 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDex: A Diffusion Policy for Sequential Multi-Object Dexterous Grasping
Jun 03, 2026This work addresses sequentially grasping multiple objects with a single dexterous hand without releasing those already held. Most dexterous grasping methods commit all of the hand's degrees of freedom to a single object, underutilizing its dexterity and leaving no redundancy for subsequent grasps. The proposed solution, MoDex, is a diffusion policy that predicts the next gripper pose directly from observations, conditioned on an opposition space and point cloud. The opposition space condition specifies which fingers participate in the current grasp, enabling the gripper to use only a subset of its available degrees of freedom while reserving the remaining degrees of freedom for subsequent grasps. To facilitate sim-to-real transfer, MoDex is trained in two stages: first through imitation learning on expert demonstrations, and subsequently through reinforcement learning fine-tuning, which consistently improves success rates over the pre-trained policy. We evaluate MoDex in simulation on a MuJoCo-based Franka Emika Panda robot equipped with an Allegro Hand and on the corresponding real-world hardware platform. Across both simulation and real-world experiments, MoDex achieves higher success rates than the evaluated learning-based baselines, improving performance by 2.92-17.92% and 6.67-17.78%, respectively. Project page: https://modex2026.github.io/.
Grasp as You Dream: Imitating Functional Grasping from Generated Human Demonstrations
Apr 08, 2026Building generalist robots capable of performing functional grasping in everyday, open-world environments remains a significant challenge due to the vast diversity of objects and tasks. Existing methods are either constrained to narrow object/task sets or rely on prohibitively large-scale data collection to capture real-world variability. In this work, we present an alternative approach, GraspDreamer, a method that leverages human demonstrations synthesized by visual generative models (VGMs) (e.g., video generation models) to enable zero-shot functional grasping without labor-intensive data collection. The key idea is that VGMs pre-trained on internet-scale human data implicitly encode generalized priors about how humans interact with the physical world, which can be combined with embodiment-specific action optimization to enable functional grasping with minimal effort. Extensive experiments on the public benchmarks with different robot hands demonstrate the superior data efficiency and generalization performance of GraspDreamer compared to previous methods. Real-world evaluations further validate the effectiveness on real robots. Additionally, we showcase that GraspDreamer can (1) be naturally extended to downstream manipulation tasks, and (2) can generate data to support visuomotor policy learning.
Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data
Mar 13, 2026Human athletes demonstrate versatile and highly-dynamic tennis skills to successfully conduct competitive rallies with a high-speed tennis ball. However, reproducing such behaviors on humanoid robots is difficult, partially due to the lack of perfect humanoid action data or human kinematic motion data in tennis scenarios as reference. In this work, we propose LATENT, a system that Learns Athletic humanoid TEnnis skills from imperfect human motioN daTa. The imperfect human motion data consist only of motion fragments that capture the primitive skills used when playing tennis rather than precise and complete human-tennis motion sequences from real-world tennis matches, thereby significantly reducing the difficulty of data collection. Our key insight is that, despite being imperfect, such quasi-realistic data still provide priors about human primitive skills in tennis scenarios. With further correction and composition, we learn a humanoid policy that can consistently strike incoming balls under a wide range of conditions and return them to target locations, while preserving natural motion styles. We also propose a series of designs for robust sim-to-real transfer and deploy our policy on the Unitree G1 humanoid robot. Our method achieves surprising results in the real world and can stably sustain multi-shot rallies with human players. Project page: https://zzk273.github.io/LATENT/
The First WARA Robotics Mobile Manipulation Challenge -- Lessons Learned
May 11, 2025The first WARA Robotics Mobile Manipulation Challenge, held in December 2024 at ABB Corporate Research in V\"aster{\aa}s, Sweden, addressed the automation of task-intensive and repetitive manual labor in laboratory environments - specifically the transport and cleaning of glassware. Designed in collaboration with AstraZeneca, the challenge invited academic teams to develop autonomous robotic systems capable of navigating human-populated lab spaces and performing complex manipulation tasks, such as loading items into industrial dishwashers. This paper presents an overview of the challenge setup, its industrial motivation, and the four distinct approaches proposed by the participating teams. We summarize lessons learned from this edition and propose improvements in design to enable a more effective second iteration to take place in 2025. The initiative bridges an important gap in effective academia-industry collaboration within the domain of autonomous mobile manipulation systems by promoting the development and deployment of applied robotic solutions in real-world laboratory contexts.
