 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFakePro: Decentralized DeepFake Attacks Detection using ENF Authentication
Jul 22, 2022
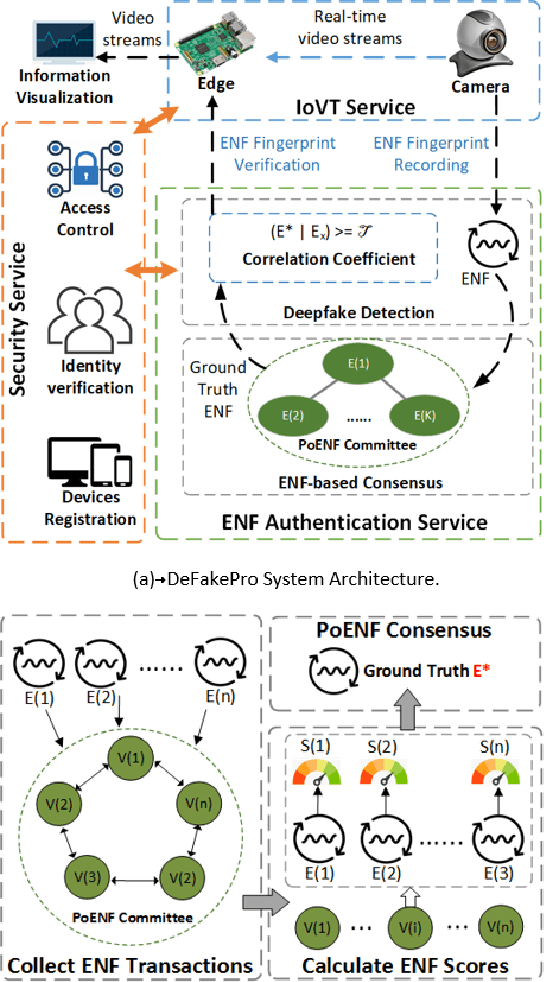
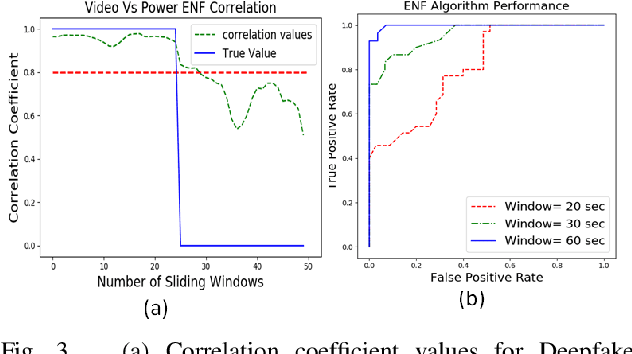
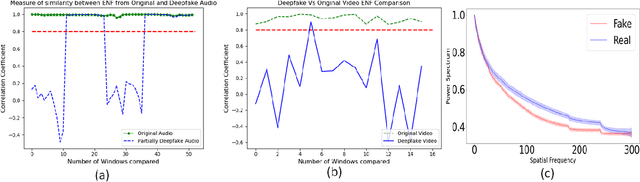
Advancements in generative models, like Deepfake allows users to imitate a targeted person and manipulate online interactions. It has been recognized that disinformation may cause disturbance in society and ruin the foundation of trust. This article presents DeFakePro, a decentralized consensus mechanism-based Deepfake detection technique in online video conferencing tools. Leveraging Electrical Network Frequency (ENF), an environmental fingerprint embedded in digital media recording, affords a consensus mechanism design called Proof-of-ENF (PoENF) algorithm. The similarity in ENF signal fluctuations is utilized in the PoENF algorithm to authenticate the media broadcasted in conferencing tools. By utilizing the video conferencing setup with malicious participants to broadcast deep fake video recordings to other participants, the DeFakePro system verifies the authenticity of the incoming media in both audio and video channels.
