 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025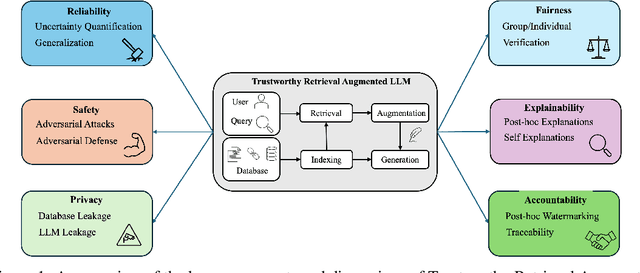
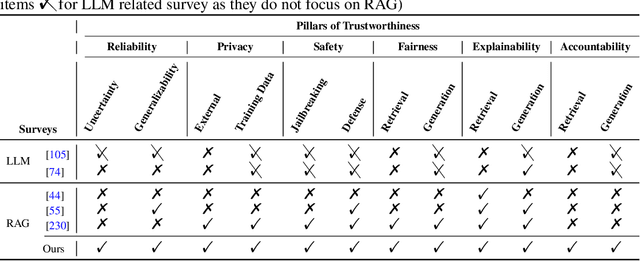


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Machine Knowledge: Creation and Curation of Comprehensive Knowledge Bases
Sep 24, 2020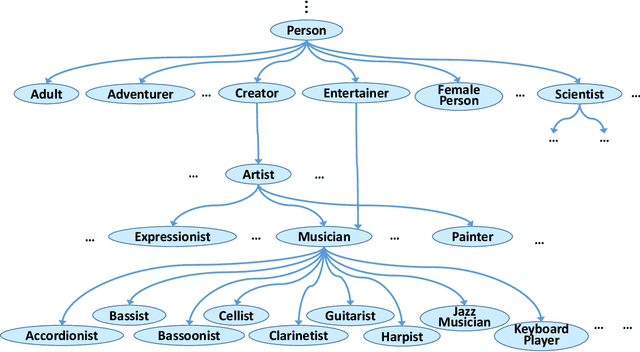
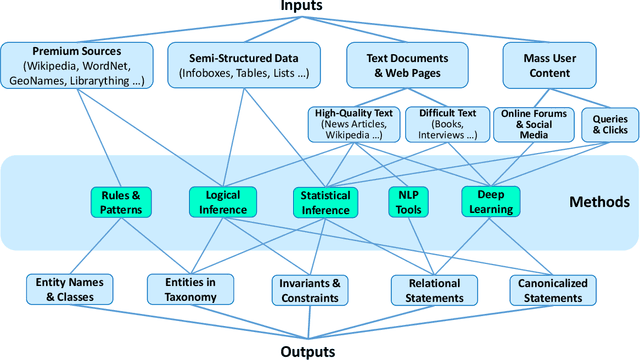


Equipping machines with comprehensive knowledge of the world's entities and their relationships has been a long-standing goal of AI. Over the last decade, large-scale knowledge bases, also known as knowledge graphs, have been automatically constructed from web contents and text sources, and have become a key asset for search engines. This machine knowledge can be harnessed to semantically interpret textual phrases in news, social media and web tables, and contributes to question answering, natural language processing and data analytics. This article surveys fundamental concepts and practical methods for creating and curating large knowledge bases. It covers models and methods for discovering and canonicalizing entities and their semantic types and organizing them into clean taxonomies. On top of this, the article discusses the automatic extraction of entity-centric properties. To support the long-term life-cycle and the quality assurance of machine knowledge, the article presents methods for constructing open schemas and for knowledge curation. Case studies on academic projects and industrial knowledge graphs complement the survey of concepts and methods.