 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFM-Editing: Rectified Flow Matching for Text-guided Audio Editing
Sep 17, 2025Diffusion models have shown remarkable progress in text-to-audio generation. However, text-guided audio editing remains in its early stages. This task focuses on modifying the target content within an audio signal while preserving the rest, thus demanding precise localization and faithful editing according to the text prompt. Existing training-based and zero-shot methods that rely on full-caption or costly optimization often struggle with complex editing or lack practicality. In this work, we propose a novel end-to-end efficient rectified flow matching-based diffusion framework for audio editing, and construct a dataset featuring overlapping multi-event audio to support training and benchmarking in complex scenarios. Experiments show that our model achieves faithful semantic alignment without requiring auxiliary captions or masks, while maintaining competitive editing quality across metrics.
Cognitive Surgery: The Awakening of Implicit Territorial Awareness in LLMs
Aug 20, 2025
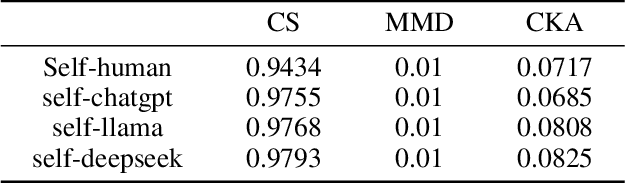
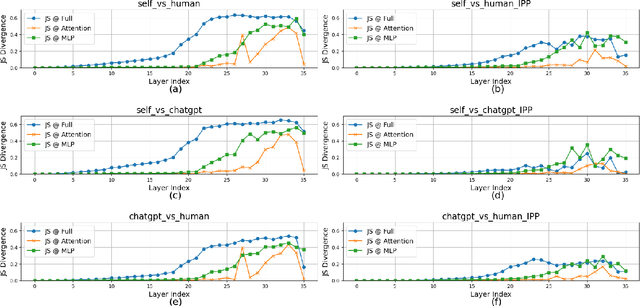

Large language models (LLMs) have been shown to possess a degree of self-recognition capability-the ability to identify whether a given text was generated by themselves. Prior work has demonstrated that this capability is reliably expressed under the Pair Presentation Paradigm (PPP), where the model is presented with two texts and asked to choose which one it authored. However, performance deteriorates sharply under the Individual Presentation Paradigm (IPP), where the model is given a single text to judge authorship. Although this phenomenon has been observed, its underlying causes have not been systematically analyzed. In this paper, we first replicate existing findings to confirm that LLMs struggle to distinguish self- from other-generated text under IPP. We then investigate the reasons for this failure and attribute it to a phenomenon we term Implicit Territorial Awareness (ITA)-the model's latent ability to distinguish self- and other-texts in representational space, which remains unexpressed in its output behavior. To awaken the ITA of LLMs, we propose Cognitive Surgery (CoSur), a novel framework comprising four main modules: representation extraction, territory construction, authorship discrimination and cognitive editing. Experimental results demonstrate that our proposed method improves the performance of three different LLMs in the IPP scenario, achieving average accuracies of 83.25%, 66.19%, and 88.01%, respectively.
EditMF: Drawing an Invisible Fingerprint for Your Large Language Models
Aug 12, 2025Training large language models (LLMs) is resource-intensive and expensive, making protecting intellectual property (IP) for LLMs crucial. Recently, embedding fingerprints into LLMs has emerged as a prevalent method for establishing model ownership. However, existing back-door-based methods suffer from limited stealth and efficiency. To simultaneously address these issues, we propose EditMF, a training-free fingerprinting paradigm that achieves highly imperceptible fingerprint embedding with minimal computational overhead. Ownership bits are mapped to compact, semantically coherent triples drawn from an encrypted artificial knowledge base (e.g., virtual author-novel-protagonist facts). Causal tracing localizes the minimal set of layers influencing each triple, and a zero-space update injects the fingerprint without perturbing unrelated knowledge. Verification requires only a single black-box query and succeeds when the model returns the exact pre-embedded protagonist. Empirical results on LLaMA and Qwen families show that EditMF combines high imperceptibility with negligible model's performance loss, while delivering robustness far beyond LoRA-based fingerprinting and approaching that of SFT embeddings. Extensive experiments demonstrate that EditMF is an effective and low-overhead solution for secure LLM ownership verification.
Kill two birds with one stone: generalized and robust AI-generated text detection via dynamic perturbations
Apr 22, 2025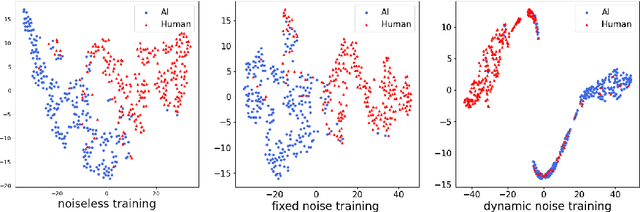

