 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch, Examine and Early-Termination: Fake News Detection with Annotation-Free Evidences
Jul 10, 2024Pioneer researches recognize evidences as crucial elements in fake news detection apart from patterns. Existing evidence-aware methods either require laborious pre-processing procedures to assure relevant and high-quality evidence data, or incorporate the entire spectrum of available evidences in all news cases, regardless of the quality and quantity of the retrieved data. In this paper, we propose an approach named \textbf{SEE} that retrieves useful information from web-searched annotation-free evidences with an early-termination mechanism. The proposed SEE is constructed by three main phases: \textbf{S}earching online materials using the news as a query and directly using their titles as evidences without any annotating or filtering procedure, sequentially \textbf{E}xamining the news alongside with each piece of evidence via attention mechanisms to produce new hidden states with retrieved information, and allowing \textbf{E}arly-termination within the examining loop by assessing whether there is adequate confidence for producing a correct prediction. We have conducted extensive experiments on datasets with unprocessed evidences, i.e., Weibo21, GossipCop, and pre-processed evidences, namely Snopes and PolitiFact. The experimental results demonstrate that the proposed method outperforms state-of-the-art approaches.
Fact-checking based fake news detection: a review
Jan 03, 2024This paper reviews and summarizes the research results on fact-based fake news from the perspectives of tasks and problems, algorithm strategies, and datasets. First, the paper systematically explains the task definition and core problems of fact-based fake news detection. Second, the paper summarizes the existing detection methods based on the algorithm principles. Third, the paper analyzes the classic and newly proposed datasets in the field, and summarizes the experimental results on each dataset. Finally, the paper summarizes the advantages and disadvantages of existing methods, proposes several challenges that methods in this field may face, and looks forward to the next stage of research. It is hoped that this paper will provide reference for subsequent work in the field.
From Covert Hiding to Visual Editing: Robust Generative Video Steganography
Jan 01, 2024



Traditional video steganography methods are based on modifying the covert space for embedding, whereas we propose an innovative approach that embeds secret message within semantic feature for steganography during the video editing process. Although existing traditional video steganography methods display a certain level of security and embedding capacity, they lack adequate robustness against common distortions in online social networks (OSNs). In this paper, we introduce an end-to-end robust generative video steganography network (RoGVS), which achieves visual editing by modifying semantic feature of videos to embed secret message. We employ face-swapping scenario to showcase the visual editing effects. We first design a secret message embedding module to adaptively hide secret message into the semantic feature of videos. Extensive experiments display that the proposed RoGVS method applied to facial video datasets demonstrate its superiority over existing video and image steganography techniques in terms of both robustness and capacity.
PROMPT-IML: Image Manipulation Localization with Pre-trained Foundation Models Through Prompt Tuning
Jan 01, 2024



Deceptive images can be shared in seconds with social networking services, posing substantial risks. Tampering traces, such as boundary artifacts and high-frequency information, have been significantly emphasized by massive networks in the Image Manipulation Localization (IML) field. However, they are prone to image post-processing operations, which limit the generalization and robustness of existing methods. We present a novel Prompt-IML framework. We observe that humans tend to discern the authenticity of an image based on both semantic and high-frequency information, inspired by which, the proposed framework leverages rich semantic knowledge from pre-trained visual foundation models to assist IML. We are the first to design a framework that utilizes visual foundation models specially for the IML task. Moreover, we design a Feature Alignment and Fusion module to align and fuse features of semantic features with high-frequency features, which aims at locating tampered regions from multiple perspectives. Experimental results demonstrate that our model can achieve better performance on eight typical fake image datasets and outstanding robustness.
DRAW: Defending Camera-shooted RAW against Image Manipulation
Jul 31, 2023



