 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fake News Detection via CLIP-Guided Learning
Paper and Code
May 28, 2022
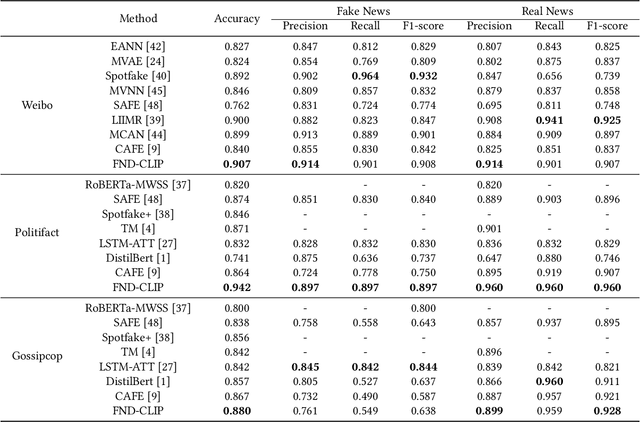
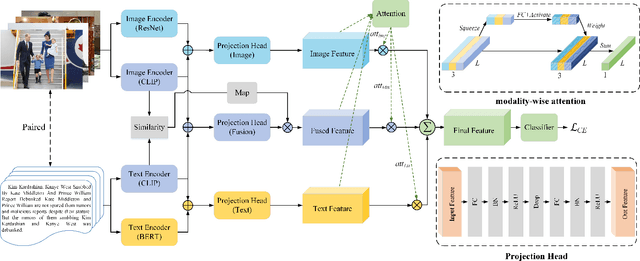

Multimodal fake news detection has attracted many research interests in social forensics. Many existing approaches introduce tailored attention mechanisms to guide the fusion of unimodal features. However, how the similarity of these features is calculated and how it will affect the decision-making process in FND are still open questions. Besides, the potential of pretrained multi-modal feature learning models in fake news detection has not been well exploited. This paper proposes a FND-CLIP framework, i.e., a multimodal Fake News Detection network based on Contrastive Language-Image Pretraining (CLIP). Given a targeted multimodal news, we extract the deep representations from the image and text using a ResNet-based encoder, a BERT-based encoder and two pair-wise CLIP encoders. The multimodal feature is a concatenation of the CLIP-generated features weighted by the standardized cross-modal similarity of the two modalities. The extracted features are further processed for redundancy reduction before feeding them into the final classifier. We introduce a modality-wise attention module to adaptively reweight and aggregate the features. We have conducted extensive experiments on typical fake news datasets. The results indicate that the proposed framework has a better capability in mining crucial features for fake news detection. The proposed FND-CLIP can achieve better performances than previous works, i.e., 0.7\%, 6.8\% and 1.3\% improvements in overall accuracy on Weibo, Politifact and Gossipcop, respectively. Besides, we justify that CLIP-based learning can allow better flexibility on multimodal feature selection.