 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Steganography with Dynamic Codebook and Multimodal Large Language Model
Apr 22, 2026With the popularity of the large language models (LLMs), text steganography has achieved remarkable performance. However, existing methods still have some issues: (1) For the white-box paradigm, this steganography behavior is prone to exposure due to sharing the off-the-shelf language model between Alice and Bob.(2) For the black-box paradigm, these methods lack flexibility and practicality since Alice and Bob should share the fixed codebook while sharing a specific extracting prompt for each steganographic sentence. In order to improve the security and practicality, we introduce a black-box text steganography with a dynamic codebook and multimodal large language model. Specifically, we first construct a dynamic codebook via some shared session configuration and a multimodal large language model. Then an encrypted steganographic mapping is designed to embed secret messages during the steganographic caption generation. Furthermore, we introduce a feedback optimization mechanism based on reject sampling to ensure accurate extraction of secret messages. Experimental results show that the proposed method outperforms existing white-box text steganography methods in terms of embedding capacity and text quality. Meanwhile, the proposed method has achieved better practicality and flexibility than the existing black-box paradigm in some popular online social networks.
Cognitive Surgery: The Awakening of Implicit Territorial Awareness in LLMs
Aug 20, 2025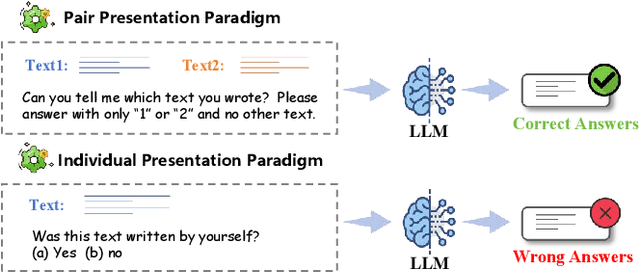
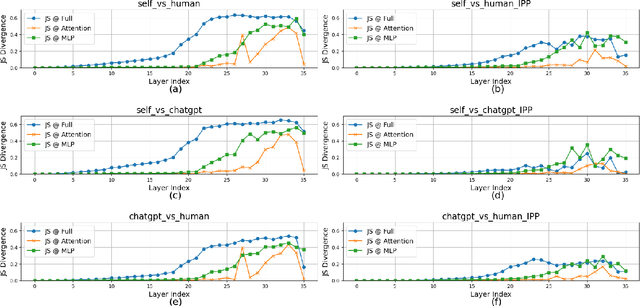

Large language models (LLMs) have been shown to possess a degree of self-recognition capability-the ability to identify whether a given text was generated by themselves. Prior work has demonstrated that this capability is reliably expressed under the Pair Presentation Paradigm (PPP), where the model is presented with two texts and asked to choose which one it authored. However, performance deteriorates sharply under the Individual Presentation Paradigm (IPP), where the model is given a single text to judge authorship. Although this phenomenon has been observed, its underlying causes have not been systematically analyzed. In this paper, we first replicate existing findings to confirm that LLMs struggle to distinguish self- from other-generated text under IPP. We then investigate the reasons for this failure and attribute it to a phenomenon we term Implicit Territorial Awareness (ITA)-the model's latent ability to distinguish self- and other-texts in representational space, which remains unexpressed in its output behavior. To awaken the ITA of LLMs, we propose Cognitive Surgery (CoSur), a novel framework comprising four main modules: representation extraction, territory construction, authorship discrimination and cognitive editing. Experimental results demonstrate that our proposed method improves the performance of three different LLMs in the IPP scenario, achieving average accuracies of 83.25%, 66.19%, and 88.01%, respectively.
EditMF: Drawing an Invisible Fingerprint for Your Large Language Models
Aug 12, 2025Training large language models (LLMs) is resource-intensive and expensive, making protecting intellectual property (IP) for LLMs crucial. Recently, embedding fingerprints into LLMs has emerged as a prevalent method for establishing model ownership. However, existing back-door-based methods suffer from limited stealth and efficiency. To simultaneously address these issues, we propose EditMF, a training-free fingerprinting paradigm that achieves highly imperceptible fingerprint embedding with minimal computational overhead. Ownership bits are mapped to compact, semantically coherent triples drawn from an encrypted artificial knowledge base (e.g., virtual author-novel-protagonist facts). Causal tracing localizes the minimal set of layers influencing each triple, and a zero-space update injects the fingerprint without perturbing unrelated knowledge. Verification requires only a single black-box query and succeeds when the model returns the exact pre-embedded protagonist. Empirical results on LLaMA and Qwen families show that EditMF combines high imperceptibility with negligible model's performance loss, while delivering robustness far beyond LoRA-based fingerprinting and approaching that of SFT embeddings. Extensive experiments demonstrate that EditMF is an effective and low-overhead solution for secure LLM ownership verification.
Kill two birds with one stone: generalized and robust AI-generated text detection via dynamic perturbations
Apr 22, 2025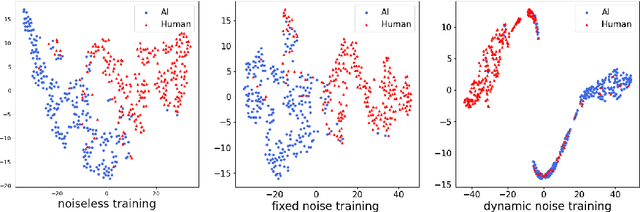

