 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Modeling of Equine Activity Budgets Using a 3D Skeleton Reconstructed from Surveillance Recordings
Jun 08, 2023



In this work, we present a pipeline to reconstruct the 3D pose of a horse from 4 simultaneous surveillance camera recordings. Our environment poses interesting challenges to tackle, such as limited field view of the cameras and a relatively closed and small environment. The pipeline consists of training a 2D markerless pose estimation model to work on every viewpoint, then applying it to the videos and performing triangulation. We present numerical evaluation of the results (error analysis), as well as show the utility of the achieved poses in downstream tasks of selected behavioral predictions. Our analysis of the predictive model for equine behavior showed a bias towards pain-induced horses, which aligns with our understanding of how behavior varies across painful and healthy subjects.
Recur, Attend or Convolve? Frame Dependency Modeling Matters for Cross-Domain Robustness in Action Recognition
Dec 22, 2021
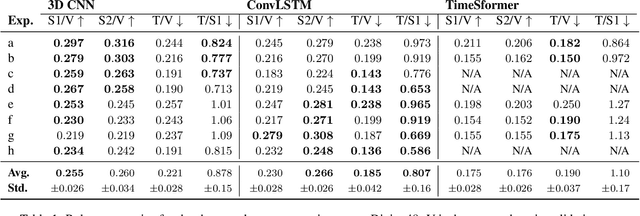

