 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecur, Attend or Convolve? Frame Dependency Modeling Matters for Cross-Domain Robustness in Action Recognition
Paper and Code

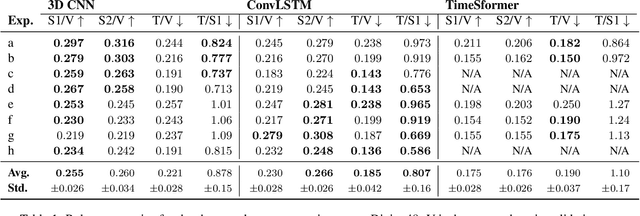

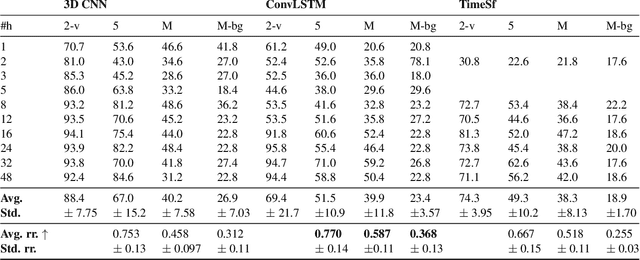
Most action recognition models today are highly parameterized, and evaluated on datasets with predominantly spatially distinct classes. Previous results for single images have shown that 2D Convolutional Neural Networks (CNNs) tend to be biased toward texture rather than shape for various computer vision tasks (Geirhos et al., 2019), reducing generalization. Taken together, this raises suspicion that large video models learn spurious correlations rather than to track relevant shapes over time and infer generalizable semantics from their movement. A natural way to avoid parameter explosion when learning visual patterns over time is to make use of recurrence across the time-axis. In this article, we empirically study the cross-domain robustness for recurrent, attention-based and convolutional video models, respectively, to investigate whether this robustness is influenced by the frame dependency modeling. Our novel Temporal Shape dataset is proposed as a light-weight dataset to assess the ability to generalize across temporal shapes which are not revealed from single frames. We find that when controlling for performance and layer structure, recurrent models show better out-of-domain generalization ability on the Temporal Shape dataset than convolution- and attention-based models. Moreover, our experiments indicate that convolution- and attention-based models exhibit more texture bias on Diving48 than recurrent models.