 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychēChat: An Empathic Framework Focused on Emotion Shift Tracking and Safety Risk Analysis in Psychological Counseling
Jan 18, 2026Large language models (LLMs) have demonstrated notable advancements in psychological counseling. However, existing models generally do not explicitly model seekers' emotion shifts across counseling sessions, a core focus in classical psychological schools. Moreover, how to align counselor models' responses with these emotion shifts while proactively mitigating safety risks remains underexplored. To bridge these gaps, we propose PsychēChat, which explicitly integrates emotion shift tracking and safety risk analysis for psychological counseling. Specifically, we employ interactive role-playing to synthesize counselor--seeker dialogues, incorporating two modules: Emotion Management Module, to capture seekers' current emotions and emotion shifts; and Risk Control Module, to anticipate seekers' subsequent reactions and identify potential risks. Furthermore, we introduce two modeling paradigms. The Agent Mode structures emotion management, risk control, and counselor responses into a collaborative multi-agent pipeline. The LLM Mode integrates these stages into a unified chain-of-thought for end-to-end inference, balancing efficiency and performance. Extensive experiments, including interactive scoring, dialogue-level evaluation, and human assessment, demonstrate that PsychēChat outperforms existing methods for emotional insight and safety control.
Rank4Gen: RAG-Preference-Aligned Document Set Selection and Ranking
Jan 16, 2026In the RAG paradigm, the information retrieval module provides context for generators by retrieving and ranking multiple documents to support the aggregation of evidence. However, existing ranking models are primarily optimized for query--document relevance, which often misaligns with generators' preferences for evidence selection and citation, limiting their impact on response quality. Moreover, most approaches do not account for preference differences across generators, resulting in unstable cross-generator performance. We propose \textbf{Rank4Gen}, a generator-aware ranker for RAG that targets the goal of \emph{Ranking for Generators}. Rank4Gen introduces two key preference modeling strategies: (1) \textbf{From Ranking Relevance to Response Quality}, which optimizes ranking with respect to downstream response quality rather than query--document relevance; and (2) \textbf{Generator-Specific Preference Modeling}, which conditions a single ranker on different generators to capture their distinct ranking preferences. To enable such modeling, we construct \textbf{PRISM}, a dataset built from multiple open-source corpora and diverse downstream generators. Experiments on five challenging and recent RAG benchmarks demonstrate that RRank4Gen achieves strong and competitive performance for complex evidence composition in RAG.
MinosEval: Distinguishing Factoid and Non-Factoid for Tailored Open-Ended QA Evaluation with LLMs
Jun 18, 2025Open-ended question answering (QA) is a key task for evaluating the capabilities of large language models (LLMs). Compared to closed-ended QA, it demands longer answer statements, more nuanced reasoning processes, and diverse expressions, making refined and interpretable automatic evaluation both crucial and challenging. Traditional metrics like ROUGE and BERTScore struggle to capture semantic similarities due to different patterns between model responses and reference answers. Current LLM-based evaluation approaches, such as pairwise or listwise comparisons of candidate answers, lack intuitive interpretability. While pointwise scoring of each response provides some descriptions, it fails to adapt across different question contents. Most notably, existing methods overlook the distinction between factoid and non-factoid questions. To address these challenges, we propose \textbf{MinosEval}, a novel evaluation method that first distinguishes open-ended questions and then ranks candidate answers using different evaluation strategies. For factoid questions, it applies an adaptive key-point scoring strategy, while for non-factoid questions, it uses an instance-aware listwise ranking strategy. Experiments on multiple open-ended QA datasets, including self-built ones with more candidate responses to complement community resources, show that MinosEval better aligns with human annotations and offers more interpretable results.
CMQCIC-Bench: A Chinese Benchmark for Evaluating Large Language Models in Medical Quality Control Indicator Calculation
Feb 17, 2025Medical quality control indicators are essential to assess the qualifications of healthcare institutions for medical services. With the impressive performance of large language models (LLMs) like GPT-4 in the medical field, leveraging these technologies for the Medical Quality Control Indicator Calculation (MQCIC) presents a promising approach. In this work, (1) we introduce a real-world task MQCIC and propose an open-source Chinese electronic medical records (EMRs)-based dataset (CMQCIC-Bench) comprising 785 instances and 76 indicators. (2) We propose a semi-automatic method to enhance the rule representation. Then we propose the Clinical Facts-based Inferential Rule (CF-IR) method that disentangles the clinical fact verification and inferential rule reasoning actions. (3) We conduct comprehensive experiments on 20 representative LLMs, covering general and medical models. Our findings reveal that CF-IR outperforms Chain-of-Thought methods in MQCIC tasks. (4) We conduct an error analysis and investigate the capabilities of clinical fact verification and inferential rule reasoning, providing insights to improve performance in the MQCIC further. The dataset and code is available in this repo https://anonymous.4open.science/r/C-MQCIC-1151.
