 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasping a Handful: Sequential Multi-Object Dexterous Grasp Generation
Mar 31, 2025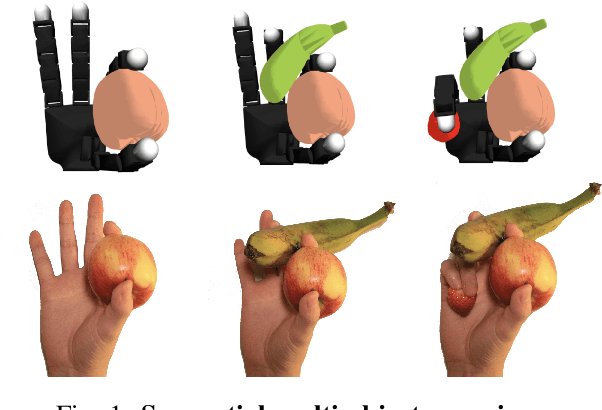

We introduce the sequential multi-object robotic grasp sampling algorithm SeqGrasp that can robustly synthesize stable grasps on diverse objects using the robotic hand's partial Degrees of Freedom (DoF). We use SeqGrasp to construct the large-scale Allegro Hand sequential grasping dataset SeqDataset and use it for training the diffusion-based sequential grasp generator SeqDiffuser. We experimentally evaluate SeqGrasp and SeqDiffuser against the state-of-the-art non-sequential multi-object grasp generation method MultiGrasp in simulation and on a real robot. The experimental results demonstrate that SeqGrasp and SeqDiffuser reach an 8.71%-43.33% higher grasp success rate than MultiGrasp. Furthermore, SeqDiffuser is approximately 1000 times faster at generating grasps than SeqGrasp and MultiGrasp.
Dessie: Disentanglement for Articulated 3D Horse Shape and Pose Estimation from Images
Oct 04, 2024In recent years, 3D parametric animal models have been developed to aid in estimating 3D shape and pose from images and video. While progress has been made for humans, it's more challenging for animals due to limited annotated data. To address this, we introduce the first method using synthetic data generation and disentanglement to learn to regress 3D shape and pose. Focusing on horses, we use text-based texture generation and a synthetic data pipeline to create varied shapes, poses, and appearances, learning disentangled spaces. Our method, Dessie, surpasses existing 3D horse reconstruction methods and generalizes to other large animals like zebras, cows, and deer. See the project website at: \url{https://celiali.github.io/Dessie/}.
