 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Action Planning with Multiple Heterogeneous Agents
Mar 25, 2024Visual planning methods are promising to handle complex settings where extracting the system state is challenging. However, none of the existing works tackles the case of multiple heterogeneous agents which are characterized by different capabilities and/or embodiment. In this work, we propose a method to realize visual action planning in multi-agent settings by exploiting a roadmap built in a low-dimensional structured latent space and used for planning. To enable multi-agent settings, we infer possible parallel actions from a dataset composed of tuples associated with individual actions. Next, we evaluate feasibility and cost of them based on the capabilities of the multi-agent system and endow the roadmap with this information, building a capability latent space roadmap (C-LSR). Additionally, a capability suggestion strategy is designed to inform the human operator about possible missing capabilities when no paths are found. The approach is validated in a simulated burger cooking task and a real-world box packing task.
Low-Cost Teleoperation with Haptic Feedback through Vision-based Tactile Sensors for Rigid and Soft Object Manipulation
Mar 25, 2024



Haptic feedback is essential for humans to successfully perform complex and delicate manipulation tasks. A recent rise in tactile sensors has enabled robots to leverage the sense of touch and expand their capability drastically. However, many tasks still need human intervention/guidance. For this reason, we present a teleoperation framework designed to provide haptic feedback to human operators based on the data from camera-based tactile sensors mounted on the robot gripper. Partial autonomy is introduced to prevent slippage of grasped objects during task execution. Notably, we rely exclusively on low-cost off-the-shelf hardware to realize an affordable solution. We demonstrate the versatility of the framework on nine different objects ranging from rigid to soft and fragile ones, using three different operators on real hardware.
Enabling Robot Manipulation of Soft and Rigid Objects with Vision-based Tactile Sensors
Jun 09, 2023
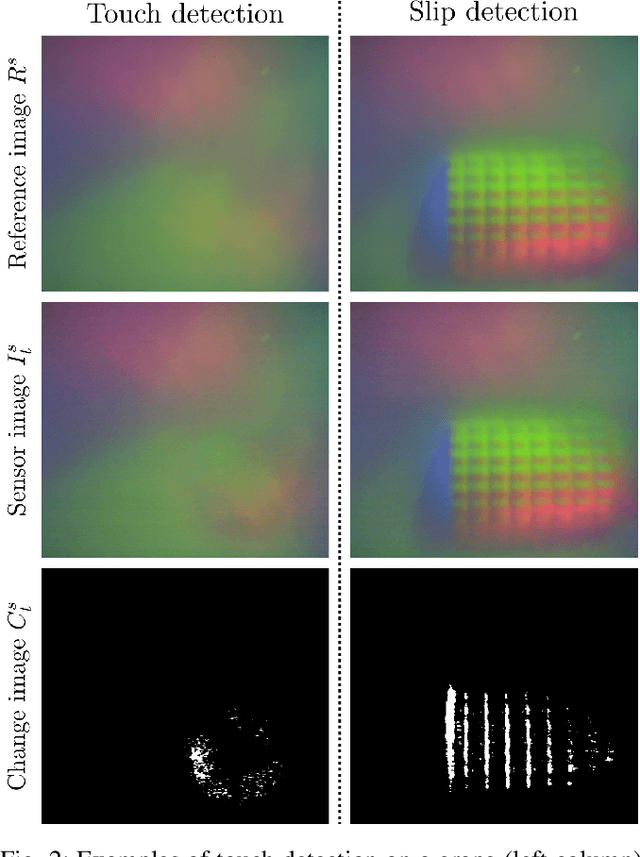
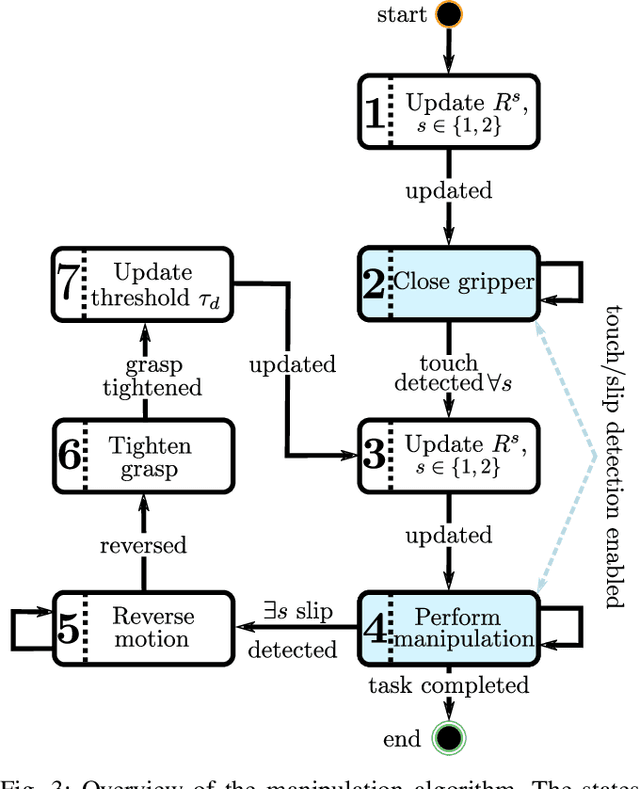

