 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysInOne: Visual Physics Learning and Reasoning in One Suite
Apr 10, 2026We present PhysInOne, a large-scale synthetic dataset addressing the critical scarcity of physically-grounded training data for AI systems. Unlike existing datasets limited to merely hundreds or thousands of examples, PhysInOne provides 2 million videos across 153,810 dynamic 3D scenes, covering 71 basic physical phenomena in mechanics, optics, fluid dynamics, and magnetism. Distinct from previous works, our scenes feature multiobject interactions against complex backgrounds, with comprehensive ground-truth annotations including 3D geometry, semantics, dynamic motion, physical properties, and text descriptions. We demonstrate PhysInOne's efficacy across four emerging applications: physics-aware video generation, long-/short-term future frame prediction, physical property estimation, and motion transfer. Experiments show that fine-tuning foundation models on PhysInOne significantly enhances physical plausibility, while also exposing critical gaps in modeling complex physical dynamics and estimating intrinsic properties. As the largest dataset of its kind, orders of magnitude beyond prior works, PhysInOne establishes a new benchmark for advancing physics-grounded world models in generation, simulation, and embodied AI.
Inversion of Arctic dual-channel sound speed profile based on random airgun signal
Aug 13, 2025For the unique dual-channel sound speed profiles of the Canadian Basin and the Chukchi Plateau in the Arctic, based on the propagation characteristics of refracted normal modes under dual-channel sound speed profiles, an inversion method using refracted normal modes for dual-channel sound speed profiles is proposed. This method proposes a dual-parameter representation method for dual-channel sound speed profiles, tailored to the characteristics of dual-channel sound speed profiles. A dispersion structure extraction method is proposed for the dispersion structure characteristics of refracted normal modes under dual-channel sound speed profiles. Combining the parameter representation method of sound speed profiles and the dispersion structure extraction method, an inversion method for dual-channel sound speed profiles is proposed. For the common horizontal variation of sound speed profiles in long-distance acoustic propagation, a method for inverting horizontally varying dual-channel sound speed profiles is proposed. Finally, this article verifies the effectiveness of the dual-channel sound speed profile inversion method using the Arctic low-frequency long-range acoustic propagation experiment. Compared with previous sound speed profile inversion methods, the method proposed in this article has the advantages of fewer inversion parameters and faster inversion speed. It can be implemented using only a single hydrophone passively receiving random air gun signals, and it also solves the inversion problem of horizontal variation of sound speed profiles. It has significant advantages such as low cost, easy deployment, and fast computation speed.
Acoustic source depth estimation method based on a single hydrophone in Arctic underwater
Aug 13, 2025Based on the normal mode and ray theory, this article discusses the characteristics of surface sound source and reception at the surface layer, and explores depth estimation methods based on normal modes and rays, and proposes a depth estimation method based on the upper limit of modal frequency. Data verification is conducted to discuss the applicability and limitations of different methods. For the surface refracted normal mode waveguide, modes can be separated through warping transformation. Based on the characteristics of normal mode amplitude variation with frequency and number, the sound source depth can be estimated by matching amplitude information. Based on the spatial variation characteristics of eigenfunctions with frequency, a sound source depth estimation method matching the cutoff frequency of normal modes is proposed. For the deep Arctic sea, the sound ray arrival structure at the receiving end is obtained through the analysis of deep inversion sound ray trajectories, and the sound source depth can be estimated by matching the time difference of ray arrivals. Experimental data is used to verify the sound field patterns and the effectiveness of the sound source depth estimation method.
LogoSP: Local-global Grouping of Superpoints for Unsupervised Semantic Segmentation of 3D Point Clouds
Jun 09, 2025We study the problem of unsupervised 3D semantic segmentation on raw point clouds without needing human labels in training. Existing methods usually formulate this problem into learning per-point local features followed by a simple grouping strategy, lacking the ability to discover additional and possibly richer semantic priors beyond local features. In this paper, we introduce LogoSP to learn 3D semantics from both local and global point features. The key to our approach is to discover 3D semantic information by grouping superpoints according to their global patterns in the frequency domain, thus generating highly accurate semantic pseudo-labels for training a segmentation network. Extensive experiments on two indoor and an outdoor datasets show that our LogoSP surpasses all existing unsupervised methods by large margins, achieving the state-of-the-art performance for unsupervised 3D semantic segmentation. Notably, our investigation into the learned global patterns reveals that they truly represent meaningful 3D semantics in the absence of human labels during training.
GrabS: Generative Embodied Agent for 3D Object Segmentation without Scene Supervision
Apr 16, 2025



