 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDessie: Disentanglement for Articulated 3D Horse Shape and Pose Estimation from Images
Oct 04, 2024In recent years, 3D parametric animal models have been developed to aid in estimating 3D shape and pose from images and video. While progress has been made for humans, it's more challenging for animals due to limited annotated data. To address this, we introduce the first method using synthetic data generation and disentanglement to learn to regress 3D shape and pose. Focusing on horses, we use text-based texture generation and a synthetic data pipeline to create varied shapes, poses, and appearances, learning disentangled spaces. Our method, Dessie, surpasses existing 3D horse reconstruction methods and generalizes to other large animals like zebras, cows, and deer. See the project website at: \url{https://celiali.github.io/Dessie/}.
CLHOP: Combined Audio-Video Learning for Horse 3D Pose and Shape Estimation
Jul 01, 2024



In the monocular setting, predicting 3D pose and shape of animals typically relies solely on visual information, which is highly under-constrained. In this work, we explore using audio to enhance 3D shape and motion recovery of horses from monocular video. We test our approach on two datasets: an indoor treadmill dataset for 3D evaluation and an outdoor dataset capturing diverse horse movements, the latter being a contribution to this study. Our results show that incorporating sound with visual data leads to more accurate and robust motion regression. This study is the first to investigate audio's role in 3D animal motion recovery.
Equine Pain Behavior Classification via Self-Supervised Disentangled Pose Representation
Aug 30, 2021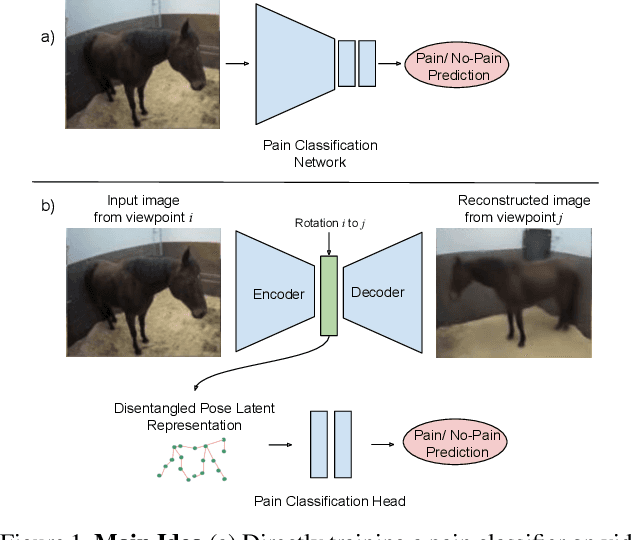
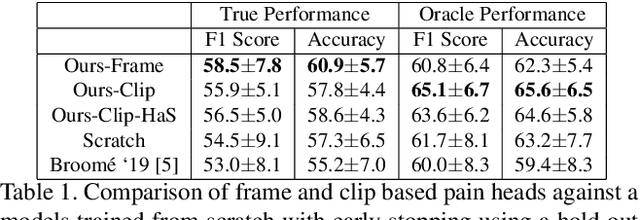
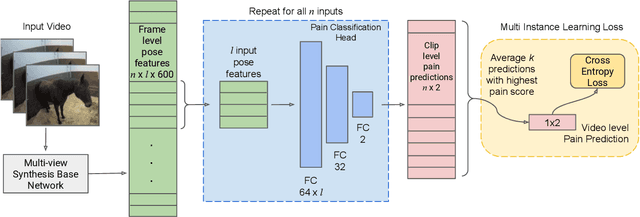

Timely detection of horse pain is important for equine welfare. Horses express pain through their facial and body behavior, but may hide signs of pain from unfamiliar human observers. In addition, collecting visual data with detailed annotation of horse behavior and pain state is both cumbersome and not scalable. Consequently, a pragmatic equine pain classification system would use video of the unobserved horse and weak labels. This paper proposes such a method for equine pain classification by using multi-view surveillance video footage of unobserved horses with induced orthopaedic pain, with temporally sparse video level pain labels. To ensure that pain is learned from horse body language alone, we first train a self-supervised generative model to disentangle horse pose from its appearance and background before using the disentangled horse pose latent representation for pain classification. To make best use of the pain labels, we develop a novel loss that formulates pain classification as a multi-instance learning problem. Our method achieves pain classification accuracy better than human expert performance with 60% accuracy. The learned latent horse pose representation is shown to be viewpoint covariant, and disentangled from horse appearance. Qualitative analysis of pain classified segments shows correspondence between the pain symptoms identified by our model, and equine pain scales used in veterinary practice.