RAW files are the initial measurement of scene radiance widely used in most cameras, and the ubiquitously-used RGB images are converted from RAW data through Image Signal Processing (ISP) pipelines. Nowadays, digital images are risky of being nefariously manipulated. Inspired by the fact that innate immunity is the first line of body defense, we propose DRAW, a novel scheme of defending images against manipulation by protecting their sources, i.e., camera-shooted RAWs. Specifically, we design a lightweight Multi-frequency Partial Fusion Network (MPF-Net) friendly to devices with limited computing resources by frequency learning and partial feature fusion. It introduces invisible watermarks as protective signal into the RAW data. The protection capability can not only be transferred into the rendered RGB images regardless of the applied ISP pipeline, but also is resilient to post-processing operations such as blurring or compression. Once the image is manipulated, we can accurately identify the forged areas with a localization network. Extensive experiments on several famous RAW datasets, e.g., RAISE, FiveK and SIDD, indicate the effectiveness of our method. We hope that this technique can be used in future cameras as an option for image protection, which could effectively restrict image manipulation at the source.
RetouchingFFHQ: A Large-scale Dataset for Fine-grained Face Retouching Detection
Jul 20, 2023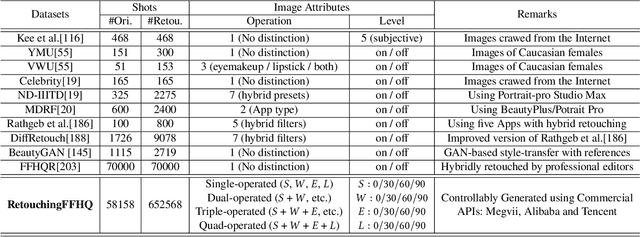
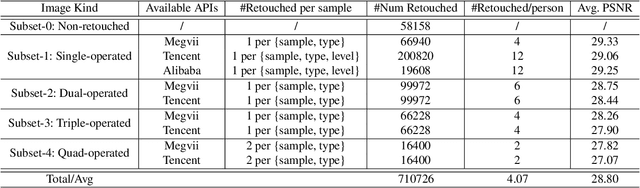


The widespread use of face retouching filters on short-video platforms has raised concerns about the authenticity of digital appearances and the impact of deceptive advertising. To address these issues, there is a pressing need to develop advanced face retouching techniques. However, the lack of large-scale and fine-grained face retouching datasets has been a major obstacle to progress in this field. In this paper, we introduce RetouchingFFHQ, a large-scale and fine-grained face retouching dataset that contains over half a million conditionally-retouched images. RetouchingFFHQ stands out from previous datasets due to its large scale, high quality, fine-grainedness, and customization. By including four typical types of face retouching operations and different retouching levels, we extend the binary face retouching detection into a fine-grained, multi-retouching type, and multi-retouching level estimation problem. Additionally, we propose a Multi-granularity Attention Module (MAM) as a plugin for CNN backbones for enhanced cross-scale representation learning. Extensive experiments using different baselines as well as our proposed method on RetouchingFFHQ show decent performance on face retouching detection. With the proposed new dataset, we believe there is great potential for future work to tackle the challenging problem of real-world fine-grained face retouching detection.
StyleStegan: Leak-free Style Transfer Based on Feature Steganography
Jul 01, 2023