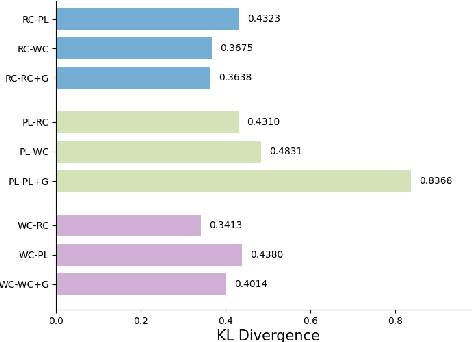

The growing popularity of large language models has raised concerns regarding the potential to misuse AI-generated text (AIGT). It becomes increasingly critical to establish an excellent AIGT detection method with high generalization and robustness. However, existing methods either focus on model generalization or concentrate on robustness. The unified mechanism, to simultaneously address the challenges of generalization and robustness, is less explored. In this paper, we argue that robustness can be view as a specific form of domain shift, and empirically reveal an intrinsic mechanism for model generalization of AIGT detection task. Then, we proposed a novel AIGT detection method (DP-Net) via dynamic perturbations introduced by a reinforcement learning with elaborated reward and action. Experimentally, extensive results show that the proposed DP-Net significantly outperforms some state-of-the-art AIGT detection methods for generalization capacity in three cross-domain scenarios. Meanwhile, the DP-Net achieves best robustness under two text adversarial attacks. The code is publicly available at https://github.com/CAU-ISS-Lab/AIGT-Detection-Evade-Detection/tree/main/DP-Net.
BadApex: Backdoor Attack Based on Adaptive Optimization Mechanism of Black-box Large Language Models
Apr 21, 2025Previous insertion-based and paraphrase-based backdoors have achieved great success in attack efficacy, but they ignore the text quality and semantic consistency between poisoned and clean texts. Although recent studies introduce LLMs to generate poisoned texts and improve the stealthiness, semantic consistency, and text quality, their hand-crafted prompts rely on expert experiences, facing significant challenges in prompt adaptability and attack performance after defenses. In this paper, we propose a novel backdoor attack based on adaptive optimization mechanism of black-box large language models (BadApex), which leverages a black-box LLM to generate poisoned text through a refined prompt. Specifically, an Adaptive Optimization Mechanism is designed to refine an initial prompt iteratively using the generation and modification agents. The generation agent generates the poisoned text based on the initial prompt. Then the modification agent evaluates the quality of the poisoned text and refines a new prompt. After several iterations of the above process, the refined prompt is used to generate poisoned texts through LLMs. We conduct extensive experiments on three dataset with six backdoor attacks and two defenses. Extensive experimental results demonstrate that BadApex significantly outperforms state-of-the-art attacks. It improves prompt adaptability, semantic consistency, and text quality. Furthermore, when two defense methods are applied, the average attack success rate (ASR) still up to 96.75%.
MatIR: A Hybrid Mamba-Transformer Image Restoration Model
Jan 31, 2025