Grasping a Handful: Sequential Multi-Object Dexterous Grasp Generation
Mar 31, 2025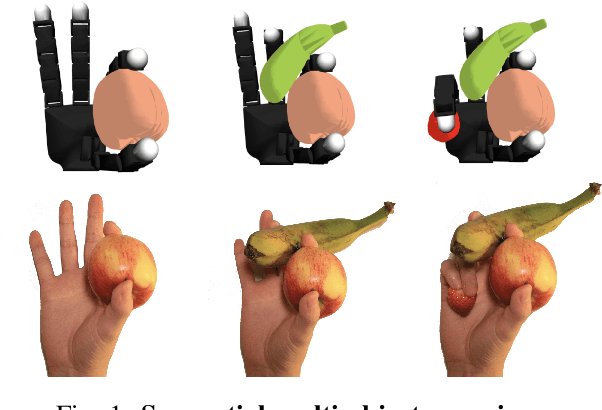

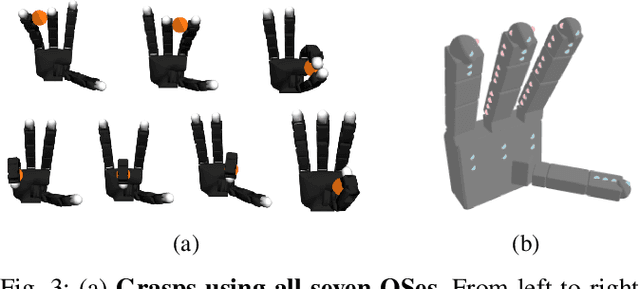
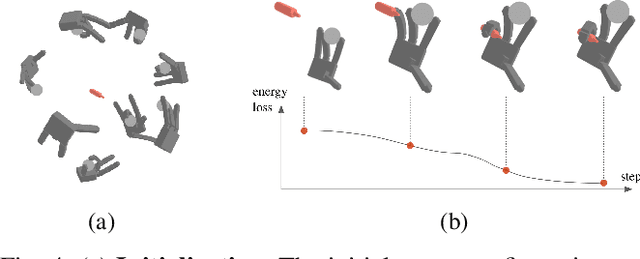
We introduce the sequential multi-object robotic grasp sampling algorithm SeqGrasp that can robustly synthesize stable grasps on diverse objects using the robotic hand's partial Degrees of Freedom (DoF). We use SeqGrasp to construct the large-scale Allegro Hand sequential grasping dataset SeqDataset and use it for training the diffusion-based sequential grasp generator SeqDiffuser. We experimentally evaluate SeqGrasp and SeqDiffuser against the state-of-the-art non-sequential multi-object grasp generation method MultiGrasp in simulation and on a real robot. The experimental results demonstrate that SeqGrasp and SeqDiffuser reach an 8.71%-43.33% higher grasp success rate than MultiGrasp. Furthermore, SeqDiffuser is approximately 1000 times faster at generating grasps than SeqGrasp and MultiGrasp.
Habitizing Diffusion Planning for Efficient and Effective Decision Making
Feb 10, 2025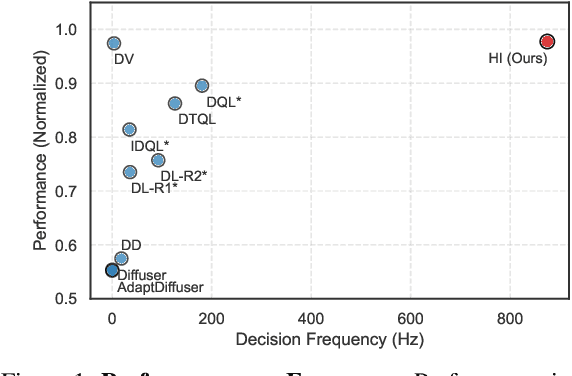
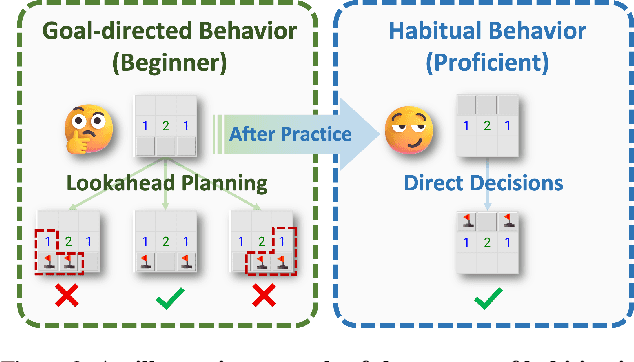
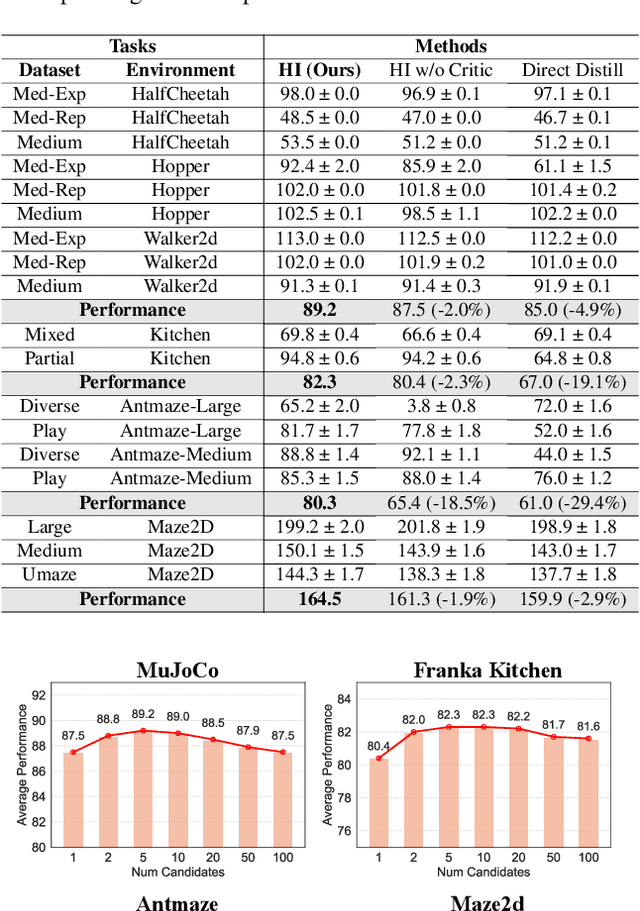
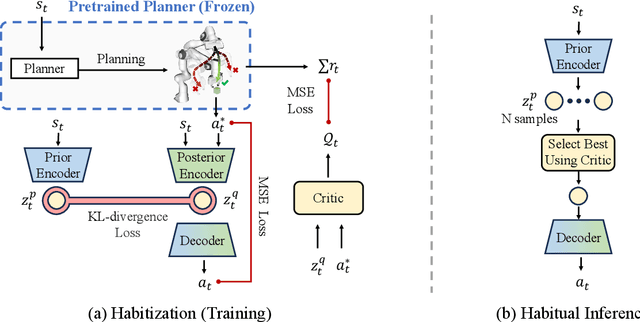
Diffusion models have shown great promise in decision-making, also known as diffusion planning. However, the slow inference speeds limit their potential for broader real-world applications. Here, we introduce Habi, a general framework that transforms powerful but slow diffusion planning models into fast decision-making models, which mimics