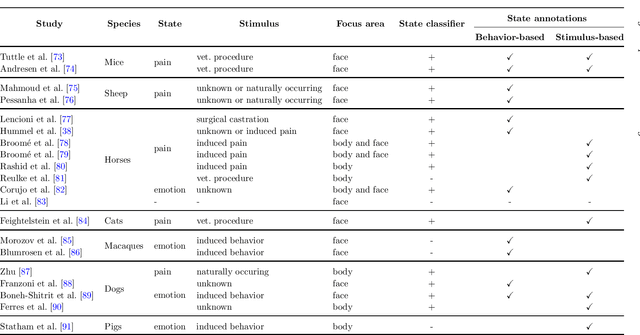
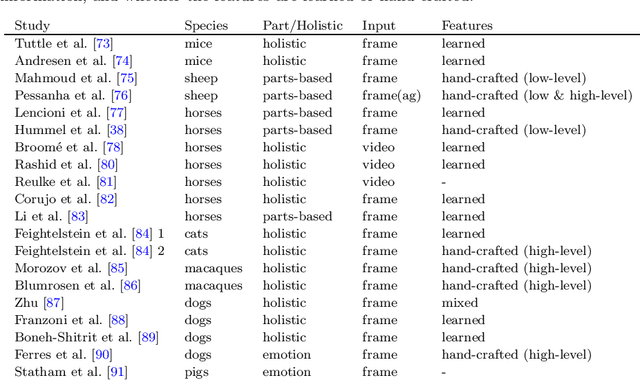
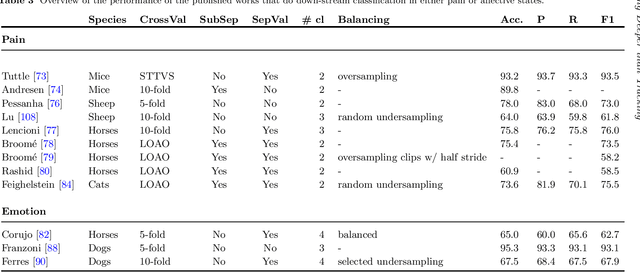

Advances in animal motion tracking and pose recognition have been a game changer in the study of animal behavior. Recently, an increasing number of works go 'deeper' than tracking, and address automated recognition of animals' internal states such as emotions and pain with the aim of improving animal welfare, making this a timely moment for a systematization of the field. This paper provides a comprehensive survey of computer vision-based research on recognition of affective states and pain in animals, addressing both facial and bodily behavior analysis. We summarize the efforts that have been presented so far within this topic -- classifying them across different dimensions, highlight challenges and research gaps, and provide best practice recommendations for advancing the field, and some future directions for research.
Recur, Attend or Convolve? Frame Dependency Modeling Matters for Cross-Domain Robustness in Action Recognition
Dec 22, 2021

Most action recognition models today are highly parameterized, and evaluated on datasets with predominantly spatially distinct classes. Previous results for single images have shown that 2D Convolutional Neural Networks (CNNs) tend to be biased toward texture rather than shape for various computer vision tasks (Geirhos et al., 2019), reducing generalization. Taken together, this raises suspicion that large video models learn spurious correlations rather than to track relevant shapes over time and infer generalizable semantics from their movement. A natural way to avoid parameter explosion when learning visual patterns over time is to make use of recurrence across the time-axis. In this article, we empirically study the cross-domain robustness for recurrent, attention-based and convolutional video models, respectively, to investigate whether this robustness is influenced by the frame dependency modeling. Our novel Temporal Shape dataset is proposed as a light-weight dataset to assess the ability to generalize across temporal shapes which are not revealed from single frames. We find that when controlling for performance and layer structure, recurrent models show better out-of-domain generalization ability on the Temporal Shape dataset than convolution- and attention-based models. Moreover, our experiments indicate that convolution- and attention-based models exhibit more texture bias on Diving48 than recurrent models.
Equine Pain Behavior Classification via Self-Supervised Disentangled Pose Representation
Aug 30, 2021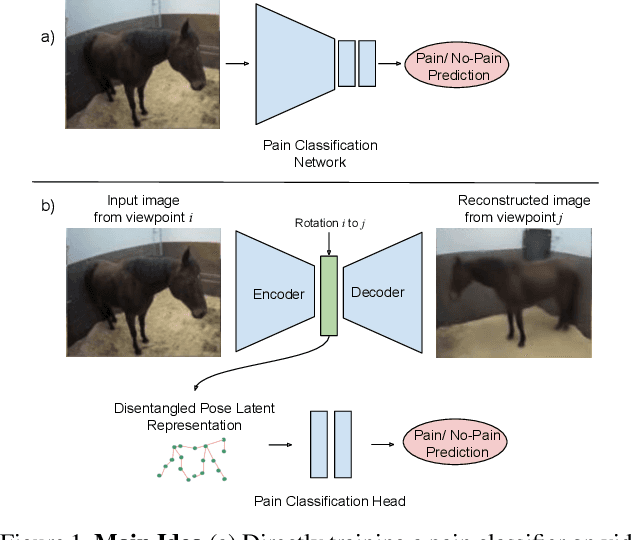
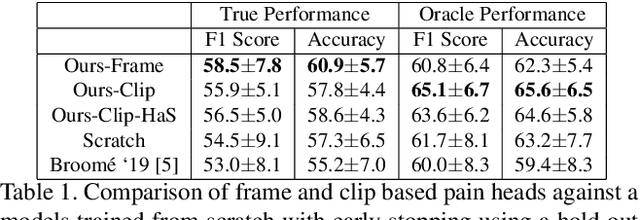
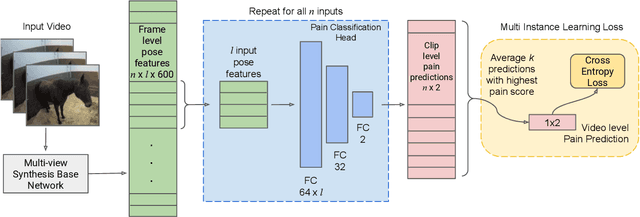