I-ViSE: Interactive Video Surveillance as an Edge Service using Unsupervised Feature Queries
Mar 09, 2020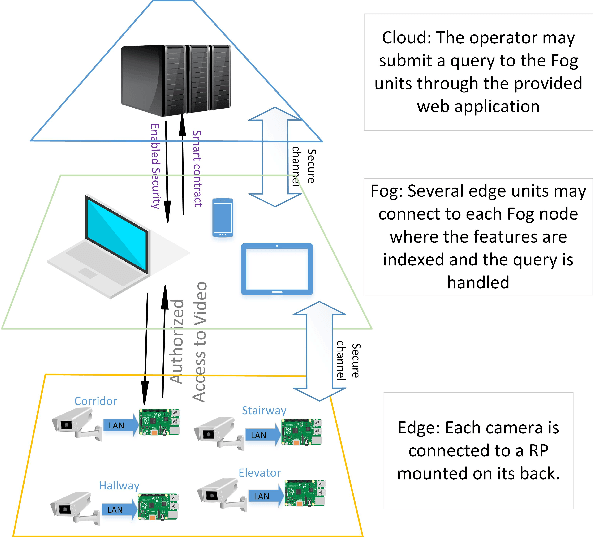
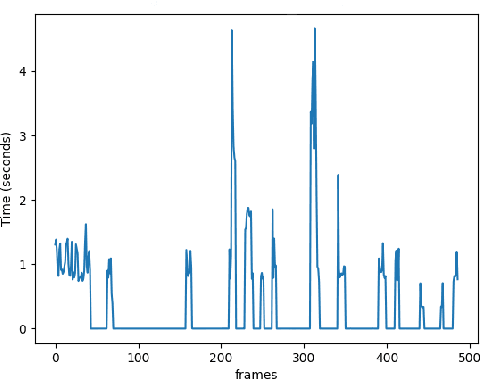


Situation AWareness (SAW) is essential for many mission critical applications. However, SAW is very challenging when trying to immediately identify objects of interest or zoom in on suspicious activities from thousands of video frames. This work aims at developing a queryable system to instantly select interesting content. While face recognition technology is mature, in many scenarios like public safety monitoring, the features of objects of interest may be much more complicated than face features. In addition, human operators may not be always able to provide a descriptive, simple, and accurate query. Actually, it is more often that there are only rough, general descriptions of certain suspicious objects or accidents. This paper proposes an Interactive Video Surveillance as an Edge service (I-ViSE) based on unsupervised feature queries. Adopting unsupervised methods that do not reveal any private information, the I-ViSE scheme utilizes general features of a human body and color of clothes. An I-ViSE prototype is built following the edge-fog computing paradigm and the experimental results verified the I-ViSE scheme meets the design goal of scene recognition in less than two seconds.
I-SAFE: Instant Suspicious Activity identiFication at the Edge using Fuzzy Decision Making
Sep 12, 2019


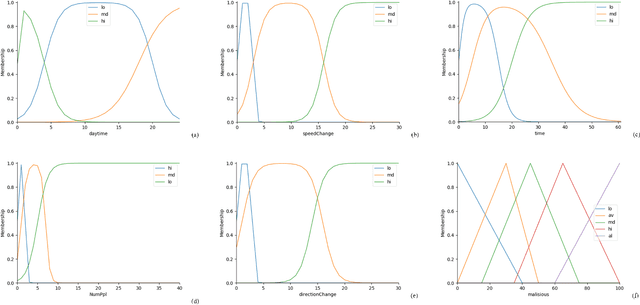
Urban imagery usually serves as forensic analysis and by design is available for incident mitigation. As more imagery collected, it is harder to narrow down to certain frames among thousands of video clips to a specific incident. A real-time, proactive surveillance system is desirable, which could instantly detect dubious personnel, identify suspicious activities, or raise momentous alerts. The recent proliferation of the edge computing paradigm allows more data-intensive tasks to be accomplished by smart edge devices with lightweight but powerful algorithms. This paper presents a forensic surveillance strategy by introducing an Instant Suspicious Activity identiFication at the Edge (I-SAFE) using fuzzy decision making. A fuzzy control system is proposed to mimic the decision-making process of a security officer. Decisions are made based on video features extracted by a lightweight Deep Machine Learning (DML) model. Based on the requirements from the first-line law enforcement officers, several features are selected and fuzzified to cope with the state of uncertainty that exists in the officers' decision-making process. Using features in the edge hierarchy minimizes the communication delay such that instant alerting is achieved. Additionally, leveraging the Microservices architecture, the I-SAFE scheme possesses good scalability given the increasing complexities at the network edge. Implemented as an edge-based application and tested using exemplary and various labeled dataset surveillance videos, the I-SAFE scheme raises alerts by identifying the suspicious activity in an average of 0.002 seconds. Compared to four other state-of-the-art methods over two other data sets, the experimental study verified the superiority of the I-SAFE decentralized method.
