 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedMCP-Calc: Benchmarking LLMs for Realistic Medical Calculator Scenarios via MCP Integration
Jan 30, 2026Medical calculators are fundamental to quantitative, evidence-based clinical practice. However, their real-world use is an adaptive, multi-stage process, requiring proactive EHR data acquisition, scenario-dependent calculator selection, and multi-step computation, whereas current benchmarks focus only on static single-step calculations with explicit instructions. To address these limitations, we introduce MedMCP-Calc, the first benchmark for evaluating LLMs in realistic medical calculator scenarios through Model Context Protocol (MCP) integration. MedMCP-Calc comprises 118 scenario tasks across 4 clinical domains, featuring fuzzy task descriptions mimicking natural queries, structured EHR database interaction, external reference retrieval, and process-level evaluation. Our evaluation of 23 leading models reveals critical limitations: even top performers like Claude Opus 4.5 exhibit substantial gaps, including difficulty selecting appropriate calculators for end-to-end workflows given fuzzy queries, poor performance in iterative SQL-based database interactions, and marked reluctance to leverage external tools for numerical computation. Performance also varies considerably across clinical domains. Building on these findings, we develop CalcMate, a fine-tuned model incorporating scenario planning and tool augmentation, achieving state-of-the-art performance among open-source models. Benchmark and Codes are available in https://github.com/SPIRAL-MED/MedMCP-Calc.
MedCEG: Reinforcing Verifiable Medical Reasoning with Critical Evidence Graph
Dec 15, 2025Large language models with reasoning capabilities have demonstrated impressive performance across a wide range of domains. In clinical applications, a transparent, step-by-step reasoning process provides physicians with strong evidence to support decision-making. While reinforcement learning has effectively enhanced reasoning performance in medical contexts, the clinical reliability of these reasoning processes remains limited because their accuracy and validity are often overlooked during training. To address this gap, we propose MedCEG, a framework that augments medical language models with clinically valid reasoning pathways by explicitly supervising the reasoning process through a Critical Evidence Graph (CEG). We curate a dataset of challenging clinical cases and algorithmically construct a CEG for each sample to represent a high-quality verifiable reasoning pathway. To guide the reasoning process, we introduce a Clinical Reasoning Procedure Reward, which evaluates Node Coverage, Structural Correctness, and Chain Completeness, thereby providing a holistic assessment of reasoning quality. Experimental results show that MedCEG surpasses existing methods in performance while producing clinically valid reasoning chains, representing a solid advancement in reliable medical AI reasoning. The code and models are available at https://github.com/LinjieMu/MedCEG.
CP-Env: Evaluating Large Language Models on Clinical Pathways in a Controllable Hospital Environment
Dec 12, 2025Medical care follows complex clinical pathways that extend beyond isolated physician-patient encounters, emphasizing decision-making and transitions between different stages. Current benchmarks focusing on static exams or isolated dialogues inadequately evaluate large language models (LLMs) in dynamic clinical scenarios. We introduce CP-Env, a controllable agentic hospital environment designed to evaluate LLMs across end-to-end clinical pathways. CP-Env simulates a hospital ecosystem with patient and physician agents, constructing scenarios ranging from triage and specialist consultation to diagnostic testing and multidisciplinary team meetings for agent interaction. Following real hospital adaptive flow of healthcare, it enables branching, long-horizon task execution. We propose a three-tiered evaluation framework encompassing Clinical Efficacy, Process Competency, and Professional Ethics. Results reveal that most models struggle with pathway complexity, exhibiting hallucinations and losing critical diagnostic details. Interestingly, excessive reasoning steps can sometimes prove counterproductive, while top models tend to exhibit reduced tool dependency through internalized knowledge. CP-Env advances medical AI agents development through comprehensive end-to-end clinical evaluation. We provide the benchmark and evaluation tools for further research and development at https://github.com/SPIRAL-MED/CP_ENV.
Elicit and Enhance: Advancing Multimodal Reasoning in Medical Scenarios
May 29, 2025Effective clinical decision-making depends on iterative, multimodal reasoning across diverse sources of evidence. The recent emergence of multimodal reasoning models has significantly transformed the landscape of solving complex tasks. Although such models have achieved notable success in mathematics and science, their application to medical domains remains underexplored. In this work, we propose \textit{MedE$^2$}, a two-stage post-training pipeline that elicits and then enhances multimodal reasoning for medical domains. In Stage-I, we fine-tune models using 2,000 text-only data samples containing precisely orchestrated reasoning demonstrations to elicit reasoning behaviors. In Stage-II, we further enhance the model's reasoning capabilities using 1,500 rigorously curated multimodal medical cases, aligning model reasoning outputs with our proposed multimodal medical reasoning preference. Extensive experiments demonstrate the efficacy and reliability of \textit{MedE$^2$} in improving the reasoning performance of medical multimodal models. Notably, models trained with \textit{MedE$^2$} consistently outperform baselines across multiple medical multimodal benchmarks. Additional validation on larger models and under inference-time scaling further confirms the robustness and practical utility of our approach.
