 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability in Contact-Rich Manipulation via Kinodynamic Images
Feb 23, 2021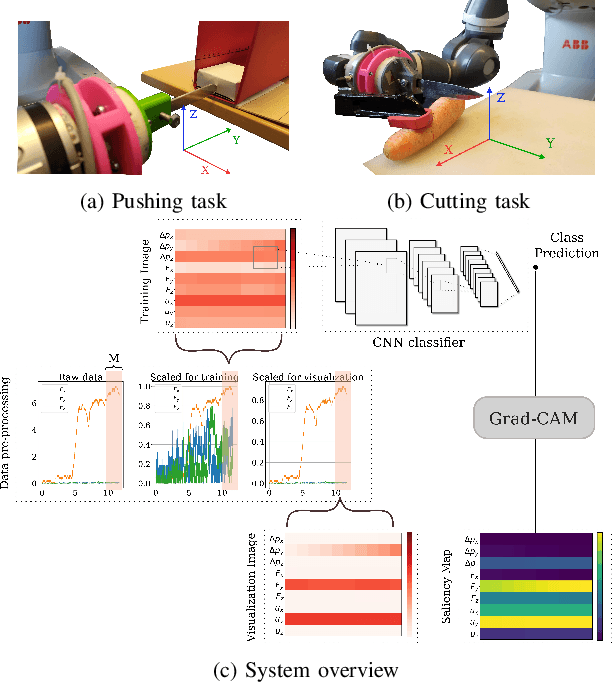
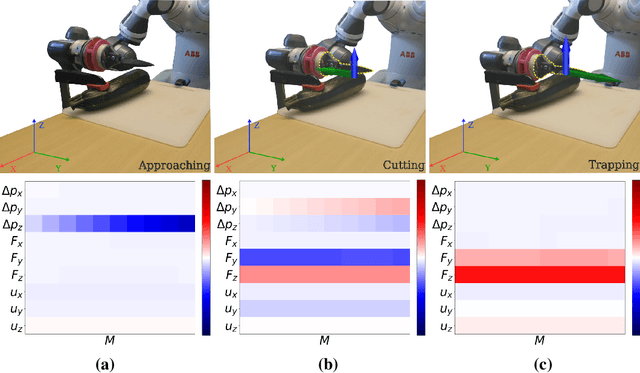
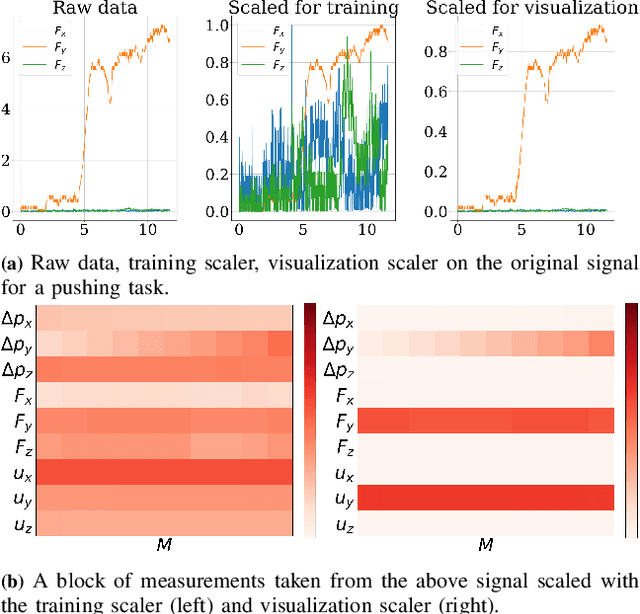

Deep Neural Networks (NNs) have been widely utilized in contact-rich manipulation tasks to model the complicated contact dynamics. However, NN-based models are often difficult to decipher which can lead to seemingly inexplicable behaviors and unidentifiable failure cases. In this work, we address the interpretability of NN-based models by introducing the kinodynamic images. We propose a methodology that creates images from the kinematic and dynamic data of a contact-rich manipulation task. Our formulation visually reflects the task's state by encoding its kinodynamic variations and temporal evolution. By using images as the state representation, we enable the application of interpretability modules that were previously limited to vision-based tasks. We use this representation to train Convolution-based Networks and we extract interpretations of the model's decisions with Grad-CAM, a technique that produces visual explanations. Our method is versatile and can be applied to any classification problem using synchronous features in manipulation to visually interpret which parts of the input drive the model's decisions and distinguish its failure modes. We evaluate this approach on two examples of real-world contact-rich manipulation: pushing and cutting, with known and unknown objects. Finally, we demonstrate that our method enables both detailed visual inspections of sequences in a task, as well as high-level evaluations of a model's behavior and tendencies. Data and code for this work are available at https://github.com/imitsioni/interpretable_manipulation.
Interpreting video features: a comparison of 3D convolutional networks and convolutional LSTM networks
Feb 02, 2020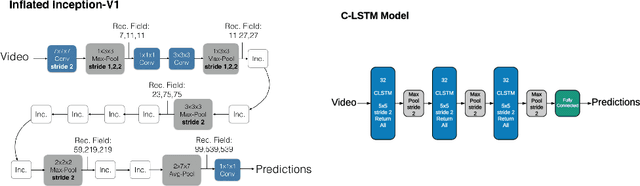


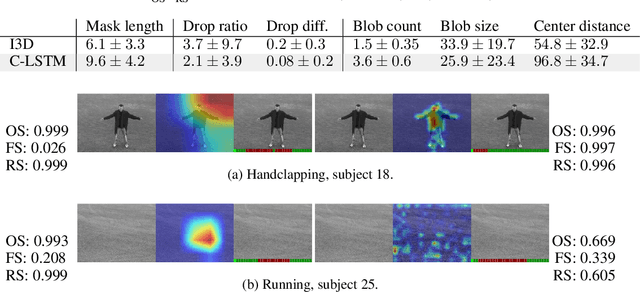
A number of techniques for interpretability have been presented for deep learning in computer vision, typically with the goal of understanding what it is that the networks have actually learned underneath a given classification decision. However, when it comes to deep video architectures, interpretability is still in its infancy and we do not yet have a clear concept of how we should decode spatiotemporal features. In this paper, we present a study comparing how 3D convolutional networks and convolutional LSTM networks learn features across temporally dependent frames. This is the first comparison of two video models that both convolve to learn spatial features but that have principally different methods of modeling time. Additionally, we extend the concept of meaningful perturbation introduced by Fong & Vedaldi (2017) to the temporal dimension to search for the most meaningful part of a sequence for a classification decision.