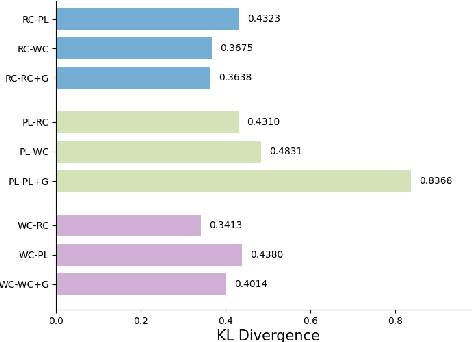

The growing popularity of large language models has raised concerns regarding the potential to misuse AI-generated text (AIGT). It becomes increasingly critical to establish an excellent AIGT detection method with high generalization and robustness. However, existing methods either focus on model generalization or concentrate on robustness. The unified mechanism, to simultaneously address the challenges of generalization and robustness, is less explored. In this paper, we argue that robustness can be view as a specific form of domain shift, and empirically reveal an intrinsic mechanism for model generalization of AIGT detection task. Then, we proposed a novel AIGT detection method (DP-Net) via dynamic perturbations introduced by a reinforcement learning with elaborated reward and action. Experimentally, extensive results show that the proposed DP-Net significantly outperforms some state-of-the-art AIGT detection methods for generalization capacity in three cross-domain scenarios. Meanwhile, the DP-Net achieves best robustness under two text adversarial attacks. The code is publicly available at https://github.com/CAU-ISS-Lab/AIGT-Detection-Evade-Detection/tree/main/DP-Net.
BadApex: Backdoor Attack Based on Adaptive Optimization Mechanism of Black-box Large Language Models
Apr 21, 2025Previous insertion-based and paraphrase-based backdoors have achieved great success in attack efficacy, but they ignore the text quality and semantic consistency between poisoned and clean texts. Although recent studies introduce LLMs to generate poisoned texts and improve the stealthiness, semantic consistency, and text quality, their hand-crafted prompts rely on expert experiences, facing significant challenges in prompt adaptability and attack performance after defenses. In this paper, we propose a novel backdoor attack based on adaptive optimization mechanism of black-box large language models (BadApex), which leverages a black-box LLM to generate poisoned text through a refined prompt. Specifically, an Adaptive Optimization Mechanism is designed to refine an initial prompt iteratively using the generation and modification agents. The generation agent generates the poisoned text based on the initial prompt. Then the modification agent evaluates the quality of the poisoned text and refines a new prompt. After several iterations of the above process, the refined prompt is used to generate poisoned texts through LLMs. We conduct extensive experiments on three dataset with six backdoor attacks and two defenses. Extensive experimental results demonstrate that BadApex significantly outperforms state-of-the-art attacks. It improves prompt adaptability, semantic consistency, and text quality. Furthermore, when two defense methods are applied, the average attack success rate (ASR) still up to 96.75%.
Transparent Object Depth Completion
May 24, 2024