Superpixel-enhanced Pairwise Conditional Random Field for Semantic Segmentation
May 29, 2018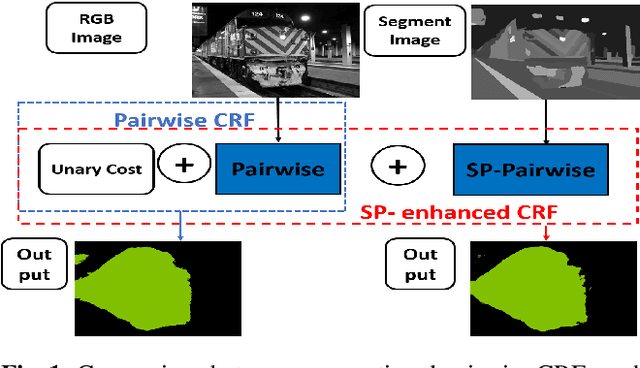
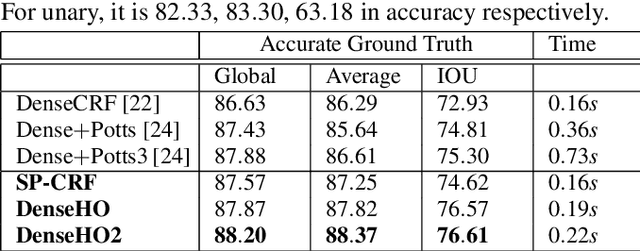

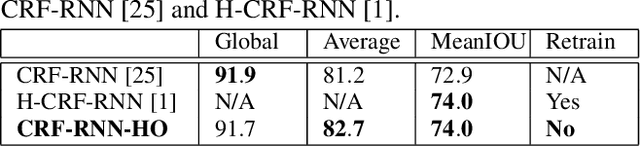
Superpixel-based Higher-order Conditional Random Fields (CRFs) are effective in enforcing long-range consistency in pixel-wise labeling problems, such as semantic segmentation. However, their major short coming is considerably longer time to learn higher-order potentials and extra hyperparameters and/or weights compared with pairwise models. This paper proposes a superpixel-enhanced pairwise CRF framework that consists of the conventional pairwise as well as our proposed superpixel-enhanced pairwise (SP-Pairwise) potentials. SP-Pairwise potentials incorporate the superpixel-based higher-order cues by conditioning on a segment filtered image and share the same set of parameters as the conventional pairwise potentials. Therefore, the proposed superpixel-enhanced pairwise CRF has a lower time complexity in parameter learning and at the same time it outperforms higher-order CRF in terms of inference accuracy. Moreover, the new scheme takes advantage of the pre-trained pairwise models by reusing their parameters and/or weights, which provides a significant accuracy boost on the basis of CRF-RNN even without training. Experiments on MSRC-21 and PASCAL VOC 2012 dataset confirm the effectiveness of our method.
* 5 pages
A Multi-Layer Approach to Superpixel-based Higher-order Conditional Random Field for Semantic Image Segmentation
Apr 05, 2018
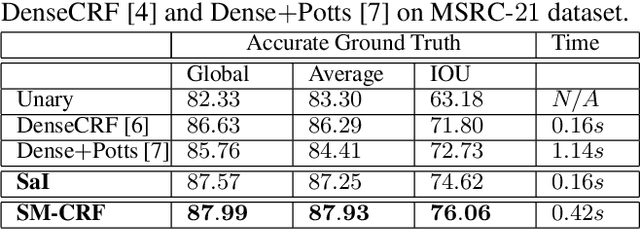
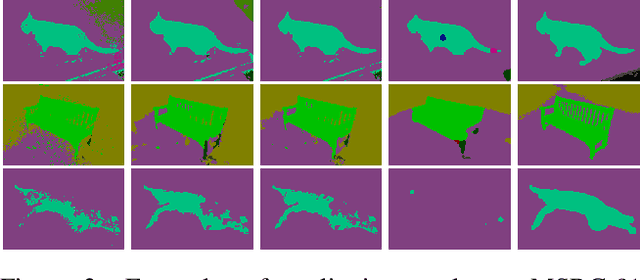

Superpixel-based Higher-order Conditional random fields (SP-HO-CRFs) are known for their effectiveness in enforcing both short and long spatial contiguity for pixelwise labelling in computer vision. However, their higher-order potentials are usually too complex to learn and often incur a high computational cost in performing inference. We propose an new approximation approach to SP-HO-CRFs that resolves these problems. Our approach is a multi-layer CRF framework that inherits the simplicity from pairwise CRFs by formulating both the higher-order and pairwise cues into the same pairwise potentials in the first layer. Essentially, this approach provides accuracy enhancement on the basis of pairwise CRFs without training by reusing their pre-trained parameters and/or weights. The proposed multi-layer approach performs especially well in delineating the boundary details (boarders) of object categories such as "trees" and "bushes". Multiple sets of experiments conducted on dataset MSRC-21 and PASCAL VOC 2012 validate the effectiveness and efficiency of the proposed methods.