the cognitive process in the brain that costly goal-directed behavior gradually transitions to efficient habitual behavior with repetitive practice. Even using a laptop CPU, the habitized model can achieve an average 800+ Hz decision-making frequency (faster than previous diffusion planners by orders of magnitude) on standard offline reinforcement learning benchmarks D4RL, while maintaining comparable or even higher performance compared to its corresponding diffusion planner. Our work proposes a fresh perspective of leveraging powerful diffusion models for real-world decision-making tasks. We also provide robust evaluations and analysis, offering insights from both biological and engineering perspectives for efficient and effective decision-making.
DexDiffuser: Generating Dexterous Grasps with Diffusion Models
Feb 05, 2024



We introduce DexDiffuser, a novel dexterous grasping method that generates, evaluates, and refines grasps on partial object point clouds. DexDiffuser includes the conditional diffusion-based grasp sampler DexSampler and the dexterous grasp evaluator DexEvaluator. DexSampler generates high-quality grasps conditioned on object point clouds by iterative denoising of randomly sampled grasps. We also introduce two grasp refinement strategies: Evaluator-Guided Diffusion (EGD) and Evaluator-based Sampling Refinement (ESR). Our simulation and real-world experiments on the Allegro Hand consistently demonstrate that DexDiffuser outperforms the state-of-the-art multi-finger grasp generation method FFHNet with an, on average, 21.71--22.20\% higher grasp success rate.
