 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Apr 27, 2024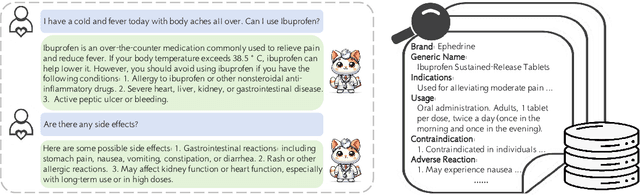

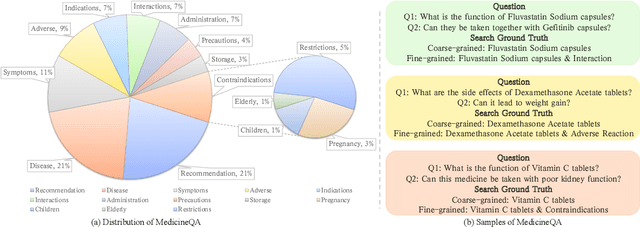
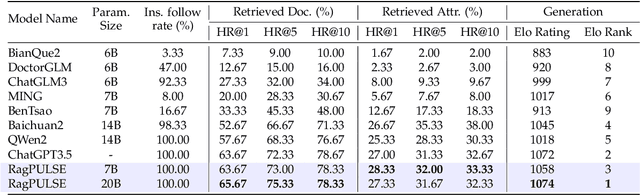
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new \textit{Distill-Retrieve-Read} framework instead of the previous \textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
Indexing of CNN Features for Large Scale Image Search
Feb 01, 2018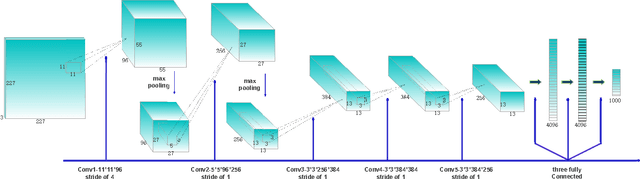
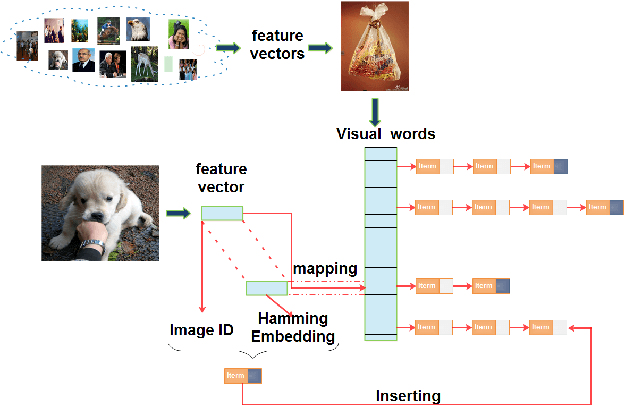
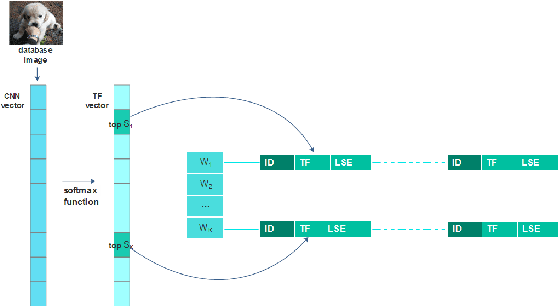
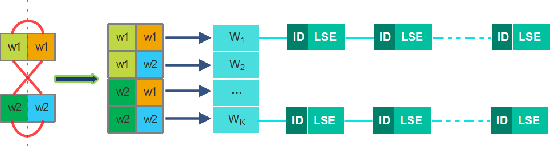
The convolutional neural network (CNN) features can give a good description of image content, which usually represent images with unique global vectors. Although they are compact compared to local descriptors, they still cannot efficiently deal with large-scale image retrieval due to the cost of the linear incremental computation and storage. To address this issue, we build a simple but effective indexing framework based on inverted table, which significantly decreases both the search time and memory usage. In addition, several strategies are fully investigated under an indexing framework to adapt it to CNN features and compensate for quantization errors. First, we use multiple assignment for the query and database images to increase the probability of relevant images' co-existing in the same Voronoi cells obtained via the clustering algorithm. Then, we introduce embedding codes to further improve precision by removing false matches during a search. We demonstrate that by using hashing schemes to calculate the embedding codes and by changing the ranking rule, indexing framework speeds can be greatly improved. Extensive experiments conducted on several unsupervised and supervised benchmarks support these results and the superiority of the proposed indexing framework. We also provide a fair comparison between the popular CNN features.
A New Evaluation Protocol and Benchmarking Results for Extendable Cross-media Retrieval
Mar 10, 2017
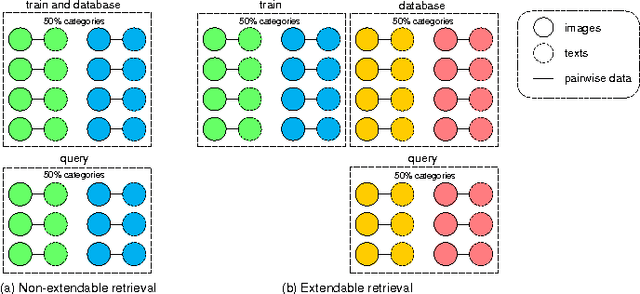


This paper proposes a new evaluation protocol for cross-media retrieval which better fits the real-word applications. Both image-text and text-image retrieval modes are considered. Traditionally, class labels in the training and testing sets are identical. That is, it is usually assumed that the query falls into some pre-defined classes. However, in practice, the content of a query image/text may vary extensively, and the retrieval system does not necessarily know in advance the class label of a query. Considering the inconsistency between the real-world applications and laboratory assumptions, we think that the existing protocol that works under identical train/test classes can be modified and improved. This work is dedicated to addressing this problem by considering the protocol under an extendable scenario, \ie, the training and testing classes do not overlap. We provide extensive benchmarking results obtained by the existing protocol and the proposed new protocol on several commonly used datasets. We demonstrate a noticeable performance drop when the testing classes are unseen during training. Additionally, a trivial solution, \ie, directly using the predicted class label for cross-media retrieval, is tested. We show that the trivial solution is very competitive in traditional non-extendable retrieval, but becomes less so under the new settings. The train/test split, evaluation code, and benchmarking results are publicly available on our website.