Endowing robots with tactile capabilities opens up new possibilities for their interaction with the environment, including the ability to handle fragile and/or soft objects. In this work, we equip the robot gripper with low-cost vision-based tactile sensors and propose a manipulation algorithm that adapts to both rigid and soft objects without requiring any knowledge of their properties. The algorithm relies on a touch and slip detection method, which considers the variation in the tactile images with respect to reference ones. We validate the approach on seven different objects, with different properties in terms of rigidity and fragility, to perform unplugging and lifting tasks. Furthermore, to enhance applicability, we combine the manipulation algorithm with a grasp sampler for the task of finding and picking a grape from a bunch without damaging~it.
Ensemble Latent Space Roadmap for Improved Robustness in Visual Action Planning
Mar 27, 2023



Planning in learned latent spaces helps to decrease the dimensionality of raw observations. In this work, we propose to leverage the ensemble paradigm to enhance the robustness of latent planning systems. We rely on our Latent Space Roadmap (LSR) framework, which builds a graph in a learned structured latent space to perform planning. Given multiple LSR framework instances, that differ either on their latent spaces or on the parameters for constructing the graph, we use the action information as well as the embedded nodes of the produced plans to define similarity measures. These are then utilized to select the most promising plans. We validate the performance of our Ensemble LSR (ENS-LSR) on simulated box stacking and grape harvesting tasks as well as on a real-world robotic T-shirt folding experiment.
A Task Allocation Framework for Human Multi-Robot Collaborative Settings
Oct 25, 2022The requirements of modern production systems together with more advanced robotic technologies have fostered the integration of teams comprising humans and autonomous robots. However, along with the potential benefits also comes the question of how to effectively handle these teams considering the different characteristics of the involved agents. For this reason, this paper presents a framework for task allocation in a human multi-robot collaborative scenario. The proposed solution combines an optimal offline allocation with an online reallocation strategy which accounts for inaccuracies of the offline plan and/or unforeseen events, human subjective preferences and cost of switching from one task to another so as to increase human satisfaction and team efficiency. Experiments are presented for the case of two manipulators cooperating with a human operator for performing a box filling task.
Augment-Connect-Explore: a Paradigm for Visual Action Planning with Data Scarcity
Mar 24, 2022
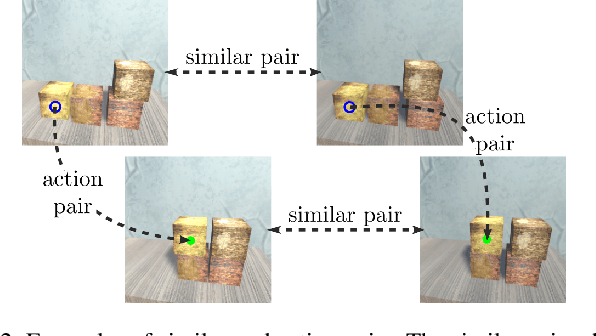


Visual action planning particularly excels in applications where the state of the system cannot be computed explicitly, such as manipulation of deformable objects, as it enables planning directly from raw images. Even though the field has been significantly accelerated by deep learning techniques, a crucial requirement for their success is the availability of a large amount of data. In this work, we propose the Augment-Connect-Explore (ACE) paradigm to enable visual action planning in cases of data scarcity. We build upon the Latent Space Roadmap (LSR) framework which performs planning with a graph built in a low dimensional latent space. In particular, ACE is used to i) Augment the available training dataset by autonomously creating new pairs of datapoints, ii) create new unobserved Connections among representations of states in the latent graph, and iii) Explore new regions of the latent space in a targeted manner. We validate the proposed approach on both simulated box stacking and real-world folding task showing the applicability for rigid and deformable object manipulation tasks, respectively.
Comparing Reconstruction- and Contrastive-based Models for Visual Task Planning
Sep 14, 2021



Learning state representations enables robotic planning directly from raw observations such as images. Most methods learn state representations by utilizing losses based on the reconstruction of the raw observations from a lower-dimensional latent space. The similarity between observations in the space of images is often assumed and used as a proxy for estimating similarity between the underlying states of the system. However, observations commonly contain task-irrelevant factors of variation which are nonetheless important for reconstruction, such as varying lighting and different camera viewpoints. In this work, we define relevant evaluation metrics and perform a thorough study of different loss functions for state representation learning. We show that models exploiting task priors, such as Siamese networks with a simple contrastive loss, outperform reconstruction-based representations in visual task planning.
Safety in human-multi robot collaborative scenarios: a trajectory scaling approach
Jul 16, 2021