DiagnosisArena: Benchmarking Diagnostic Reasoning for Large Language Models
May 20, 2025The emergence of groundbreaking large language models capable of performing complex reasoning tasks holds significant promise for addressing various scientific challenges, including those arising in complex clinical scenarios. To enable their safe and effective deployment in real-world healthcare settings, it is urgently necessary to benchmark the diagnostic capabilities of current models systematically. Given the limitations of existing medical benchmarks in evaluating advanced diagnostic reasoning, we present DiagnosisArena, a comprehensive and challenging benchmark designed to rigorously assess professional-level diagnostic competence. DiagnosisArena consists of 1,113 pairs of segmented patient cases and corresponding diagnoses, spanning 28 medical specialties, deriving from clinical case reports published in 10 top-tier medical journals. The benchmark is developed through a meticulous construction pipeline, involving multiple rounds of screening and review by both AI systems and human experts, with thorough checks conducted to prevent data leakage. Our study reveals that even the most advanced reasoning models, o3-mini, o1, and DeepSeek-R1, achieve only 45.82%, 31.09%, and 17.79% accuracy, respectively. This finding highlights a significant generalization bottleneck in current large language models when faced with clinical diagnostic reasoning challenges. Through DiagnosisArena, we aim to drive further advancements in AIs diagnostic reasoning capabilities, enabling more effective solutions for real-world clinical diagnostic challenges. We provide the benchmark and evaluation tools for further research and development https://github.com/SPIRAL-MED/DiagnosisArena.
MMXU: A Multi-Modal and Multi-X-ray Understanding Dataset for Disease Progression
Feb 17, 2025Large vision-language models (LVLMs) have shown great promise in medical applications, particularly in visual question answering (MedVQA) and diagnosis from medical images. However, existing datasets and models often fail to consider critical aspects of medical diagnostics, such as the integration of historical records and the analysis of disease progression over time. In this paper, we introduce MMXU (Multimodal and MultiX-ray Understanding), a novel dataset for MedVQA that focuses on identifying changes in specific regions between two patient visits. Unlike previous datasets that primarily address single-image questions, MMXU enables multi-image questions, incorporating both current and historical patient data. We demonstrate the limitations of current LVLMs in identifying disease progression on MMXU-\textit{test}, even those that perform well on traditional benchmarks. To address this, we propose a MedRecord-Augmented Generation (MAG) approach, incorporating both global and regional historical records. Our experiments show that integrating historical records significantly enhances diagnostic accuracy by at least 20\%, bridging the gap between current LVLMs and human expert performance. Additionally, we fine-tune models with MAG on MMXU-\textit{dev}, which demonstrates notable improvements. We hope this work could illuminate the avenue of advancing the use of LVLMs in medical diagnostics by emphasizing the importance of historical context in interpreting medical images. Our dataset is released at \href{https://github.com/linjiemu/MMXU}{https://github.com/linjiemu/MMXU}.
MeNTi: Bridging Medical Calculator and LLM Agent with Nested Tool Calling
Oct 17, 2024
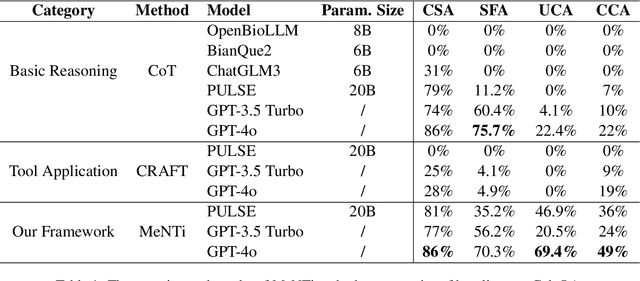
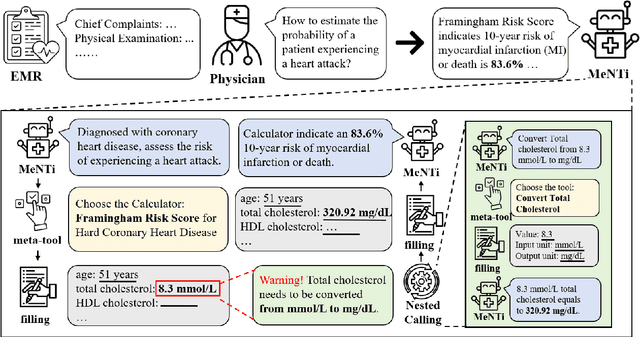
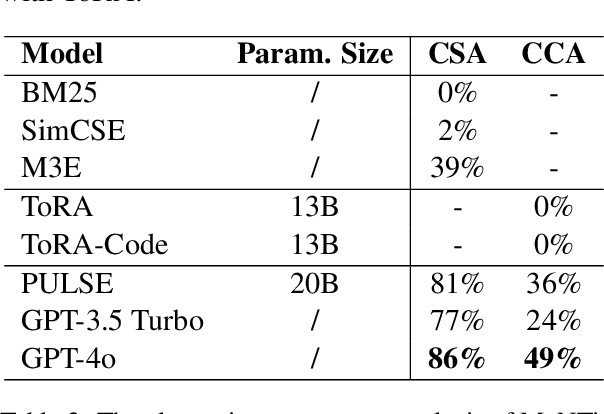
Integrating tools into Large Language Models (LLMs) has facilitated the widespread application. Despite this, in specialized downstream task contexts, reliance solely on tools is insufficient to fully address the complexities of the real world. This particularly restricts the effective deployment of LLMs in fields such as medicine. In this paper, we focus on the downstream tasks of medical calculators, which use standardized tests to assess an individual's health status. We introduce MeNTi, a universal agent architecture for LLMs. MeNTi integrates a specialized medical toolkit and employs meta-tool and nested calling mechanisms to enhance LLM tool utilization. Specifically, it achieves flexible tool selection and nested tool calling to address practical issues faced in intricate medical scenarios, including calculator selection, slot filling, and unit conversion. To assess the capabilities of LLMs for quantitative assessment throughout the clinical process of calculator scenarios, we introduce CalcQA. This benchmark requires LLMs to use medical calculators to perform calculations and assess patient health status. CalcQA is constructed by professional physicians and includes 100 case-calculator pairs, complemented by a toolkit of 281 medical tools. The experimental results demonstrate significant performance improvements with our framework. This research paves new directions for applying LLMs in demanding scenarios of medicine.