The perception of transparent objects for grasp and manipulation remains a major challenge, because existing robotic grasp methods which heavily rely on depth maps are not suitable for transparent objects due to their unique visual properties. These properties lead to gaps and inaccuracies in the depth maps of the transparent objects captured by depth sensors. To address this issue, we propose an end-to-end network for transparent object depth completion that combines the strengths of single-view RGB-D based depth completion and multi-view depth estimation. Moreover, we introduce a depth refinement module based on confidence estimation to fuse predicted depth maps from single-view and multi-view modules, which further refines the restored depth map. The extensive experiments on the ClearPose and TransCG datasets demonstrate that our method achieves superior accuracy and robustness in complex scenarios with significant occlusion compared to the state-of-the-art methods.
Generative Text Steganography with Large Language Model
Apr 16, 2024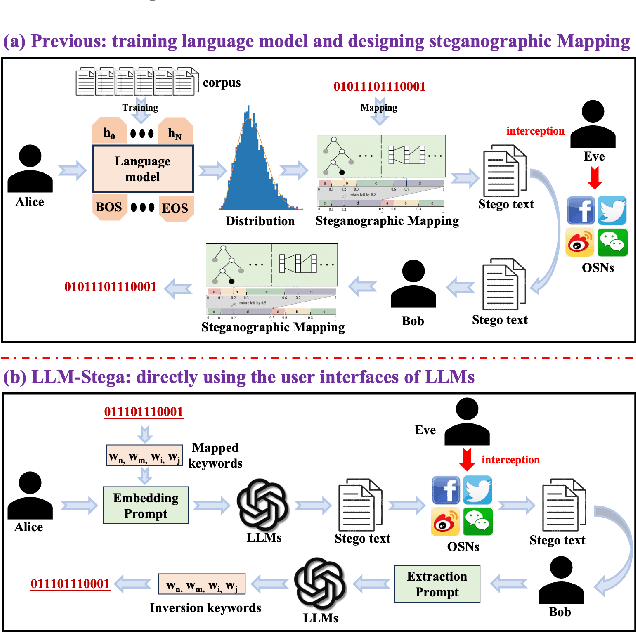
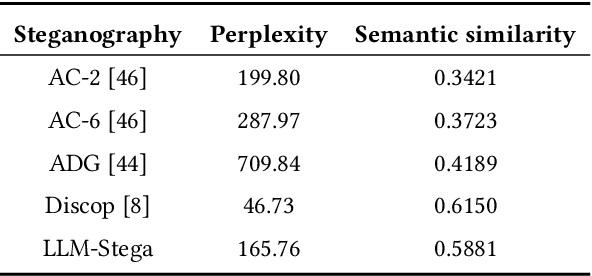
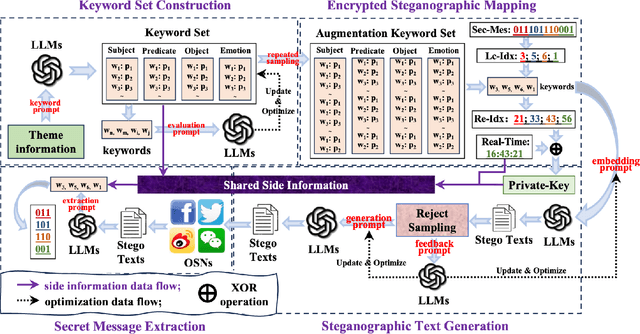
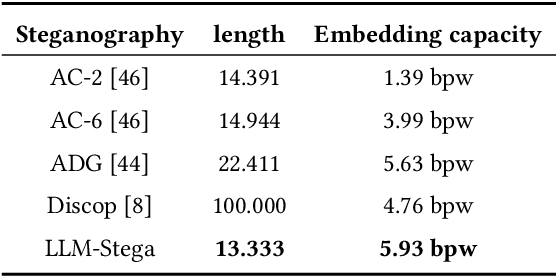
Recent advances in large language models (LLMs) have blurred the boundary of high-quality text generation between humans and machines, which is favorable for generative text steganography. While, current advanced steganographic mapping is not suitable for LLMs since most users are restricted to accessing only the black-box API or user interface of the LLMs, thereby lacking access to the training vocabulary and its sampling probabilities. In this paper, we explore a black-box generative text steganographic method based on the user interfaces of large language models, which is called LLM-Stega. The main goal of LLM-Stega is that the secure covert communication between Alice (sender) and Bob (receiver) is conducted by using the user interfaces of LLMs. Specifically, We first construct a keyword set and design a new encrypted steganographic mapping to embed secret messages. Furthermore, to guarantee accurate extraction of secret messages and rich semantics of generated stego texts, an optimization mechanism based on reject sampling is proposed. Comprehensive experiments demonstrate that the proposed LLM-Stega outperforms current state-of-the-art methods.
From Covert Hiding to Visual Editing: Robust Generative Video Steganography
Jan 01, 2024