In this paper, a strategy to handle the human safety in a multi-robot scenario is devised. In the presented framework, it is foreseen that robots are in charge of performing any cooperative manipulation task which is parameterized by a proper task function. The devised architecture answers to the increasing demand of strict cooperation between humans and robots, since it equips a general multi-robot cell with the feature of making robots and human working together. The human safety is properly handled by defining a safety index which depends both on the relative position and velocity of the human operator and robots. Then, the multi-robot task trajectory is properly scaled in order to ensure that the human safety never falls below a given threshold which can be set in worst conditions according to a minimum allowed distance. Simulations results are presented in order to prove the effectiveness of the approach.
* Link to the paper: https://www.sciencedirect.com/science/article/pii/S2405896318332464
A Data-Driven Approach for Contact Detection, Classification and Reaction in Physical Human-Robot Collaboration
Jun 12, 2021



This paper considers a scenario where a robot and a human operator share the same workspace, and the robot is able to both carry out autonomous tasks and physically interact with the human in order to achieve common goals. In this context, both intentional and accidental contacts between human and robot might occur due to the complexity of tasks and environment, to the uncertainty of human behavior, and to the typical lack of awareness of each other actions. Here, a two stage strategy based on Recurrent Neural Networks (RNNs) is designed to detect intentional and accidental contacts: the occurrence of a contact with the human is detected at the first stage, while the classification between intentional and accidental is performed at the second stage. An admittance control strategy or an evasive action is then performed by the robot, respectively. The approach also works in the case the robot simultaneously interacts with the human and the environment, where the interaction wrench of the latter is modeled via Gaussian Mixture Models (GMMs). Control Barrier Functions (CBFs) are included, at the control level, to guarantee the satisfaction of robot and task constraints while performing the proper interaction strategy. The approach has been validated on a real setup composed of a Kinova Jaco2 robot.
A Mixed-Integer Linear Programming Formulation for Human Multi-Robot Task Allocation
Jun 12, 2021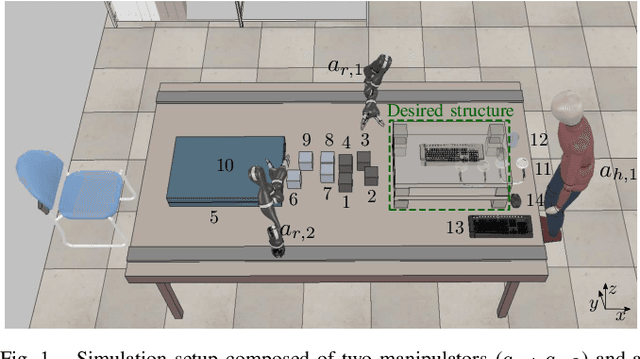

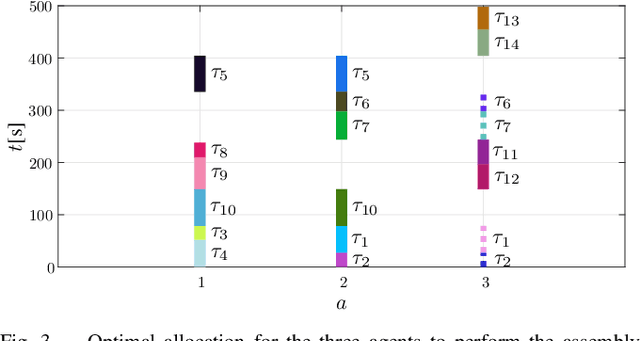
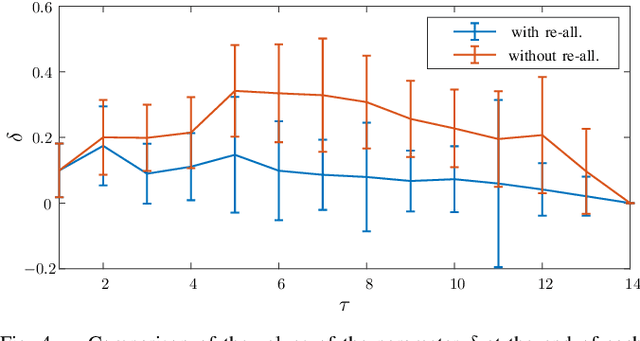
In this work, we address a task allocation problem for human multi-robot settings. Given a set of tasks to perform, we formulate a general Mixed-Integer Linear Programming (MILP) problem aiming at minimizing the overall execution time while optimizing the quality of the executed tasks as well as human and robotic workload. Different skills of the agents, both human and robotic, are taken into account and human operators are enabled to either directly execute tasks or play supervisory roles; moreover, multiple manipulators can tightly collaborate if required to carry out a task. Finally, as realistic in human contexts, human parameters are assumed to vary over time, e.g., due to increasing human level of fatigue. Therefore, online monitoring is required and re-allocation is performed if needed. Simulations in a realistic scenario with two manipulators and a human operator performing an assembly task validate the effectiveness of the approach.