 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquine Pain Behavior Classification via Self-Supervised Disentangled Pose Representation
Aug 30, 2021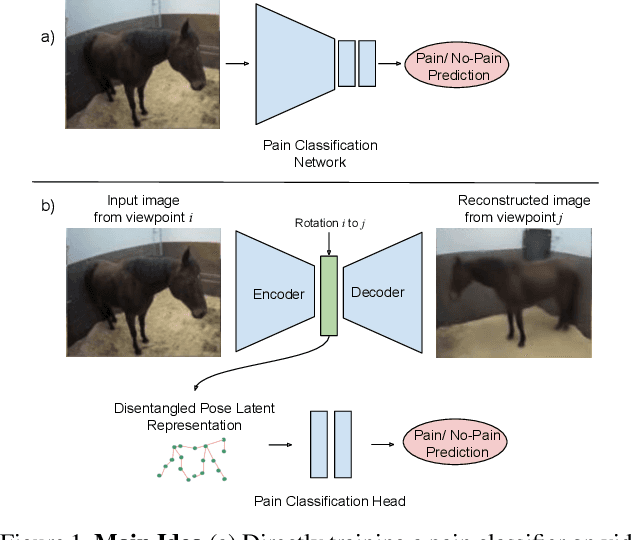
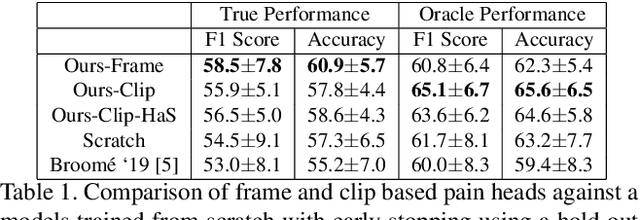
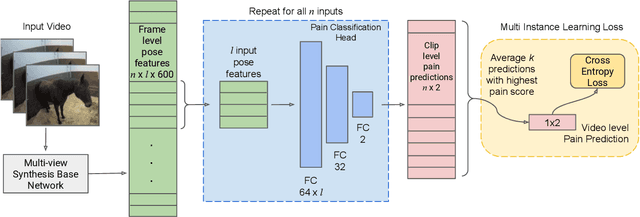

Timely detection of horse pain is important for equine welfare. Horses express pain through their facial and body behavior, but may hide signs of pain from unfamiliar human observers. In addition, collecting visual data with detailed annotation of horse behavior and pain state is both cumbersome and not scalable. Consequently, a pragmatic equine pain classification system would use video of the unobserved horse and weak labels. This paper proposes such a method for equine pain classification by using multi-view surveillance video footage of unobserved horses with induced orthopaedic pain, with temporally sparse video level pain labels. To ensure that pain is learned from horse body language alone, we first train a self-supervised generative model to disentangle horse pose from its appearance and background before using the disentangled horse pose latent representation for pain classification. To make best use of the pain labels, we develop a novel loss that formulates pain classification as a multi-instance learning problem. Our method achieves pain classification accuracy better than human expert performance with 60% accuracy. The learned latent horse pose representation is shown to be viewpoint covariant, and disentangled from horse appearance. Qualitative analysis of pain classified segments shows correspondence between the pain symptoms identified by our model, and equine pain scales used in veterinary practice.