Traditional video steganography methods are based on modifying the covert space for embedding, whereas we propose an innovative approach that embeds secret message within semantic feature for steganography during the video editing process. Although existing traditional video steganography methods display a certain level of security and embedding capacity, they lack adequate robustness against common distortions in online social networks (OSNs). In this paper, we introduce an end-to-end robust generative video steganography network (RoGVS), which achieves visual editing by modifying semantic feature of videos to embed secret message. We employ face-swapping scenario to showcase the visual editing effects. We first design a secret message embedding module to adaptively hide secret message into the semantic feature of videos. Extensive experiments display that the proposed RoGVS method applied to facial video datasets demonstrate its superiority over existing video and image steganography techniques in terms of both robustness and capacity.
Improved CNN Prediction Based Reversible Data Hiding
Jan 04, 2023



This letter proposes an improved CNN predictor (ICNNP) for reversible data hiding (RDH) in images, which consists of a feature extraction module, a pixel prediction module, and a complexity prediction module. Due to predicting the complexity of each pixel with the ICNNP during the embedding process, the proposed method can achieve superior performance than the CNN predictor-based method. Specifically, an input image does be first split into two different sub-images, i.e., the "Dot" image and the "Cross" image. Meanwhile, each sub-image is applied to predict another one. Then, the prediction errors of pixels are sorted with the predicted pixel complexities. In light of this, some sorted prediction errors with less complexity are selected to be efficiently used for low-distortion data embedding with a traditional histogram shift scheme. Experimental results demonstrate that the proposed method can achieve better embedding performance than that of the CNN predictor with the same histogram shifting strategy.
TransGrasp: Grasp Pose Estimation of a Category of Objects by Transferring Grasps from Only One Labeled Instance
Jul 25, 2022

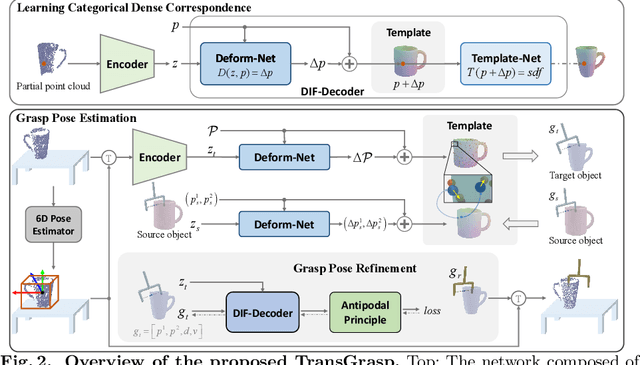

Grasp pose estimation is an important issue for robots to interact with the real world. However, most of existing methods require exact 3D object models available beforehand or a large amount of grasp annotations for training. To avoid these problems, we propose TransGrasp, a category-level grasp pose estimation method that predicts grasp poses of a category of objects by labeling only one object instance. Specifically, we perform grasp pose transfer across a category of objects based on their shape correspondences and propose a grasp pose refinement module to further fine-tune grasp pose of grippers so as to ensure successful grasps. Experiments demonstrate the effectiveness of our method on achieving high-quality grasps with the transferred grasp poses. Our code is available at https://github.com/yanjh97/TransGrasp.