hSMAL: Detailed Horse Shape and Pose Reconstruction for Motion Pattern Recognition
Jun 18, 2021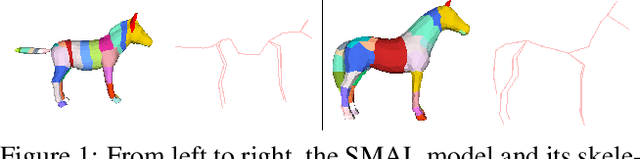
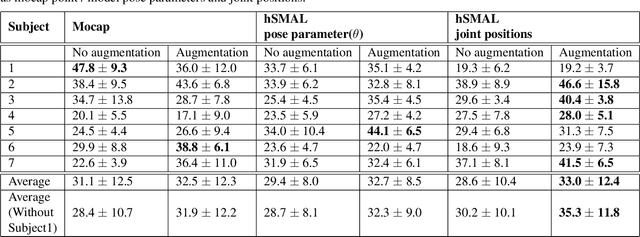
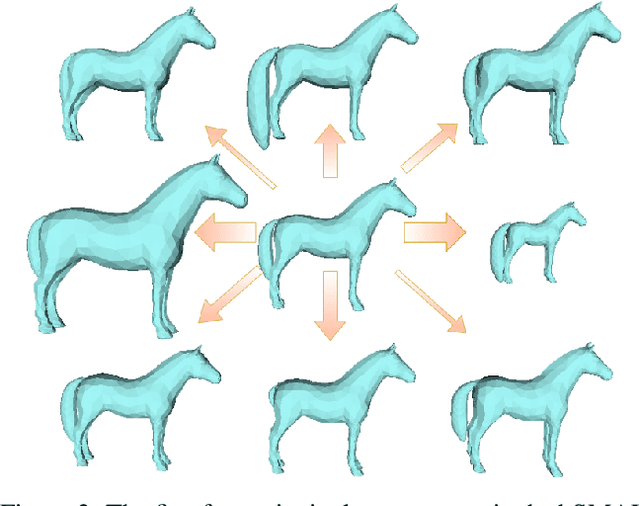
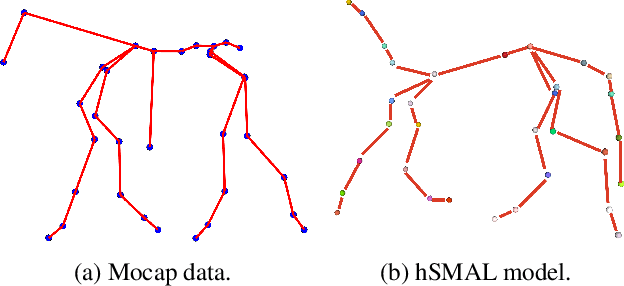
In this paper we present our preliminary work on model-based behavioral analysis of horse motion. Our approach is based on the SMAL model, a 3D articulated statistical model of animal shape. We define a novel SMAL model for horses based on a new template, skeleton and shape space learned from $37$ horse toys. We test the accuracy of our hSMAL model in reconstructing a horse from 3D mocap data and images. We apply the hSMAL model to the problem of lameness detection from video, where we fit the model to images to recover 3D pose and train an ST-GCN network on pose data. A comparison with the same network trained on mocap points illustrates the benefit of our approach.