Timely detection of horse pain is important for equine welfare. Horses express pain through their facial and body behavior, but may hide signs of pain from unfamiliar human observers. In addition, collecting visual data with detailed annotation of horse behavior and pain state is both cumbersome and not scalable. Consequently, a pragmatic equine pain classification system would use video of the unobserved horse and weak labels. This paper proposes such a method for equine pain classification by using multi-view surveillance video footage of unobserved horses with induced orthopaedic pain, with temporally sparse video level pain labels. To ensure that pain is learned from horse body language alone, we first train a self-supervised generative model to disentangle horse pose from its appearance and background before using the disentangled horse pose latent representation for pain classification. To make best use of the pain labels, we develop a novel loss that formulates pain classification as a multi-instance learning problem. Our method achieves pain classification accuracy better than human expert performance with 60% accuracy. The learned latent horse pose representation is shown to be viewpoint covariant, and disentangled from horse appearance. Qualitative analysis of pain classified segments shows correspondence between the pain symptoms identified by our model, and equine pain scales used in veterinary practice.
hSMAL: Detailed Horse Shape and Pose Reconstruction for Motion Pattern Recognition
Jun 18, 2021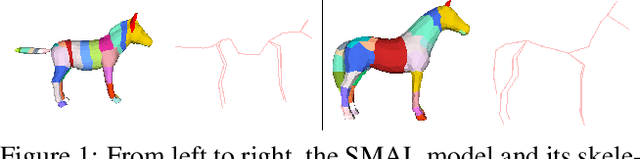
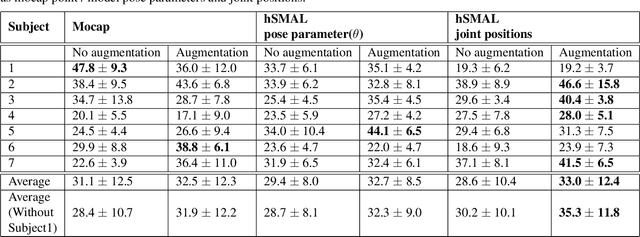
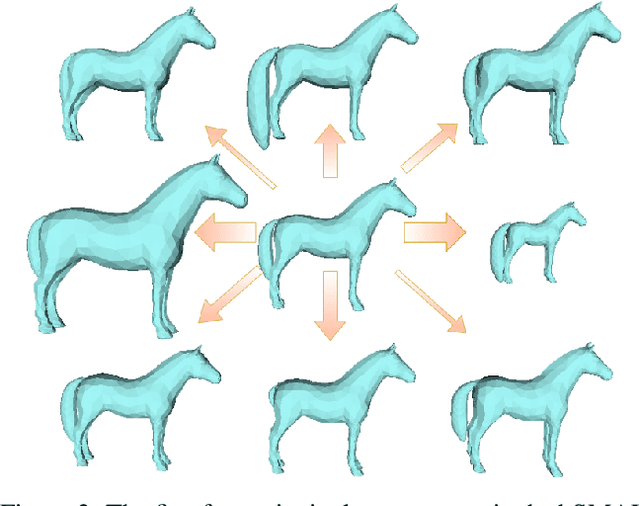
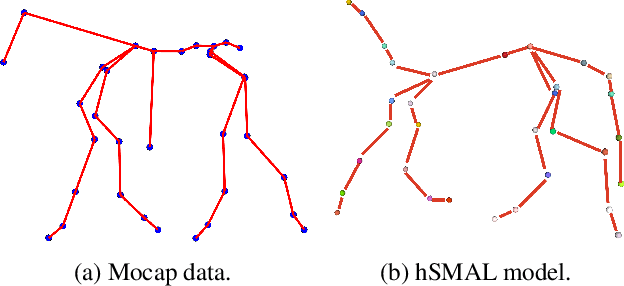
In this paper we present our preliminary work on model-based behavioral analysis of horse motion. Our approach is based on the SMAL model, a 3D articulated statistical model of animal shape. We define a novel SMAL model for horses based on a new template, skeleton and shape space learned from $37$ horse toys. We test the accuracy of our hSMAL model in reconstructing a horse from 3D mocap data and images. We apply the hSMAL model to the problem of lameness detection from video, where we fit the model to images to recover 3D pose and train an ST-GCN network on pose data. A comparison with the same network trained on mocap points illustrates the benefit of our approach.
Sharing Pain: Using Domain Transfer Between Pain Types for Recognition of Sparse Pain Expressions in Horses
May 21, 2021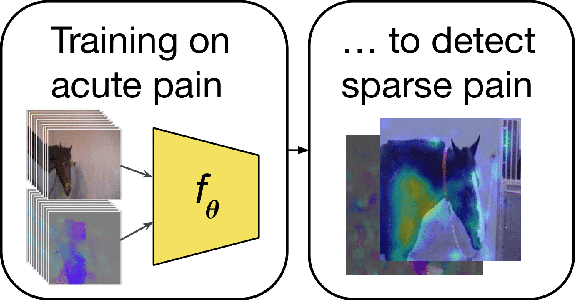