MSDiagnosis: An EMR-based Dataset for Clinical Multi-Step Diagnosis
Aug 19, 2024



Clinical diagnosis is critical in medical practice, typically requiring a continuous and evolving process that includes primary diagnosis, differential diagnosis, and final diagnosis. However, most existing clinical diagnostic tasks are single-step processes, which does not align with the complex multi-step diagnostic procedures found in real-world clinical settings. In this paper, we propose a multi-step diagnostic task and annotate a clinical diagnostic dataset (MSDiagnosis). This dataset includes primary diagnosis, differential diagnosis, and final diagnosis questions. Additionally, we propose a novel and effective framework. This framework combines forward inference, backward inference, reflection, and refinement, enabling the LLM to self-evaluate and adjust its diagnostic results. To assess the effectiveness of our proposed method, we design and conduct extensive experiments. The experimental results demonstrate the effectiveness of the proposed method. We also provide a comprehensive experimental analysis and suggest future research directions for this task.
MedOdyssey: A Medical Domain Benchmark for Long Context Evaluation Up to 200K Tokens
Jun 21, 2024Numerous advanced Large Language Models (LLMs) now support context lengths up to 128K, and some extend to 200K. Some benchmarks in the generic domain have also followed up on evaluating long-context capabilities. In the medical domain, tasks are distinctive due to the unique contexts and need for domain expertise, necessitating further evaluation. However, despite the frequent presence of long texts in medical scenarios, evaluation benchmarks of long-context capabilities for LLMs in this field are still rare. In this paper, we propose MedOdyssey, the first medical long-context benchmark with seven length levels ranging from 4K to 200K tokens. MedOdyssey consists of two primary components: the medical-context "needles in a haystack" task and a series of tasks specific to medical applications, together comprising 10 datasets. The first component includes challenges such as counter-intuitive reasoning and novel (unknown) facts injection to mitigate knowledge leakage and data contamination of LLMs. The second component confronts the challenge of requiring professional medical expertise. Especially, we design the ``Maximum Identical Context'' principle to improve fairness by guaranteeing that different LLMs observe as many identical contexts as possible. Our experiment evaluates advanced proprietary and open-source LLMs tailored for processing long contexts and presents detailed performance analyses. This highlights that LLMs still face challenges and need for further research in this area. Our code and data are released in the repository: \url{https://github.com/JOHNNY-fans/MedOdyssey.}
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Apr 27, 2024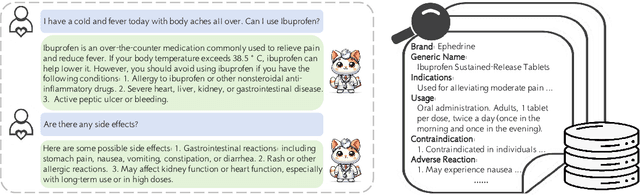

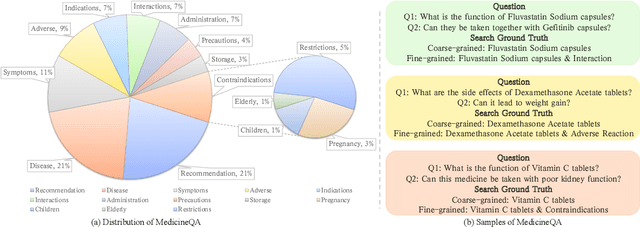
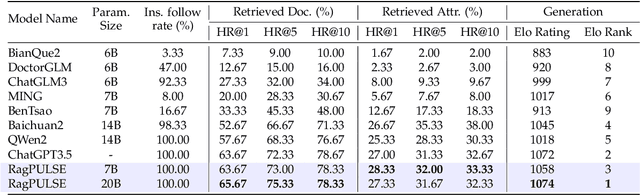
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new \textit{Distill-Retrieve-Read} framework instead of the previous \textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.