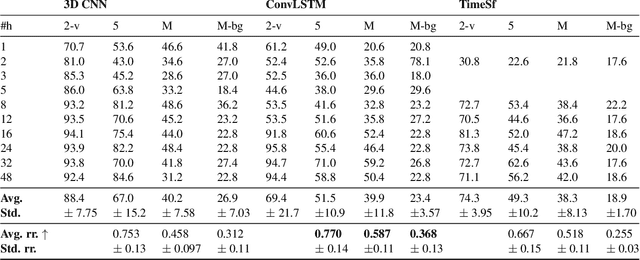
Most action recognition models today are highly parameterized, and evaluated on datasets with predominantly spatially distinct classes. Previous results for single images have shown that 2D Convolutional Neural Networks (CNNs) tend to be biased toward texture rather than shape for various computer vision tasks (Geirhos et al., 2019), reducing generalization. Taken together, this raises suspicion that large video models learn spurious correlations rather than to track relevant shapes over time and infer generalizable semantics from their movement. A natural way to avoid parameter explosion when learning visual patterns over time is to make use of recurrence across the time-axis. In this article, we empirically study the cross-domain robustness for recurrent, attention-based and convolutional video models, respectively, to investigate whether this robustness is influenced by the frame dependency modeling. Our novel Temporal Shape dataset is proposed as a light-weight dataset to assess the ability to generalize across temporal shapes which are not revealed from single frames. We find that when controlling for performance and layer structure, recurrent models show better out-of-domain generalization ability on the Temporal Shape dataset than convolution- and attention-based models. Moreover, our experiments indicate that convolution- and attention-based models exhibit more texture bias on Diving48 than recurrent models.
The World as a Graph: Improving El Niño Forecasts with Graph Neural Networks
Apr 11, 2021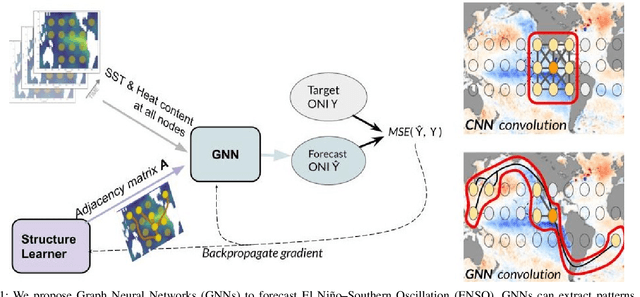
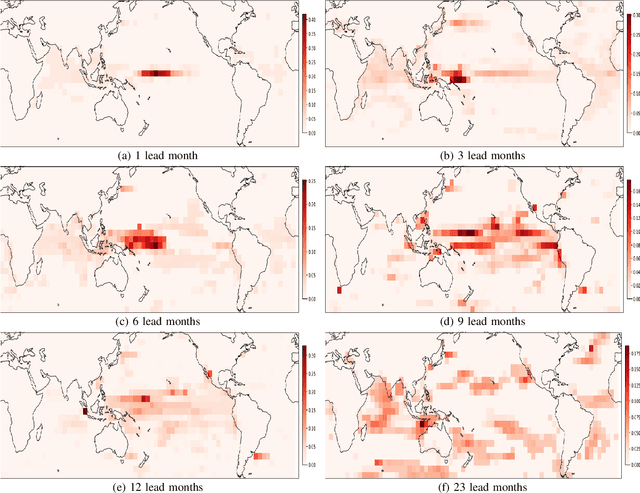
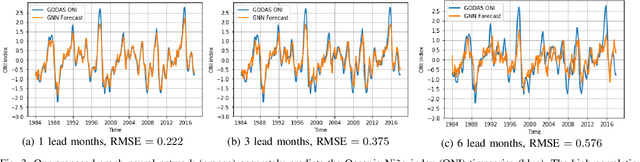
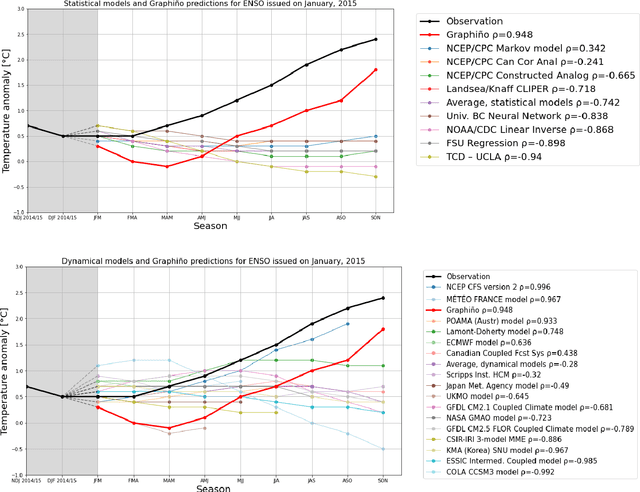
Deep learning-based models have recently outperformed state-of-the-art seasonal forecasting models, such as for predicting El Ni\~no-Southern Oscillation (ENSO). However, current deep learning models are based on convolutional neural networks which are difficult to interpret and can fail to model large-scale atmospheric patterns. In comparison, graph neural networks (GNNs) are capable of modeling large-scale spatial dependencies and are more interpretable due to the explicit modeling of information flow through edge connections. We propose the first application of graph neural networks to seasonal forecasting. We design a novel graph connectivity learning module that enables our GNN model to learn large-scale spatial interactions jointly with the actual ENSO forecasting task. Our model, \graphino, outperforms state-of-the-art deep learning-based models for forecasts up to six months ahead. Additionally, we show that our model is more interpretable as it learns sensible connectivity structures that correlate with the ENSO anomaly pattern.
Graph Neural Networks for Improved El Niño Forecasting
Dec 10, 2020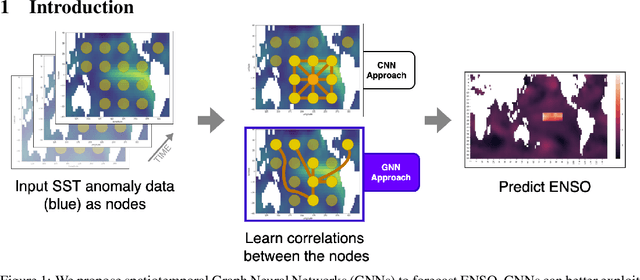

Deep learning-based models have recently outperformed state-of-the-art seasonal forecasting models, such as for predicting El Ni\~no-Southern Oscillation (ENSO). However, current deep learning models are based on convolutional neural networks which are difficult to interpret and can fail to model large-scale atmospheric patterns called teleconnections. Hence, we propose the application of spatiotemporal Graph Neural Networks (GNN) to forecast ENSO at long lead times, finer granularity and improved predictive skill than current state-of-the-art methods. The explicit modeling of information flow via edges may also allow for more interpretable forecasts. Preliminary results are promising and outperform state-of-the art systems for projections 1 and 3 months ahead.