CAPGrasp: An $\mathbb{R}^3\times \text{SO-equivariant}$ Continuous Approach-Constrained Generative Grasp Sampler
Oct 18, 2023
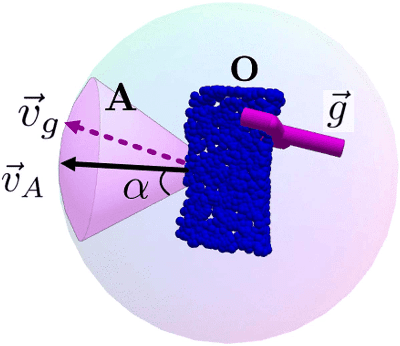
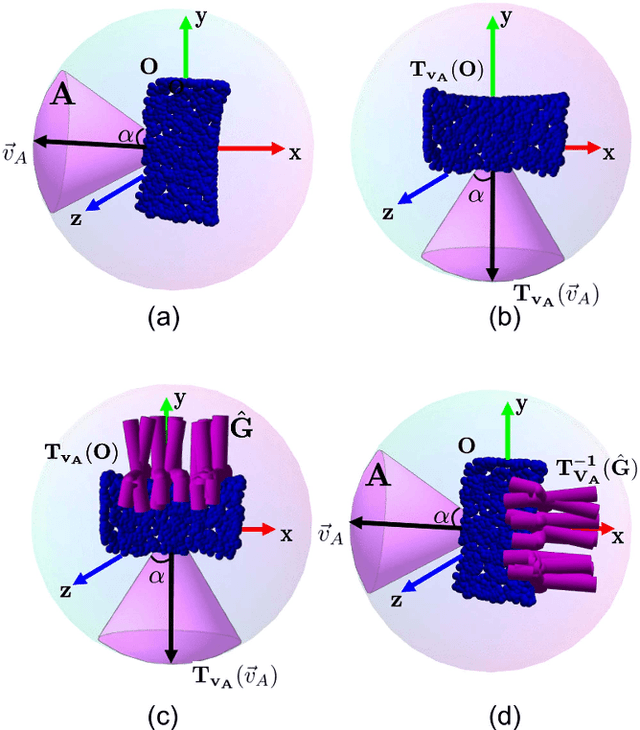
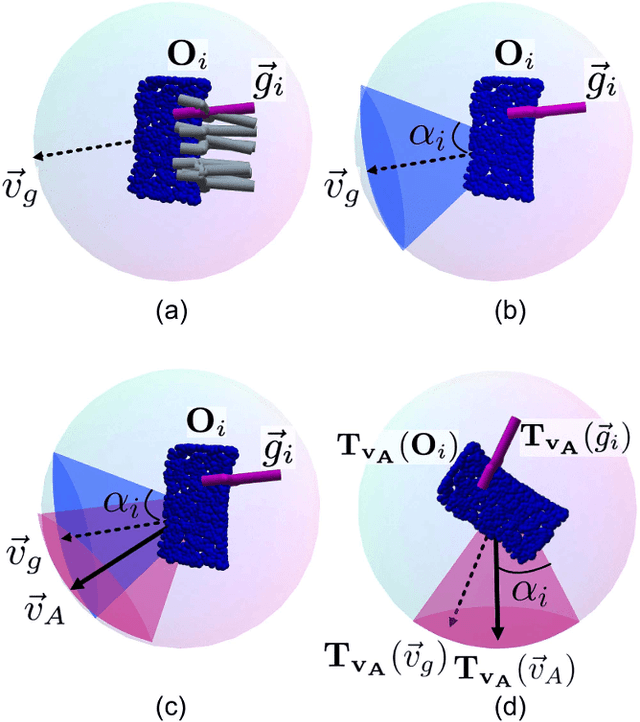
We propose CAPGrasp, an $\mathbb{R}^3\times \text{SO(2)-equivariant}$ 6-DoF continuous approach-constrained generative grasp sampler. It includes a novel learning strategy for training CAPGrasp that eliminates the need to curate massive conditionally labeled datasets and a constrained grasp refinement technique that improves grasp poses while respecting the grasp approach directional constraints. The experimental results demonstrate that CAPGrasp is more than three times as sample efficient as unconstrained grasp samplers while achieving up to 38% grasp success rate improvement. CAPGrasp also achieves 4-10% higher grasp success rates than constrained but noncontinuous grasp samplers. Overall, CAPGrasp is a sample-efficient solution when grasps must originate from specific directions, such as grasping in confined spaces.