Interactive Perception for Deformable Object Manipulation
Mar 08, 2024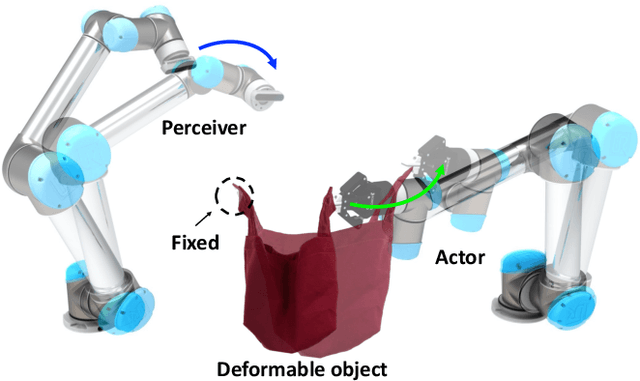
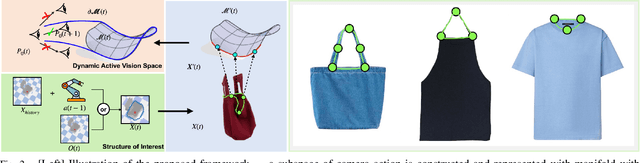
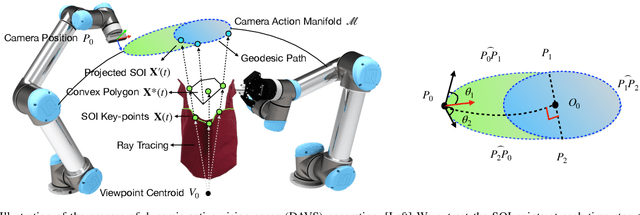
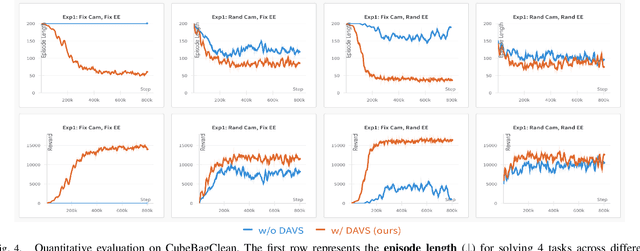
Interactive perception enables robots to manipulate the environment and objects to bring them into states that benefit the perception process. Deformable objects pose challenges to this due to significant manipulation difficulty and occlusion in vision-based perception. In this work, we address such a problem with a setup involving both an active camera and an object manipulator. Our approach is based on a sequential decision-making framework and explicitly considers the motion regularity and structure in coupling the camera and manipulator. We contribute a method for constructing and computing a subspace, called Dynamic Active Vision Space (DAVS), for effectively utilizing the regularity in motion exploration. The effectiveness of the framework and approach are validated in both a simulation and a real dual-arm robot setup. Our results confirm the necessity of an active camera and coordinative motion in interactive perception for deformable objects.
DexDiffuser: Generating Dexterous Grasps with Diffusion Models
Feb 05, 2024



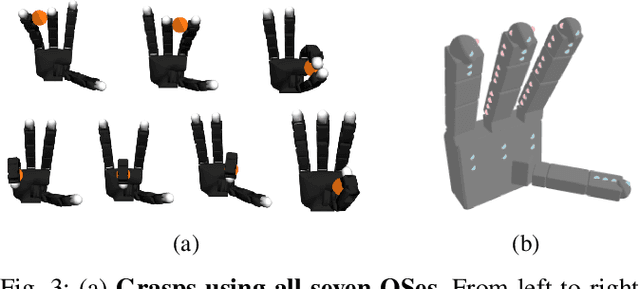
