 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetouchingFFHQ: A Large-scale Dataset for Fine-grained Face Retouching Detection
Jul 20, 2023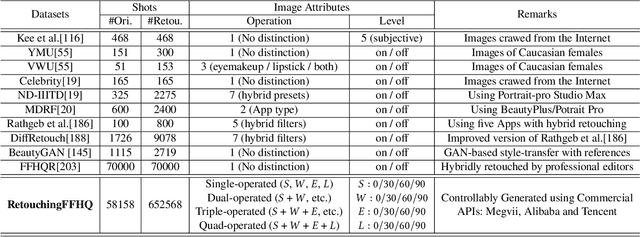
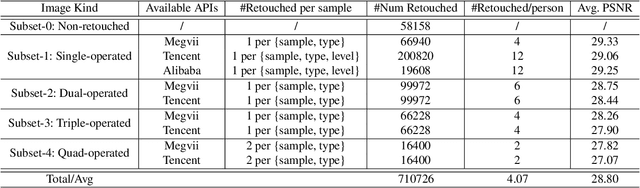


The widespread use of face retouching filters on short-video platforms has raised concerns about the authenticity of digital appearances and the impact of deceptive advertising. To address these issues, there is a pressing need to develop advanced face retouching techniques. However, the lack of large-scale and fine-grained face retouching datasets has been a major obstacle to progress in this field. In this paper, we introduce RetouchingFFHQ, a large-scale and fine-grained face retouching dataset that contains over half a million conditionally-retouched images. RetouchingFFHQ stands out from previous datasets due to its large scale, high quality, fine-grainedness, and customization. By including four typical types of face retouching operations and different retouching levels, we extend the binary face retouching detection into a fine-grained, multi-retouching type, and multi-retouching level estimation problem. Additionally, we propose a Multi-granularity Attention Module (MAM) as a plugin for CNN backbones for enhanced cross-scale representation learning. Extensive experiments using different baselines as well as our proposed method on RetouchingFFHQ show decent performance on face retouching detection. With the proposed new dataset, we believe there is great potential for future work to tackle the challenging problem of real-world fine-grained face retouching detection.
From Image to Imuge: Immunized Image Generation
Oct 27, 2021
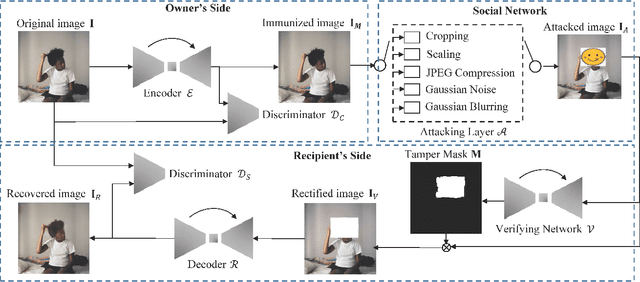
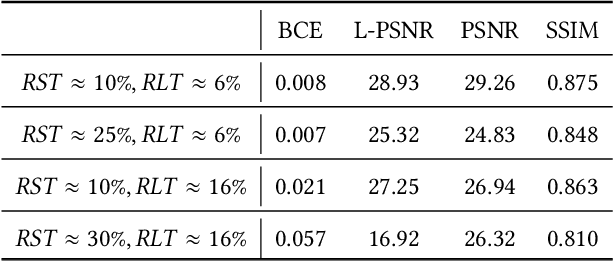
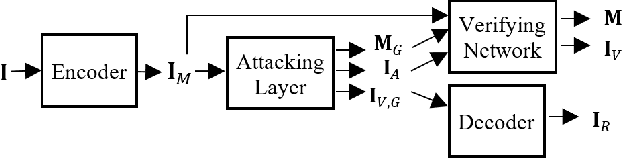
We introduce Imuge, an image tamper resilient generative scheme for image self-recovery. The traditional manner of concealing image content within the image are inflexible and fragile to diverse digital attack, i.e. image cropping and JPEG compression. To address this issue, we jointly train a U-Net backboned encoder, a tamper localization network and a decoder for image recovery. Given an original image, the encoder produces a visually indistinguishable immunized image. At the recipient's side, the verifying network localizes the malicious modifications, and the original content can be approximately recovered by the decoder, despite the presence of the attacks. Several strategies are proposed to boost the training efficiency. We demonstrate that our method can recover the details of the tampered regions with a high quality despite the presence of various kinds of attacks. Comprehensive ablation studies are conducted to validate our network designs.
Hiding Images into Images with Real-world Robustness
Oct 12, 2021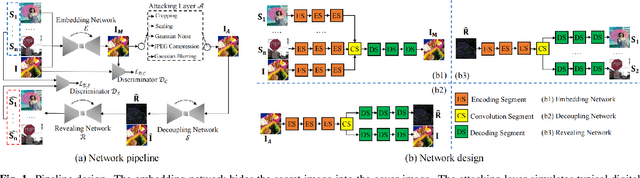
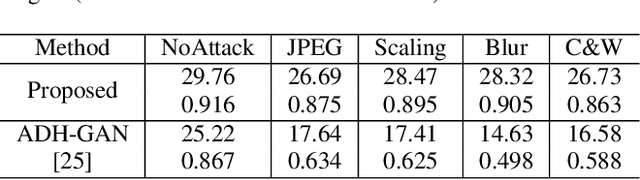


The existing image embedding networks are basically vulnerable to malicious attacks such as JPEG compression and noise adding, not applicable for real-world copyright protection tasks. To solve this problem, we introduce a generative deep network based method for hiding images into images while assuring high-quality extraction from the destructive synthesized images. An embedding network is sequentially concatenated with an attack layer, a decoupling network and an image extraction network. The addition of decoupling network learns to extract the embedded watermark from the attacked image. We also pinpoint the weaknesses of the adversarial training for robustness in previous works and build our improved real-world attack simulator. Experimental results demonstrate the superiority of the proposed method against typical digital attacks by a large margin, as well as the performance boost of the recovered images with the aid of progressive recovery strategy. Besides, we are the first to robustly hide three secret images.