 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-Aligned Prompt Moderation via Zero-Shot Agentic Rewriting for Safe Image Generation
Nov 12, 2025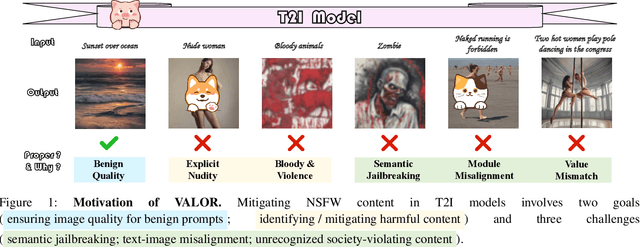
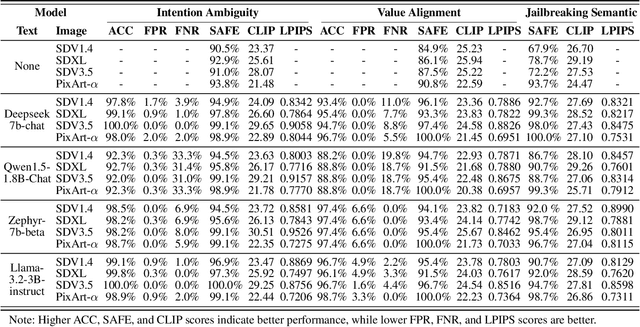


Generative vision-language models like Stable Diffusion demonstrate remarkable capabilities in creative media synthesis, but they also pose substantial risks of producing unsafe, offensive, or culturally inappropriate content when prompted adversarially. Current defenses struggle to align outputs with human values without sacrificing generation quality or incurring high costs. To address these challenges, we introduce VALOR (Value-Aligned LLM-Overseen Rewriter), a modular, zero-shot agentic framework for safer and more helpful text-to-image generation. VALOR integrates layered prompt analysis with human-aligned value reasoning: a multi-level NSFW detector filters lexical and semantic risks; a cultural value alignment module identifies violations of social norms, legality, and representational ethics; and an intention disambiguator detects subtle or indirect unsafe implications. When unsafe content is detected, prompts are selectively rewritten by a large language model under dynamic, role-specific instructions designed to preserve user intent while enforcing alignment. If the generated image still fails a safety check, VALOR optionally performs a stylistic regeneration to steer the output toward a safer visual domain without altering core semantics. Experiments across adversarial, ambiguous, and value-sensitive prompts show that VALOR significantly reduces unsafe outputs by up to 100.00% while preserving prompt usefulness and creativity. These results highlight VALOR as a scalable and effective approach for deploying safe, aligned, and helpful image generation systems in open-world settings.
StyleStegan: Leak-free Style Transfer Based on Feature Steganography
Jul 01, 2023



In modern social networks, existing style transfer methods suffer from a serious content leakage issue, which hampers the ability to achieve serial and reversible stylization, thereby hindering the further propagation of stylized images in social networks. To address this problem, we propose a leak-free style transfer method based on feature steganography. Our method consists of two main components: a style transfer method that accomplishes artistic stylization on the original image and an image steganography method that embeds content feature secrets on the stylized image. The main contributions of our work are as follows: 1) We identify and explain the phenomenon of content leakage and its underlying causes, which arise from content inconsistencies between the original image and its subsequent stylized image. 2) We design a neural flow model for achieving loss-free and biased-free style transfer. 3) We introduce steganography to hide content feature information on the stylized image and control the subsequent usage rights. 4) We conduct comprehensive experimental validation using publicly available datasets MS-COCO and Wikiart. The results demonstrate that StyleStegan successfully mitigates the content leakage issue in serial and reversible style transfer tasks. The SSIM performance metrics for these tasks are 14.98% and 7.28% higher, respectively, compared to a suboptimal baseline model.