We introduce DexDiffuser, a novel dexterous grasping method that generates, evaluates, and refines grasps on partial object point clouds. DexDiffuser includes the conditional diffusion-based grasp sampler DexSampler and the dexterous grasp evaluator DexEvaluator. DexSampler generates high-quality grasps conditioned on object point clouds by iterative denoising of randomly sampled grasps. We also introduce two grasp refinement strategies: Evaluator-Guided Diffusion (EGD) and Evaluator-based Sampling Refinement (ESR). Our simulation and real-world experiments on the Allegro Hand consistently demonstrate that DexDiffuser outperforms the state-of-the-art multi-finger grasp generation method FFHNet with an, on average, 21.71--22.20\% higher grasp success rate.
CAPGrasp: An $\mathbb{R}^3\times \text{SO-equivariant}$ Continuous Approach-Constrained Generative Grasp Sampler
Oct 18, 2023
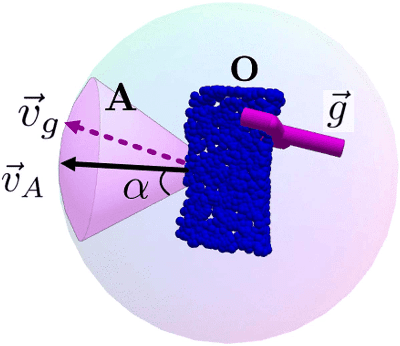
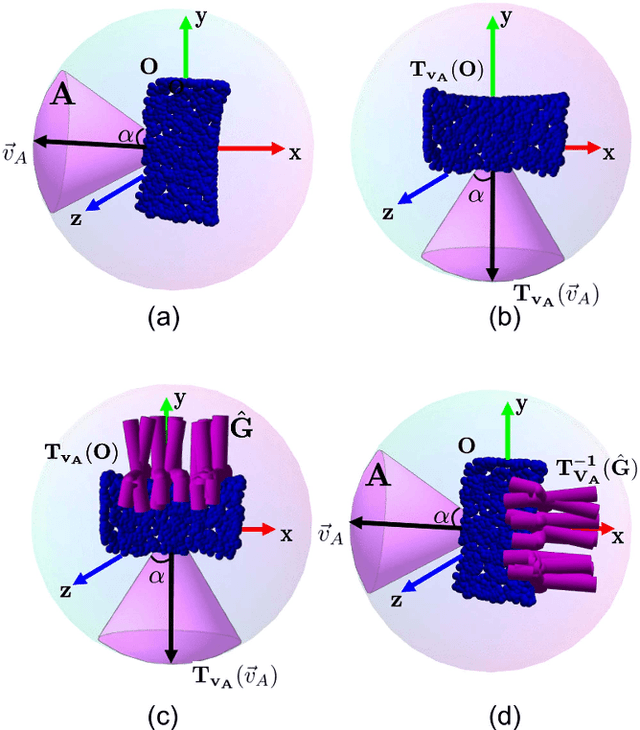
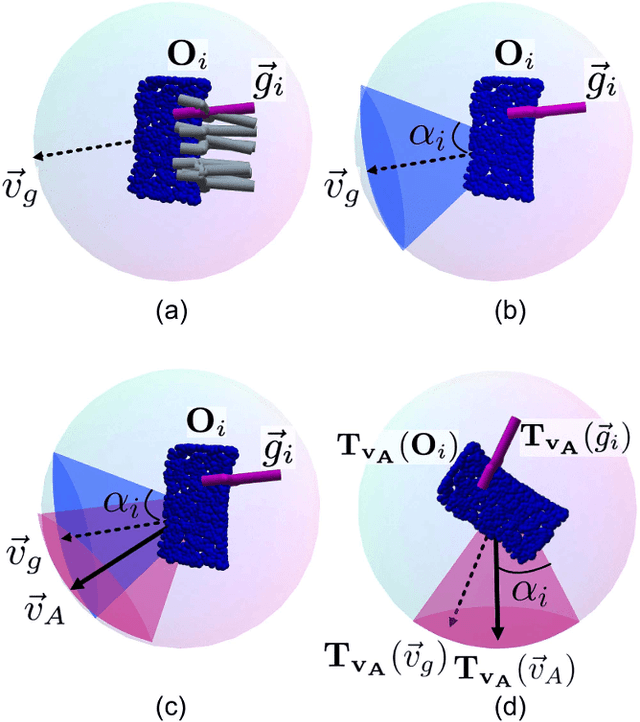
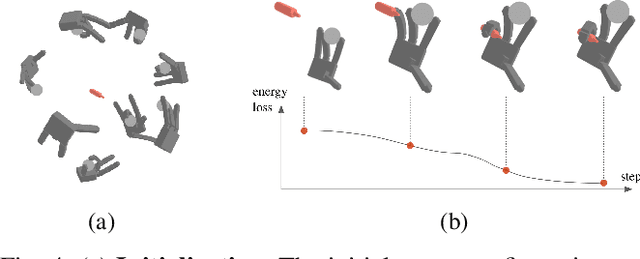
We propose CAPGrasp, an $\mathbb{R}^3\times \text{SO(2)-equivariant}$ 6-DoF continuous approach-constrained generative grasp sampler. It includes a novel learning strategy for training CAPGrasp that eliminates the need to curate massive conditionally labeled datasets and a constrained grasp refinement technique that improves grasp poses while respecting the grasp approach directional constraints. The experimental results demonstrate that CAPGrasp is more than three times as sample efficient as unconstrained grasp samplers while achieving up to 38% grasp success rate improvement. CAPGrasp also achieves 4-10% higher grasp success rates than constrained but noncontinuous grasp samplers. Overall, CAPGrasp is a sample-efficient solution when grasps must originate from specific directions, such as grasping in confined spaces.