hSMAL: Detailed Horse Shape and Pose Reconstruction for Motion Pattern Recognition
Jun 18, 2021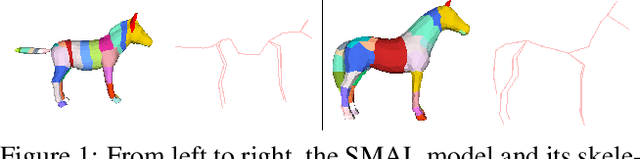
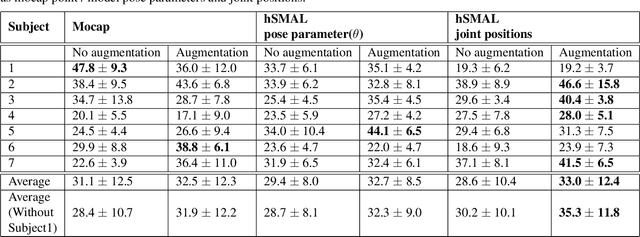
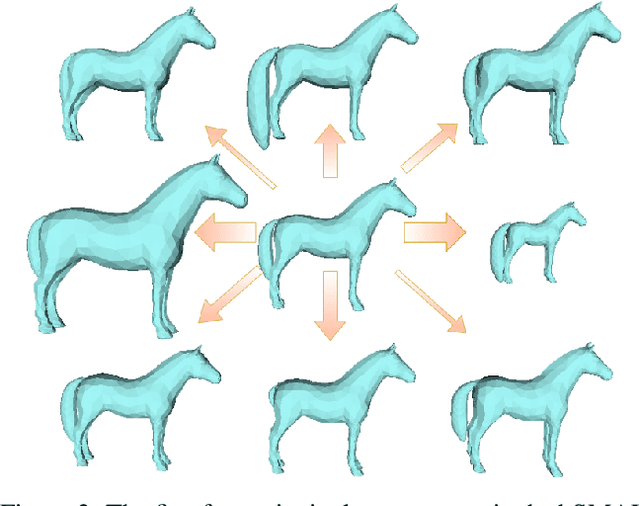
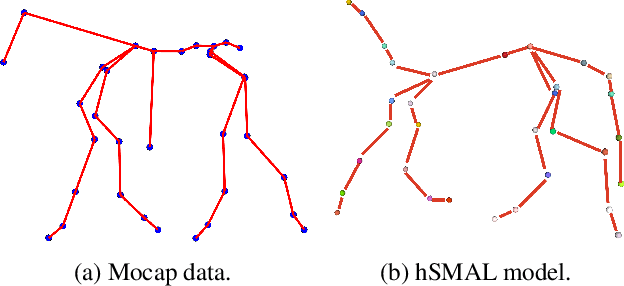
In this paper we present our preliminary work on model-based behavioral analysis of horse motion. Our approach is based on the SMAL model, a 3D articulated statistical model of animal shape. We define a novel SMAL model for horses based on a new template, skeleton and shape space learned from $37$ horse toys. We test the accuracy of our hSMAL model in reconstructing a horse from 3D mocap data and images. We apply the hSMAL model to the problem of lameness detection from video, where we fit the model to images to recover 3D pose and train an ST-GCN network on pose data. A comparison with the same network trained on mocap points illustrates the benefit of our approach.
Sharing Pain: Using Domain Transfer Between Pain Types for Recognition of Sparse Pain Expressions in Horses
May 21, 2021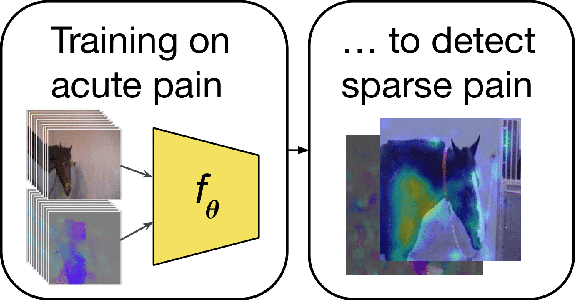

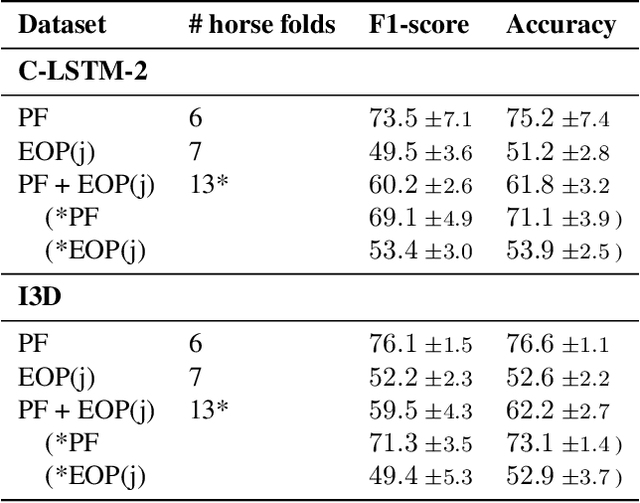
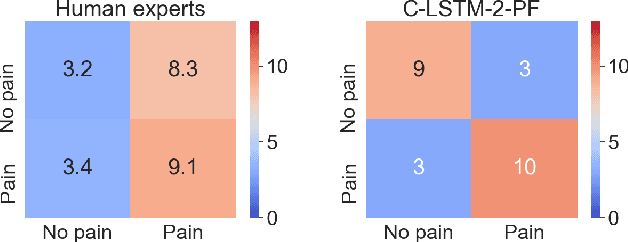
Orthopedic disorders are a common cause for euthanasia among horses, which often could have been avoided with earlier detection. These conditions often create varying degrees of subtle but long-term pain. It is challenging to train a visual pain recognition method with video data depicting such pain, since the resulting pain behavior also is subtle, sparsely appearing, and varying, making it challenging for even an expert human labeler to provide accurate ground-truth for the data. We show that transferring features from a dataset of horses with acute nociceptive pain (where labeling is less ambiguous) can aid the learning to recognize more complex orthopedic pain. Moreover, we present a human expert baseline for the problem, as well as an extensive empirical study of various domain transfer methods and of what is detected by the pain recognition method trained on acute pain in the orthopedic dataset. Finally, this is accompanied with a discussion around the challenges posed by real-world animal behavior datasets and how best practices can be established for similar fine-grained action recognition tasks. Our code is available at https://github.com/sofiabroome/painface-recognition.