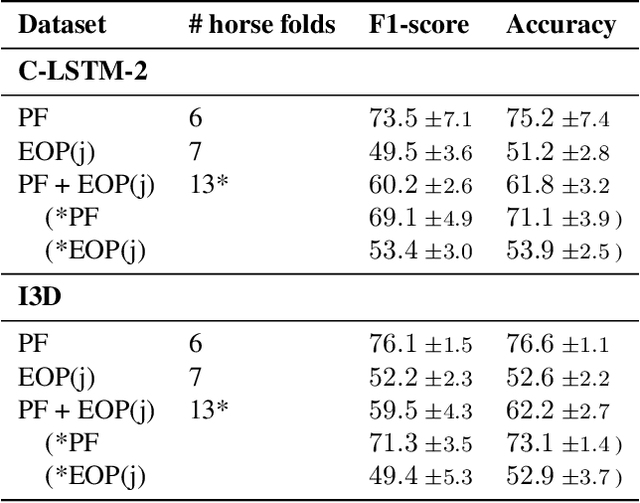
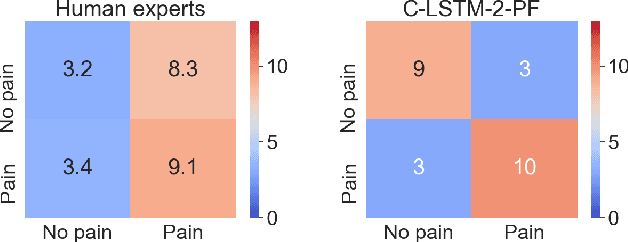
Orthopedic disorders are a common cause for euthanasia among horses, which often could have been avoided with earlier detection. These conditions often create varying degrees of subtle but long-term pain. It is challenging to train a visual pain recognition method with video data depicting such pain, since the resulting pain behavior also is subtle, sparsely appearing, and varying, making it challenging for even an expert human labeler to provide accurate ground-truth for the data. We show that transferring features from a dataset of horses with acute nociceptive pain (where labeling is less ambiguous) can aid the learning to recognize more complex orthopedic pain. Moreover, we present a human expert baseline for the problem, as well as an extensive empirical study of various domain transfer methods and of what is detected by the pain recognition method trained on acute pain in the orthopedic dataset. Finally, this is accompanied with a discussion around the challenges posed by real-world animal behavior datasets and how best practices can be established for similar fine-grained action recognition tasks. Our code is available at https://github.com/sofiabroome/painface-recognition.
Automated Detection of Equine Facial Action Units
Feb 17, 2021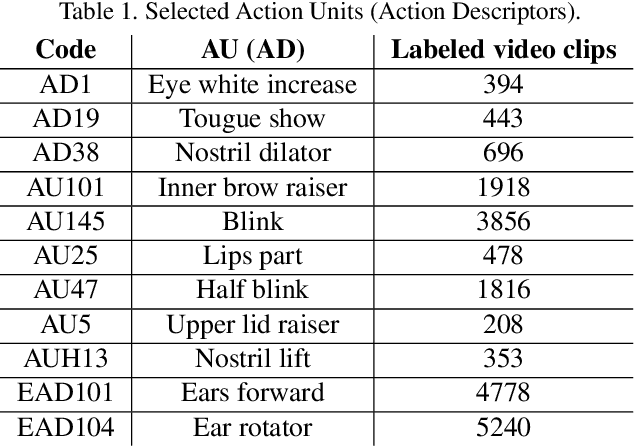