GoNet: An Approach-Constrained Generative Grasp Sampling Network
Mar 14, 2023Constraining the approach direction of grasps is important when picking objects in confined spaces, such as when emptying a shelf. Yet, such capabilities are not available in state-of-the-art data-driven grasp sampling methods that sample grasps all around the object. In this work, we address the specific problem of training approach-constrained data-driven grasp samplers and how to generate good grasping directions automatically. Our solution is GoNet: a generative grasp sampler that can constrain the grasp approach direction to lie close to a specified direction. This is achieved by discretizing SO(3) into bins and training GoNet to generate grasps from those bins. At run-time, the bin aligning with the second largest principal component of the observed point cloud is selected. GoNet is benchmarked against GraspNet, a state-of-the-art unconstrained grasp sampler, in an unconfined grasping experiment in simulation and on an unconfined and confined grasping experiment in the real world. The results demonstrate that GoNet achieves higher success-over-coverage in simulation and a 12%-18% higher success rate in real-world table-picking and shelf-picking tasks than the baseline.
Graph-based Task-specific Prediction Models for Interactions between Deformable and Rigid Objects
Mar 04, 2021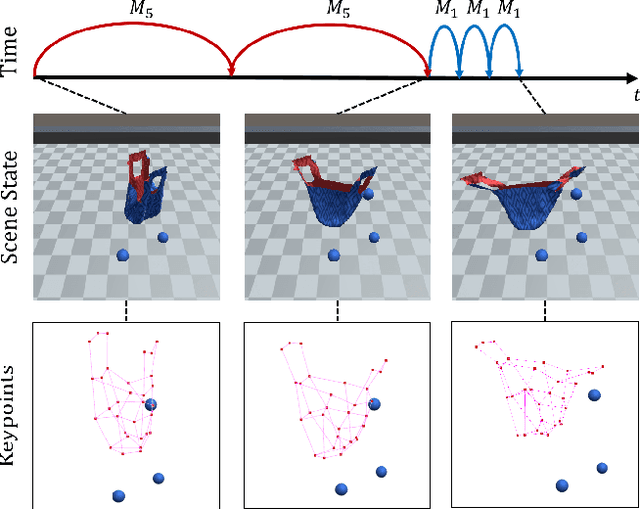
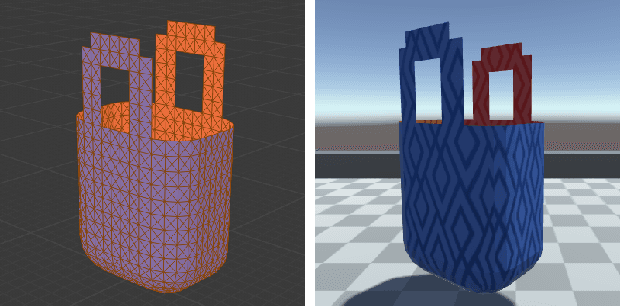
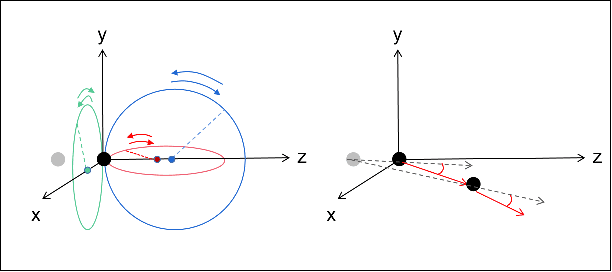

Capturing scene dynamics and predicting the future scene state is challenging but essential for robotic manipulation tasks, especially when the scene contains both rigid and deformable objects. In this work, we contribute a simulation environment and generate a novel dataset for task-specific manipulation, involving interactions between rigid objects and a deformable bag. The dataset incorporates a rich variety of scenarios including different object sizes, object numbers and manipulation actions. We approach dynamics learning by proposing an object-centric graph representation and two modules which are Active Prediction Module (APM) and Position Prediction Module (PPM) based on graph neural networks with an encode-process-decode architecture. At the inference stage, we build a two-stage model based on the learned modules for single time step prediction. We combine modules with different prediction horizons into a mixed-horizon model which addresses long-term prediction. In an ablation study, we show the benefits of the two-stage model for single time step prediction and the effectiveness of the mixed-horizon model for long-term prediction tasks. Supplementary material is available at https://github.com/wengzehang/deformable_rigid_interaction_prediction