In recent years, Transformers-based models have made significant progress in the field of image restoration by leveraging their inherent ability to capture complex contextual features. Recently, Mamba models have made a splash in the field of computer vision due to their ability to handle long-range dependencies and their significant computational efficiency compared to Transformers. However, Mamba currently lags behind Transformers in contextual learning capabilities. To overcome the limitations of these two models, we propose a Mamba-Transformer hybrid image restoration model called MatIR. Specifically, MatIR cross-cycles the blocks of the Transformer layer and the Mamba layer to extract features, thereby taking full advantage of the advantages of the two architectures. In the Mamba module, we introduce the Image Inpainting State Space (IRSS) module, which traverses along four scan paths to achieve efficient processing of long sequence data. In the Transformer module, we combine triangular window-based local attention with channel-based global attention to effectively activate the attention mechanism over a wider range of image pixels. Extensive experimental results and ablation studies demonstrate the effectiveness of our approach.
Generative Text Steganography with Large Language Model
Apr 16, 2024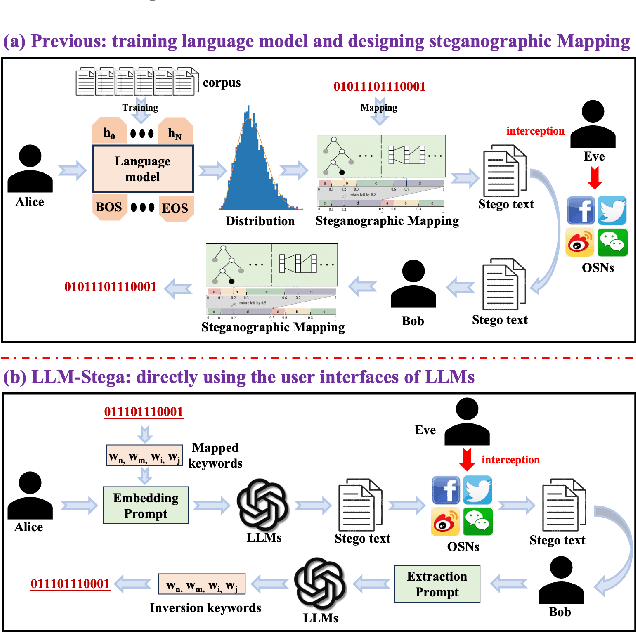
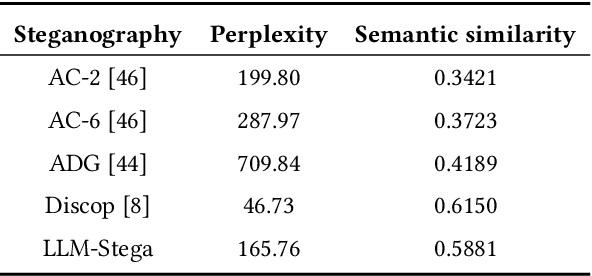
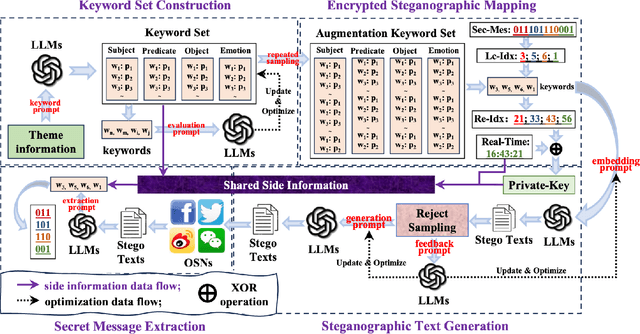
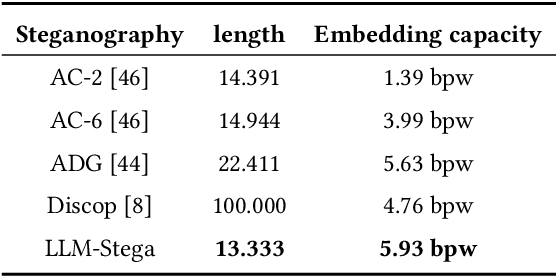
Recent advances in large language models (LLMs) have blurred the boundary of high-quality text generation between humans and machines, which is favorable for generative text steganography. While, current advanced steganographic mapping is not suitable for LLMs since most users are restricted to accessing only the black-box API or user interface of the LLMs, thereby lacking access to the training vocabulary and its sampling probabilities. In this paper, we explore a black-box generative text steganographic method based on the user interfaces of large language models, which is called LLM-Stega. The main goal of LLM-Stega is that the secure covert communication between Alice (sender) and Bob (receiver) is conducted by using the user interfaces of LLMs. Specifically, We first construct a keyword set and design a new encrypted steganographic mapping to embed secret messages. Furthermore, to guarantee accurate extraction of secret messages and rich semantics of generated stego texts, an optimization mechanism based on reject sampling is proposed. Comprehensive experiments demonstrate that the proposed LLM-Stega outperforms current state-of-the-art methods.
Empowering Image Recovery_ A Multi-Attention Approach
Apr 09, 2024We propose Diverse Restormer (DART), a novel image restoration method that effectively integrates information from various sources (long sequences, local and global regions, feature dimensions, and positional dimensions) to address restoration challenges. While Transformer models have demonstrated excellent performance in image restoration due to their self-attention mechanism, they face limitations in complex scenarios. Leveraging recent advancements in Transformers and various attention mechanisms, our method utilizes customized attention mechanisms to enhance overall performance. DART, our novel network architecture, employs windowed attention to mimic the selective focusing mechanism of human eyes. By dynamically adjusting receptive fields, it optimally captures the fundamental features crucial for image resolution reconstruction. Efficiency and performance balance are achieved through the LongIR attention mechanism for long sequence image restoration. Integration of attention mechanisms across feature and positional dimensions further enhances the recovery of fine details. Evaluation across five restoration tasks consistently positions DART at the forefront. Upon acceptance, we commit to providing publicly accessible code and models to ensure reproducibility and facilitate further research.
When Super-Resolution Meets Camouflaged Object Detection: A Comparison Study
Aug 08, 2023



Super Resolution (SR) and Camouflaged Object Detection (COD) are two hot topics in computer vision with various joint applications. For instance, low-resolution surveillance images can be successively processed by super-resolution techniques and camouflaged object detection. However, in previous work, these two areas are always studied in isolation. In this paper, we, for the first time, conduct an integrated comparative evaluation for both. Specifically, we benchmark different super-resolution methods on commonly used COD datasets, and meanwhile, we evaluate the robustness of different COD models by using COD data processed by SR methods. Our goal is to bridge these two domains, discover novel experimental phenomena, summarize new experim.