Enabling Robot Manipulation of Soft and Rigid Objects with Vision-based Tactile Sensors
Jun 09, 2023
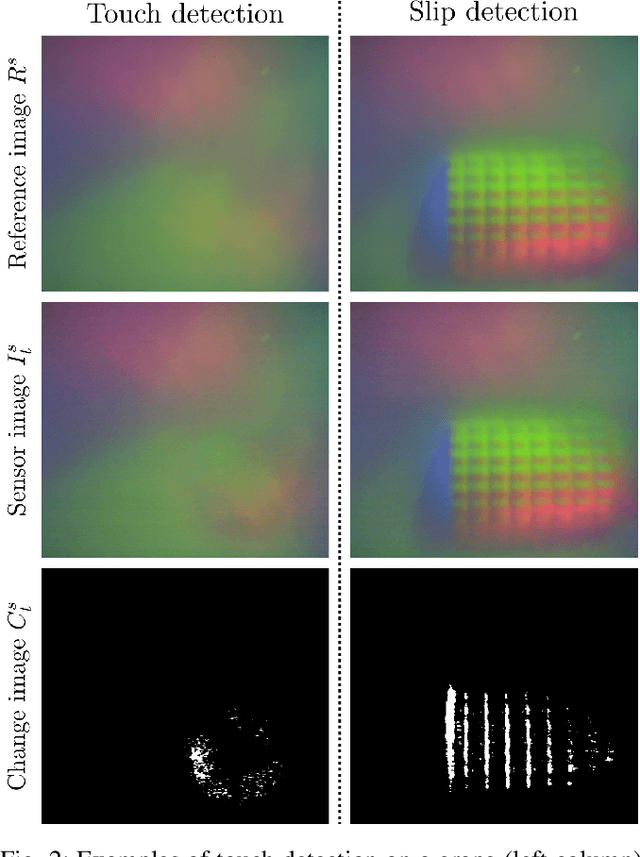
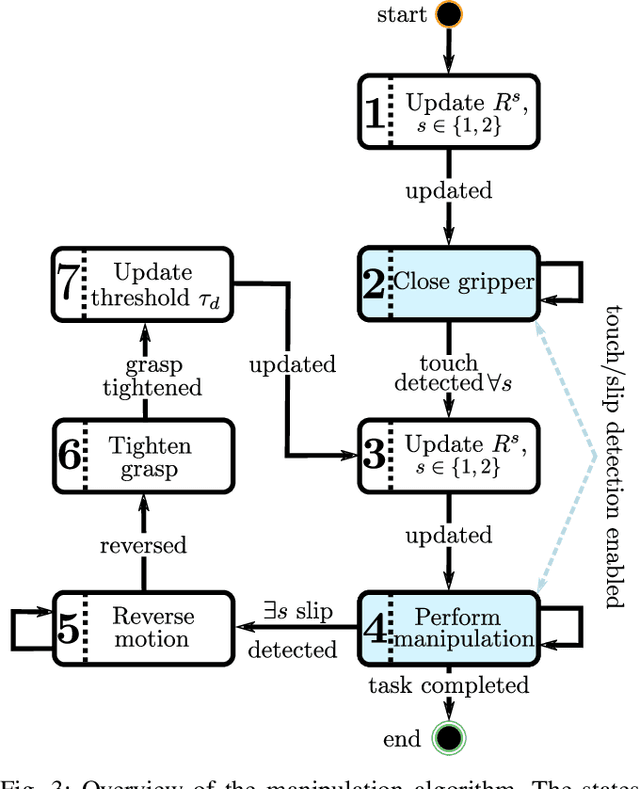

Endowing robots with tactile capabilities opens up new possibilities for their interaction with the environment, including the ability to handle fragile and/or soft objects. In this work, we equip the robot gripper with low-cost vision-based tactile sensors and propose a manipulation algorithm that adapts to both rigid and soft objects without requiring any knowledge of their properties. The algorithm relies on a touch and slip detection method, which considers the variation in the tactile images with respect to reference ones. We validate the approach on seven different objects, with different properties in terms of rigidity and fragility, to perform unplugging and lifting tasks. Furthermore, to enhance applicability, we combine the manipulation algorithm with a grasp sampler for the task of finding and picking a grape from a bunch without damaging~it.
GoNet: An Approach-Constrained Generative Grasp Sampling Network
Mar 14, 2023Constraining the approach direction of grasps is important when picking objects in confined spaces, such as when emptying a shelf. Yet, such capabilities are not available in state-of-the-art data-driven grasp sampling methods that sample grasps all around the object. In this work, we address the specific problem of training approach-constrained data-driven grasp samplers and how to generate good grasping directions automatically. Our solution is GoNet: a generative grasp sampler that can constrain the grasp approach direction to lie close to a specified direction. This is achieved by discretizing SO(3) into bins and training GoNet to generate grasps from those bins. At run-time, the bin aligning with the second largest principal component of the observed point cloud is selected. GoNet is benchmarked against GraspNet, a state-of-the-art unconstrained grasp sampler, in an unconfined grasping experiment in simulation and on an unconfined and confined grasping experiment in the real world. The results demonstrate that GoNet achieves higher success-over-coverage in simulation and a 12%-18% higher success rate in real-world table-picking and shelf-picking tasks than the baseline.