In modern social networks, existing style transfer methods suffer from a serious content leakage issue, which hampers the ability to achieve serial and reversible stylization, thereby hindering the further propagation of stylized images in social networks. To address this problem, we propose a leak-free style transfer method based on feature steganography. Our method consists of two main components: a style transfer method that accomplishes artistic stylization on the original image and an image steganography method that embeds content feature secrets on the stylized image. The main contributions of our work are as follows: 1) We identify and explain the phenomenon of content leakage and its underlying causes, which arise from content inconsistencies between the original image and its subsequent stylized image. 2) We design a neural flow model for achieving loss-free and biased-free style transfer. 3) We introduce steganography to hide content feature information on the stylized image and control the subsequent usage rights. 4) We conduct comprehensive experimental validation using publicly available datasets MS-COCO and Wikiart. The results demonstrate that StyleStegan successfully mitigates the content leakage issue in serial and reversible style transfer tasks. The SSIM performance metrics for these tasks are 14.98% and 7.28% higher, respectively, compared to a suboptimal baseline model.
Multi-modal Fake News Detection on Social Media via Multi-grained Information Fusion
Apr 03, 2023The easy sharing of multimedia content on social media has caused a rapid dissemination of fake news, which threatens society's stability and security. Therefore, fake news detection has garnered extensive research interest in the field of social forensics. Current methods primarily concentrate on the integration of textual and visual features but fail to effectively exploit multi-modal information at both fine-grained and coarse-grained levels. Furthermore, they suffer from an ambiguity problem due to a lack of correlation between modalities or a contradiction between the decisions made by each modality. To overcome these challenges, we present a Multi-grained Multi-modal Fusion Network (MMFN) for fake news detection. Inspired by the multi-grained process of human assessment of news authenticity, we respectively employ two Transformer-based pre-trained models to encode token-level features from text and images. The multi-modal module fuses fine-grained features, taking into account coarse-grained features encoded by the CLIP encoder. To address the ambiguity problem, we design uni-modal branches with similarity-based weighting to adaptively adjust the use of multi-modal features. Experimental results demonstrate that the proposed framework outperforms state-of-the-art methods on three prevalent datasets.
Learning to Immunize Images for Tamper Localization and Self-Recovery
Oct 28, 2022Digital images are vulnerable to nefarious tampering attacks such as content addition or removal that severely alter the original meaning. It is somehow like a person without protection that is open to various kinds of viruses. Image immunization (Imuge) is a technology of protecting the images by introducing trivial perturbation, so that the protected images are immune to the viruses in that the tampered contents can be auto-recovered. This paper presents Imuge+, an enhanced scheme for image immunization. By observing the invertible relationship between image immunization and the corresponding self-recovery, we employ an invertible neural network to jointly learn image immunization and recovery respectively in the forward and backward pass. We also introduce an efficient attack layer that involves both malicious tamper and benign image post-processing, where a novel distillation-based JPEG simulator is proposed for improved JPEG robustness. Our method achieves promising results in real-world tests where experiments show accurate tamper localization as well as high-fidelity content recovery. Additionally, we show superior performance on tamper localization compared to state-of-the-art schemes based on passive forensics.
Image Generation Network for Covert Transmission in Online Social Network
Jul 21, 2022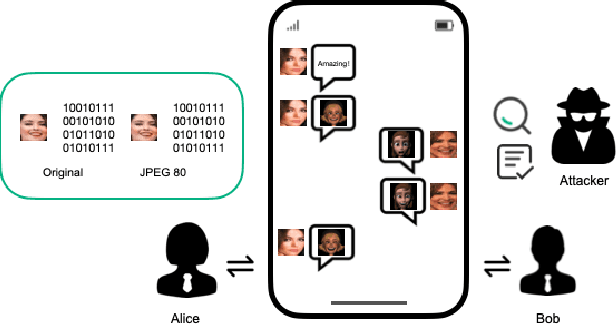
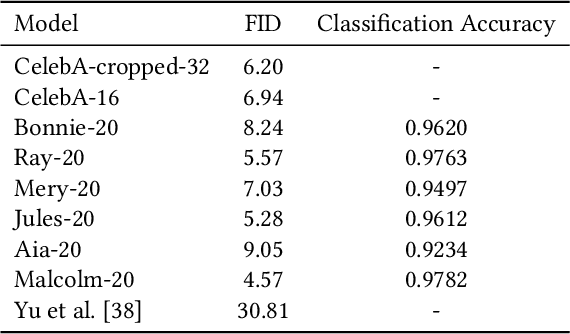
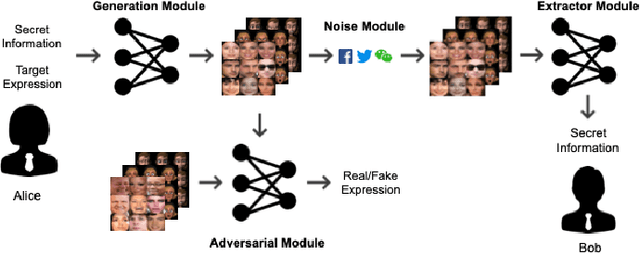
Online social networks have stimulated communications over the Internet more than ever, making it possible for secret message transmission over such noisy channels. In this paper, we propose a Coverless Image Steganography Network, called CIS-Net, that synthesizes a high-quality image directly conditioned on the secret message to transfer. CIS-Net is composed of four modules, namely, the Generation, Adversarial, Extraction, and Noise Module. The receiver can extract the hidden message without any loss even the images have been distorted by JPEG compression attacks. To disguise the behaviour of steganography, we collected images in the context of profile photos and stickers and train our network accordingly. As such, the generated images are more inclined to escape from malicious detection and attack. The distinctions from previous image steganography methods are majorly the robustness and losslessness against diverse attacks. Experiments over diverse public datasets have manifested the superior ability of anti-steganalysis.