We study the hard problem of 3D object segmentation in complex point clouds without requiring human labels of 3D scenes for supervision. By relying on the similarity of pretrained 2D features or external signals such as motion to group 3D points as objects, existing unsupervised methods are usually limited to identifying simple objects like cars or their segmented objects are often inferior due to the lack of objectness in pretrained features. In this paper, we propose a new two-stage pipeline called GrabS. The core concept of our method is to learn generative and discriminative object-centric priors as a foundation from object datasets in the first stage, and then design an embodied agent to learn to discover multiple objects by querying against the pretrained generative priors in the second stage. We extensively evaluate our method on two real-world datasets and a newly created synthetic dataset, demonstrating remarkable segmentation performance, clearly surpassing all existing unsupervised methods.
Research and experimental verification on low-frequency long-range underwater sound propagation dispersion characteristics under dual-channel sound speed profiles in the Chukchi Plateau
Nov 13, 2023The dual-channel sound speed profiles of the Chukchi Plateau and the Canadian Basin have become current research hotspots due to their excellent low-frequency sound signal propagation ability. Previous research has mainly focused on using sound propagation theory to explain the changes in sound signal energy. This article is mainly based on the theory of normal modes to study the fine structure of low-frequency wide-band sound propagation dispersion under dual-channel sound speed profiles. In this paper, the problem of the intersection of normal mode dispersion curves caused by the dual-channel sound speed profile (SSP) has been explained, the blocking effect of seabed terrain changes on dispersion structures has been analyzed, and the normal modes has been separated by using modified warping operator. The above research results have been verified through a long-range seismic exploration experiment at the Chukchi Plateau. At the same time, based on the acoustic signal characteristics in this environment, two methods for estimating the distance of sound sources have been proposed, and the experiment data at sea has also verified these two methods.
TransGrasp: Grasp Pose Estimation of a Category of Objects by Transferring Grasps from Only One Labeled Instance
Jul 25, 2022

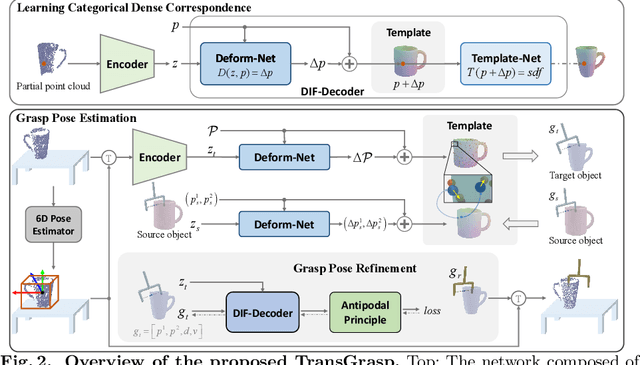

Grasp pose estimation is an important issue for robots to interact with the real world. However, most of existing methods require exact 3D object models available beforehand or a large amount of grasp annotations for training. To avoid these problems, we propose TransGrasp, a category-level grasp pose estimation method that predicts grasp poses of a category of objects by labeling only one object instance. Specifically, we perform grasp pose transfer across a category of objects based on their shape correspondences and propose a grasp pose refinement module to further fine-tune grasp pose of grippers so as to ensure successful grasps. Experiments demonstrate the effectiveness of our method on achieving high-quality grasps with the transferred grasp poses. Our code is available at https://github.com/yanjh97/TransGrasp.