The recently developed Equine Facial Action Coding System (EquiFACS) provides a precise and exhaustive, but laborious, manual labelling method of facial action units of the horse. To automate parts of this process, we propose a Deep Learning-based method to detect EquiFACS units automatically from images. We use a cascade framework; we firstly train several object detectors to detect the predefined Region-of-Interest (ROI), and secondly apply binary classifiers for each action unit in related regions. We experiment with both regular CNNs and a more tailored model transferred from human facial action unit recognition. Promising initial results are presented for nine action units in the eye and lower face regions.
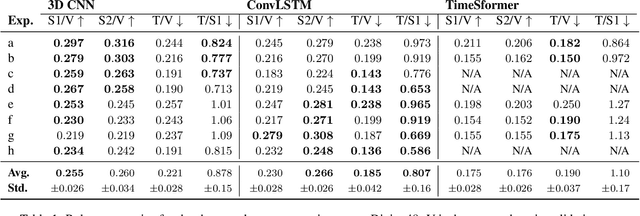
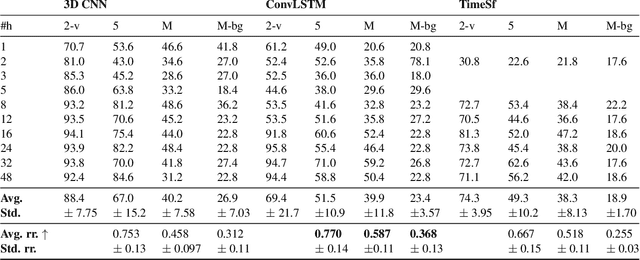
Interpreting video features: a comparison of 3D convolutional networks and convolutional LSTM networks
Feb 02, 2020


A number of techniques for interpretability have been presented for deep learning in computer vision, typically with the goal of understanding what it is that the networks have actually learned underneath a given classification decision. However, when it comes to deep video architectures, interpretability is still in its infancy and we do not yet have a clear concept of how we should decode spatiotemporal features. In this paper, we present a study comparing how 3D convolutional networks and convolutional LSTM networks learn features across temporally dependent frames. This is the first comparison of two video models that both convolve to learn spatial features but that have principally different methods of modeling time. Additionally, we extend the concept of meaningful perturbation introduced by Fong & Vedaldi (2017) to the temporal dimension to search for the most meaningful part of a sequence for a classification decision.
Dynamics are Important for the Recognition of Equine Pain in Video
Jan 07, 2019

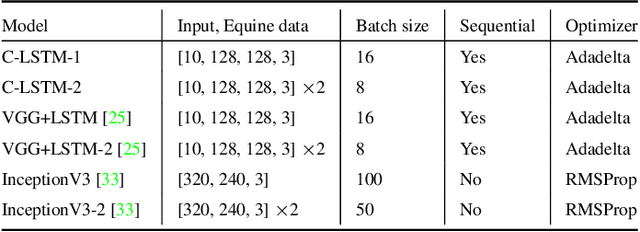
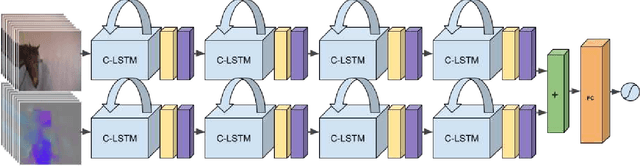
A prerequisite to successfully alleviate pain in animals is to recognize it, which is a great challenge in non-verbal species. Furthermore, prey animals such as horses tend to hide their pain. In this study, we propose a deep recurrent two-stream architecture for the task of distinguishing pain from non-pain in videos of horses. Different models are evaluated on a unique dataset showing horses under controlled trials with moderate pain induction, which has been presented in earlier work. Sequential models are experimentally compared to single-frame models, showing the importance of the temporal dimension of the data, and are benchmarked against a veterinary expert classification of the data. We additionally perform baseline comparisons with generalized versions of state-of-the-art human pain recognition methods. While equine pain detection in machine learning is a novel field, our results surpass veterinary expert performance and outperform pain detection results reported for other larger non-human species.