Action Graphs: Weakly-supervised Action Localization with Graph Convolution Networks
Feb 04, 2020
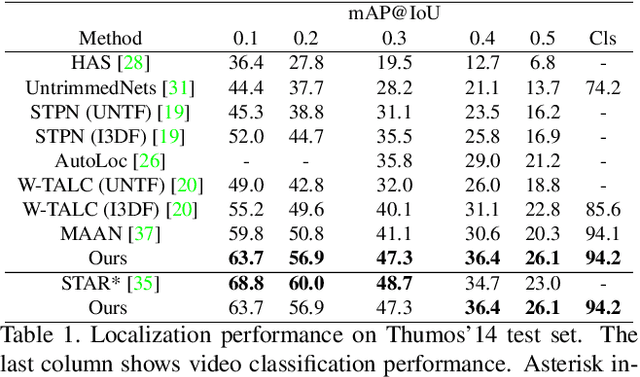
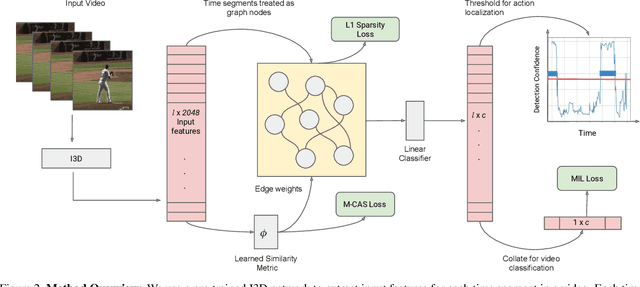
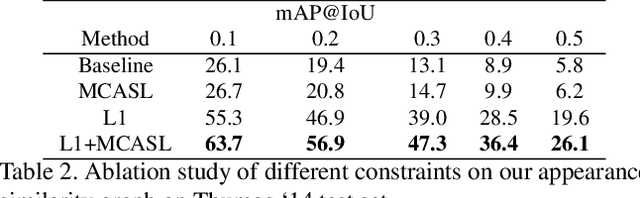
We present a method for weakly-supervised action localization based on graph convolutions. In order to find and classify video time segments that correspond to relevant action classes, a system must be able to both identify discriminative time segments in each video, and identify the full extent of each action. Achieving this with weak video level labels requires the system to use similarity and dissimilarity between moments across videos in the training data to understand both how an action appears, as well as the sub-actions that comprise the action's full extent. However, current methods do not make explicit use of similarity between video moments to inform the localization and classification predictions. We present a novel method that uses graph convolutions to explicitly model similarity between video moments. Our method utilizes similarity graphs that encode appearance and motion, and pushes the state of the art on THUMOS '14, ActivityNet 1.2, and Charades for weakly supervised action localization.
Interspecies Knowledge Transfer for Facial Keypoint Detection
Apr 13, 2017

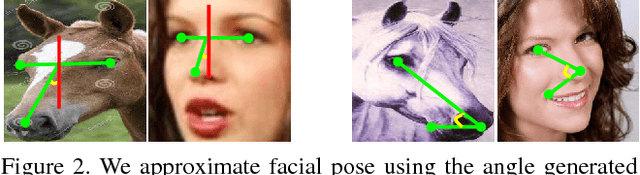

We present a method for localizing facial keypoints on animals by transferring knowledge gained from human faces. Instead of directly finetuning a network trained to detect keypoints on human faces to animal faces (which is sub-optimal since human and animal faces can look quite different), we propose to first adapt the animal images to the pre-trained human detection network by correcting for the differences in animal and human face shape. We first find the nearest human neighbors for each animal image using an unsupervised shape matching method. We use these matches to train a thin plate spline warping network to warp each animal face to look more human-like. The warping network is then jointly finetuned with a pre-trained human facial keypoint detection network using an animal dataset. We demonstrate state-of-the-art results on both horse and sheep facial keypoint detection, and significant improvement over simple finetuning, especially when training data is scarce. Additionally, we present a new dataset with 3717 images with horse face and facial keypoint annotations.